NVIDIA Parabricks Accelerates Genomic Discovery with Up to 40x Faster Analysis Using GPU Technology
The storage and computation of genetic data, as an emerging industry, have gradually come to the forefront in the field of genomics. In the long run, as the volume of genetic data continues to grow, the demand for data analysis and storage within the industry will also increase.
The deepening application of genetic testing technologies has made infrastructure for data interpretation and utilization a key factor in delivering solutions. It is for this reason that third-party genetic data solution providers, such as Judao Technology, have emerged in the industry.
Currently, pricing in the gene data analysis industry is relatively transparent. Taking whole-genome analysis as an example, industry insiders report that the market price is approximately $800. In terms of speed, the typical turnaround time for data analysis from FASTQ files to VCF files is currently around 5 hours. Regarding costs, these primarily include expenses for computational infrastructure and analysis software.
In genomic data computation, FPGA acceleration is currently widely adopted in the industry. However, FPGAs have the drawbacks of high research and development costs and a high degree of hardware dependency.
Therefore, VCBeat (WeChat Official Account: vcbeat) believes that to fundamentally reduce data analysis costs, the following approaches can currently be considered:
1. Adopt more cost-effective and larger-scale computing infrastructure, such as FPGA clusters.
2. Develop superior core software, such as faster alternatives to GATK.
3. A storage platform with higher cost-effectiveness and larger scale is required.
Recently, Parabricks, a high-performance genomic sequence analysis software, has achieved a substantial increase in computational speed by leveraging a novel technology. It has reduced the original analysis time to just one hour and lowered the cost to one-quarter of previous levels.
The cutting-edge technology behind the Parabricks software originates from NVIDIA, the world’s largest GPU manufacturer. Leveraging NVIDIA graphics processing units (GPUs), the company is poised to usher in a new revolution in the speed and cost of genomic data analysis.
The content of this article is selected from NVIDIA’s white paper, “Accelerating Genomic Discovery for Precision Medicine.” In this article, you will learn how NVIDIA leverages GPUs to enable Parabricks software to achieve significant breakthroughs in the speed and cost of genomic data processing.
Scan the QR code in the image below to download the white paper “Accelerating Genomic Discoveries for Precision Medicine” and experience the power of this next-generation product:

Whole-genome sequencing requires greater computational power.
Currently, whole-genome sequencing of a single individual generates up to 1 TB of data on average. Processing this vast amount of data requires nearly 1,000 CPU hours to perform genome alignment and variant detection, ultimately yielding biologically meaningful insights for geneticists, bioinformaticians, and clinicians. This computationally intensive task becomes particularly critical when handling large-scale sample cohorts.
Traditional approaches that rely solely on CPU-based computing solutions require scaling up or scaling out existing systems to meet growing demand. However, this is not feasible for the data centers of many Chinese enterprises.
As DNA sequencing technologies continue to advance, the computational analysis of massive DNA datasets has become the primary bottleneck affecting the medical application of whole-genome sequencing (WGS) data. By 2026, it is projected that one billion patients will benefit from WGS technology, a process that entails substantial computational costs and time. These analyses represent the initial steps toward precision medicine, necessitating innovative technological breakthroughs to accelerate genomic data analysis while simultaneously reducing costs.
Common human whole-genome sequencing (WGS) involves the following three steps:
• Primary analysis, using sequencers to convert biological DNA into raw digital DNA data.
• Secondary analysis: processing and analyzing raw DNA data to identify DNA variants with potential biological significance, provided to
Scientists and physicians conduct further analysis.
• Tier 3 analysis to interpret these potential variants and confirm their biological significance.
Secondary analysis is an essential step for subsequent analyses, and tertiary analysis enables insights into its biological significance. It processes large volumes of data by executing various algorithms that have been developed and optimized over the past few decades. Highly accurate secondary analysis typically requires substantial computational resources. Therefore, reducing processing time is imperative.
