Jiahemekang Launches Advanced Big Data Clinical Research Platform Tailored for Physicians
Redundant data collection and low utilization rate;
Data storage is fragmented and lacks a uniform structure;
Lack of unified monitoring for data quality and completeness;
Complex data query logic;
Difficulties in Phased Validation of Medical Research;
Research ideas are difficult to uncover...
There are many other clinical research questions similar to those mentioned above. Ultimately, improving the quality of medical data is the key to solving these problems.
Currently, patient medical records are stored in an unstructured or semi-structured format in the vast majority of hospitals. This makes it difficult for physicians to directly utilize the information, forcing them to organize data through manual transcription or excerpting, which significantly increases the time cost of research data collection.
Furthermore, research data often originate from multiple operational systems, depending on the specific objectives of the study. Moreover, data categories are diverse, varying by treatment modality and phase, and include patient follow-up records, Case Report Forms (CRFs), biospecimens, and omics analysis data. Consequently, physicians must frequently switch between multiple systems during actual data collection and organization, manually linking and verifying data from disparate sources, which significantly increases the cost of errors.
In addition, contemporary physicians are also troubled by how to initiate scientific research projects and how to develop innovative research concepts and perspectives.
In light of the aforementioned issues, big data–based research platforms have gradually demonstrated their significant role and advantages in the development of research-oriented hospitals, and have also become a new focal point in recent years for novel big data–driven models of clinical research.
From Clinical Systems to Big Data Platforms for Scientific Research
Big data platforms are typically built on Hadoop technology to achieve standardized storage of massive heterogeneous data, including unstructured electronic medical record (EMR) data and large-scale imaging data. They also leverage technologies such as natural language processing (NLP) to standardize and normalize this data. Furthermore, the medical data aggregated by these big data platforms provides extensive training and validation datasets for deep learning and other methods, thereby advancing the development of intelligent analysis of medical data.
The currently trending natural language processing of medical record data and AI analysis of medical imaging are both based on big data platforms.
As a representative enterprise in China’s electronic medical record (EMR) sector, Jiahua Meikang embarked on the research, development, and exploration of big data platforms in 2013. After several years of accumulation, the company has gradually achieved mature application of big data-related technologies, including Hadoop, Spark, and machine learning. Furthermore, its extensive experience from previous clinical system projects, such as EMR implementations, has laid a solid foundation for the establishment of its big data models.
In 2017, driven by the increasingly strong demand for scientific research among hospital physicians, Jiahewei Kang’s Big Data Division officially launched its Big Data Clinical Research Platform.

Image provided by Jiahe Meikang
According to VCBeat, the platform primarily leverages technologies such as big data processing, natural language tokenization, machine learning, and knowledge graphs to integrate and mine vast amounts of medical data—including electronic health records (EHRs), laboratory tests, medical imaging, and genomic sequences—thereby establishing a patient-centric, comprehensive time-series research repository. Furthermore, the platform employs data mining algorithms to achieve in-depth analysis and visualization of clinical data, assisting clinicians in generating research ideas and formulating etiological hypotheses.
In terms of efficiency, the big data clinical research platform, based on large-sample clinical trials, can rapidly validate hypotheses and generate statistical results, thereby reducing research costs, enhancing the quality of services provided by medical institutions, and improving the efficiency of translating research findings into practical applications.
Five Key Advantages
Big Data Clinical Research Platforms are not uncommon in China. Leveraging years of expertise in the in-depth analysis of clinical data, the Big Data Division of Jiahao Health has established five key product advantages:
Jiahe Meikang’s Big Data Division has developed a “Multi-Level Data Stratification Model” for its Big Data Clinical Research Platform to address the complex hierarchical structure of clinical data, particularly medical records and examination reports. This model enables deep mining of data at each level, achieves extreme data granularity, and establishes hierarchical relationships, thereby supporting in-depth scientific research applications such as complex correlation analysis.
According to Gan Wei, Director of the Research and Product Department at Jiahe Meikang’s Big Data Division, “The advantage of data granularity in the multi-level data stratification model is primarily based on the structural complexity of medical records. After years of developing electronic medical record (EMR) systems, Jiahe Meikang’s system now covers more than 1,200 hospitals across China, enabling a profound understanding of medical records. Therefore, our data analysis is more detailed and features finer granularity compared to other companies.”
For example, if a physician wishes to investigate the impact of alcohol consumption on a specific disease, the first level of analysis involves determining whether the patient consumes alcohol; the second level examines the duration of their drinking history; and the third level investigates the type of alcohol consumed, such as red wine, baijiu (Chinese white spirit), or other varieties. The finer the granularity of the differential analysis regarding the disease, the more in-depth the physician’s research becomes.
Jiahe Meikang’s Big Data Division has developed a Disease-Specific Database within its Big Data Clinical Research Platform. Centered on specialty diseases, this database integrates various clinical diagnosis and treatment records generated during patients’ hospital stays—including outpatient and emergency care—such as medical records, laboratory and imaging tests, physician orders and medications, anesthesia and surgery records, and nursing documentation.
In addition, patient follow-up data, biospecimen data, omics research data, publicly available environmental quality data, as well as self-maintained project database data and disease-specific label data, are also incorporated into the disease-specific registry.
Based on disease-specific databases, principal investigators (PIs) no longer need to spend considerable time and effort taking graduate students to the medical records department to manually review paper charts and extract key information, as was previously required.
Moreover, physicians’ clinical perspectives are often constrained by their prior experience, limiting the scope of identifiable clinical issues. However, with access to disease-specific databases built on multidisciplinary data, they can leverage research platforms to conduct multidimensional analyses of large-scale datasets. Through visualization tools, physicians can uncover previously elusive clinical problems and identify new avenues for scientific research.