Faster and more efficient secondary analysis can increase throughput and reduce processing costs, enabling earlier medical discoveries and making genomic analysis a standard part of clinical practice.
To address this, NVIDIA GPUs employ a larger number of CUDA cores (on the order of 1,000) to accelerate parallelizable tasks across different stages of genomic processing, thereby minimizing analysis time and meeting the challenges associated with genomic data processing and analysis.
GPU-Accelerated ComputingGPU-accelerated computing refers to the combined use of graphics processing units (GPUs) and central processing units (CPUs) to accelerate the execution of deep learning, genomic analysis, and engineering applications. GPUs leverage parallel processing technology to decompose complex computational problems into numerous smaller tasks that run simultaneously across multiple CUDA cores. In genomics and related fields, where large datasets are commonplace, GPU-accelerated computing can significantly reduce the time required to process computational tasks.
Built on NVIDIA’s platform, Parabricks has developed GPU-accelerated software solutions that accelerate secondary analysis of raw sequencing data (FASTQ files) generated by sequencers by 15–40×, enabling the identification of potential variants (VCF files) for tertiary analysis.
The standard computational workflow shown below consists of three steps, as defined by the Genome Analysis Toolkit (GATK) provided by the Broad Institute. Parabricks accelerates the existing GATK best-practices pipeline, producing results that perfectly match (100%) those generated by CPU-based implementations, but at a significantly faster speed.

Parabricks’ technology (known as “DNA Bricks”) enables these standard computational tools to run on GPUs, thereby accelerating processing speed. While computations on a 32-vCPU machine in the public cloud (AWS) take 42 hours, DNA Bricks performs the same tasks on a local node/server equipped with 8 GPUs, reducing the time to under one hour.
Based on the NVIDIA platform, the GPU-accelerated workflow developed by Parabricks is shown below. It follows all steps of the GATK Best Practices pipeline and can serve as a drop-in replacement for the entire workflow. Since DNA Bricks utilizes GPUs to execute the main computationally intensive parts of the workflow, it can transfer the output from one stage directly to the next. This enables concurrent execution of multiple steps within the workflow. The entire Parabricks workflow is divided into three stages, with each stage simultaneously running two to three steps of the GATK Best Practices pipeline.
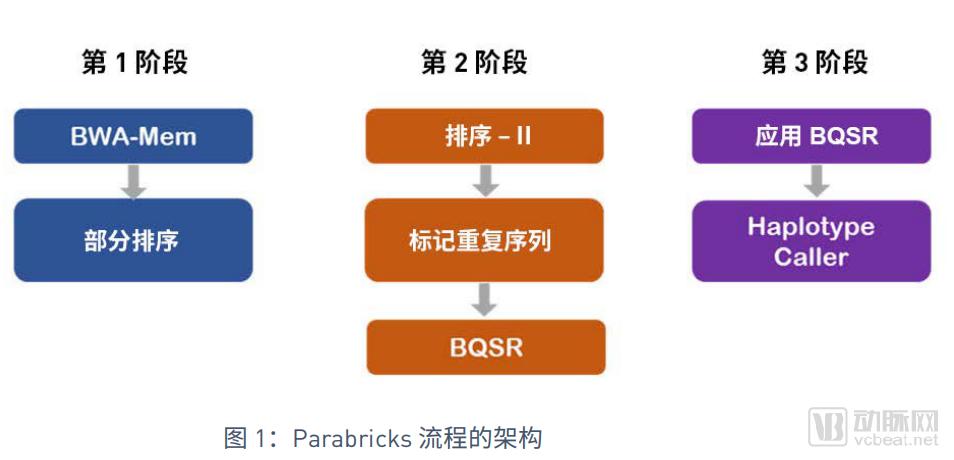
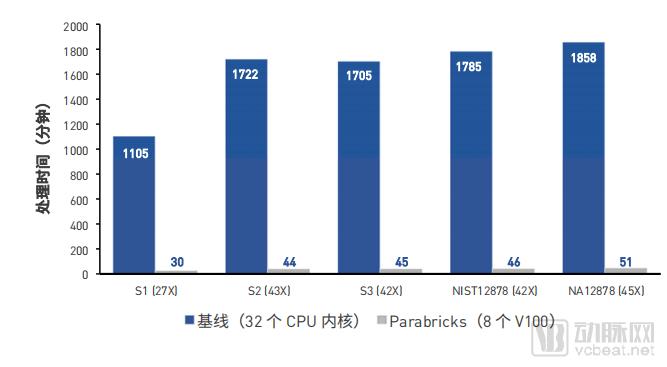
BIOTEC Performance Test Results
BIOTEC conducted internal testing of DNA Bricks on the DGX-1 platform to adhere to GATK Best Practices, which include four main steps:
1) Use BWA-Mem for raw read alignment.
2) Use Picard tools version 2.9 for sorting and BAM format conversion.
3) Picard deduplication and 4) Base Quality Score Recalibration (BQSR) using GATK version 3.7. All experiments were performed on new DGX-1 nodes equipped with dual 20-core Intel® Xeon® E5-2698 v4 processors (2.2 GHz), 512 GB of memory, and eight Tesla V100 GPUs.
In this performance evaluation, five human whole-genome sequencing (WGS) datasets with varying read coverage depths were utilized. The test primarily measured processing time, which was influenced by the varying sizes of the WGS data. BIOTECH’s testing confirmed that DNA Bricks running on the DGX-1 significantly outperformed the CPU-only baseline, achieving a 36- to 40-fold speedup.
Cost Advantage
The on-premises server version of DNA Bricks utilizes a DGX-1 server. At full capacity, this device achieves a throughput of nearly 8,500 whole genomes per year.
In contrast, the CPU-only baseline solution requires 35 servers, each equipped with 32 vCPUs. This significantly increases the total cost of ownership (TCO). Managing 35 servers demands dedicated IT infrastructure, and the costs for power and cooling are substantially higher.
Moreover, task scheduling and priority determination are highly complex tasks. When using a single DGX-1 server, enterprises do not require dedicated IT infrastructure. Furthermore, the DGX-1 is the fastest server for implementing artificial intelligence and machine learning, surpassing any CPU-only solution.
Therefore, running DNA Bricks on DGX-1 servers is the most cost-effective and fastest solution, enabling the highest secondary analysis throughput available on the market today. According to Parabricks reports, DNA Bricks demonstrates near-linear scaling from 4-GPU to 8-GPU platforms, delivering higher data processing throughput.
When adopting GPU-based solutions, enterprises often expect the primary advantage of accelerated processing speeds; however, Parabricks delivers additional benefits that go beyond traditional bioinformatics methods.
Summary of Key Features
In summary, the advantages of NVIDIA Parabricks mainly include the following aspects:
• Equivalent results: Each stage of the Parabricks pipeline produces results that are nearly identical to those of the baseline GATK Best Practices.
• Supports all tool versions: Parabricks’ accelerated software supports multiple versions of BWA-MEM, Picard, and GATK, and will be updated in near real-time to support all future versions of these tools.
• Leverage machine learning to the fullest: It is expected that deep learning for tertiary analysis of genomic data can be performed on the same platform.
• One-stop solution: DNA Bricks runs on standard GPU nodes available in the cloud, eliminating the need for users to perform additional setup steps.
• Run locally or on any cloud: DNA Bricks can run on a local DGX-1 [1] server or on any GPU-accelerated public or private cloud, having been tested on DGX-1 [1] servers, Amazon Web Services (AWS), Google Cloud Platform, and Microsoft Azure.
• Visualization: Parabricks implements multiple key visualizations during secondary analysis, enhancing users’ understanding of the data.
If you are a professional in the field of gene sequencing or third-party genetic data solutions, we highly recommend that you download this white paper to learn in detail how NVIDIA leverages its Graphics Processing Units (GPUs) to make Parabricks, a high-performance genomic sequence analysis software, stand out in terms of computational speed and cost efficiency.