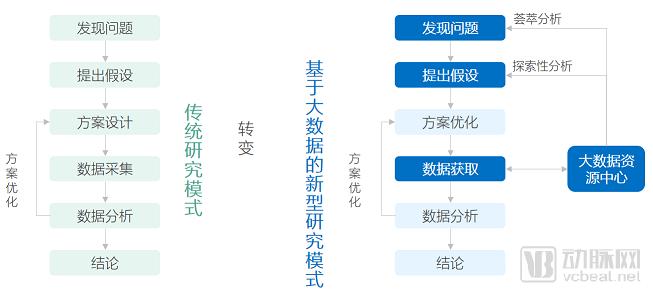
Image provided by Jiahua Meikang
Evaluating the quality of a medical record often requires approaching it from two perspectives: formally, it must ensure completeness, timeliness, and standardized formatting; substantively, it demands accurate and detailed content that supports critical analysis and academic discussion.
In the past, hospitals predominantly relied on manual methods for medical record quality control. For instance, a tertiary Grade A hospital recruited more than 30 senior clinical experts to form a specialized team for in-depth quality assessment of medical records. Additionally, dozens of department directors, professors, and attending physicians conducted monthly self-inspections of medical records within their respective departments.
Intelligent Quality Control refers to the process of defining common quality control rules and then leveraging machine learning to supplement and refine the quality control system. The Big Data Division of Jiahe Meikang implements real-time, multi-level quality monitoring for each data item in its big data repository, covering aspects such as data completeness, anomalous data points, abnormal data types, and data distribution patterns. Furthermore, it enables traceability analysis for non-standardized data by tracing back to the original medical record documents to identify documentation errors. Examples include discrepancies between admission and discharge scores, or inconsistencies between confirmed diagnoses and patient symptoms.
According to Gan Wei, “On one hand, physicians can gain a clear overview of the quality of required data; on the other hand, they can promptly identify issues and implement measures such as training and mandatory fields to standardize medical record documentation, thereby improving data quality at its source.”
The data deep mining capabilities of the Big Data Clinical Research Platform, offered by the Big Data Division of Jiahe Meikang, feature two key characteristics: disease-specific analysis and online statistical modeling.
1) Disease Analysis
Disease-Specific Analysis provides analytical research on three core themes: analysis of influencing factors, predictive analysis, and intervention analysis.
Analysis of Influencing Factors: Analyze and mine thousands of disease-specific dimensions to identify risk factors, followed by classification and ranking. This approach not only facilitates correlation analysis of the disease but also uncovers key factors affecting operational metrics such as average length of stay, thereby enabling precise identification of relevant business processes for targeted interventions.
Predictive Analytics: By analyzing real-world medical records and leveraging big data mining techniques such as time series analysis and neural networks, disease prediction models are constructed to predict risk factors for patient-related diseases, classify disease severity, and evaluate treatment efficacy. Additionally, it supports forecasting of outpatient visits, hospital admissions, surgeries, and associated costs, providing references for hospital operational management.
Intervention Analysis: Conduct comparative analyses before and after key events for treatment modalities such as medication, surgery, and radiotherapy, thereby directly generating reports on comparative treatment outcomes.
2) Online Statistical Modeling
In the past, before writing scientific research papers, physicians had to convert data from Excel spreadsheets into formats compatible with statistical software. This process was time-consuming, involving data transformation, handling of missing values, and addressing data irregularities. With the use of a scientific research platform, physicians no longer need to follow the previous cumbersome workflow; they can simply process and quantify their data through the platform into the required format for statistical analysis.
In terms of data statistics, the Big Data Division of Jiahe Meikang also provides online statistical modeling tools.
Currently, the research platform has integrated more than 40 statistical algorithms commonly used in medicine, including independent samples t-test, chi-square test, regression analysis, correlation analysis, and Cox regression. Its operational design is fully aligned with the characteristics of medical specialties and scientific research methodologies, automating most data processing and quantification tasks in the background. This eliminates the complexity of manual data handling and enhances research efficiency.
Moreover, in light of the limited statistical expertise among clinicians, the platform intelligently integrates features such as statistical model recommendation and interpretation of model outputs. The analyzed results can be directly exported for use in manuscript preparation.
The platform can customize the export mode for each type of classified data based on its classification model, leveraging advanced technologies such as key event processing, complex logical calculations, automatic row-column transformation, and intelligent standardized value range output. This replaces the extensive manual data processing previously required before statistical analysis, saving physicians significant time during periodic statistical reporting phases.
Beyond the Hospital: Vast Application Potential
The application scenarios of the big data clinical research platform are not limited to hospitals.
In terms of clinical decision support, the research platform leverages learning from real-world data—including knowledge bases constructed from online clinical practice guidelines for various diseases—to assist physicians in standardizing their diagnostic and therapeutic practices. By enabling both trainee and senior physicians to access evidence-based treatment recommendations from the knowledge base, the system facilitates efficient workflow completion and reduces the likelihood of medical errors.
Beyond this, research platforms also hold extensive application value in various emerging fields.
Gan Wei stated, “In addition to providing services to hospitals and physicians, Jiahemeikang has currently partnered with CRO companies to assist pharmaceutical manufacturers in conducting Phase III and IV clinical evaluations, as well as research on drug indications and consistency assessments. Moving forward, the Big Data Division of Jiahemeikang also plans to collaborate with insurance companies, offering services such as medical insurance cost control, policy design, and verification of adverse records.”