How Blockchain Is Reshaping the Genomic Sequencing Industry: The Nebula Genomics Model
Editor’s Note: This article is reposted from the WeChat official account “Blue Fox Notes” (ID: lanhubiji), authored by Blue Fox Notes, and republished by VCBeat with authorization.
Over the past two decades, the gene sequencing industry has undergone tremendous changes, with one of the most striking being a dramatic reduction in sequencing costs. In 2001, the completion of the Human Genome Project cost as much as $3 billion; today, the cost has dropped to $1,000 and may even fall below $100 over time.
Such a significant reduction in costs means that the conditions for widespread adoption among the general population are now preliminarily in place. This raises the question: even if genetic sequencing becomes affordable for the average person, why should individuals undergo it? Currently, several benefits are evident. First, it facilitates more accurate disease diagnosis. Second, it enables proactive disease prevention; by identifying an elevated genetic predisposition to certain conditions through sequencing, individuals can take preventive measures in advance. For instance, after undergoing genetic testing, Hollywood actress Angelina Jolie discovered she carried a gene associated with a high risk of breast cancer and subsequently opted for a preventive mastectomy. (Of course, from a scientific perspective, this does not imply that such measures are always necessary, nor do they guarantee a complete resolution of the issue; rather, they represent one available preventive option at present.) Third, it helps establish personalized treatment plans.
From the perspective of an ordinary individual, these are the direct benefits. From the standpoint of industry development or the broader interests of humanity, if genomic data can be shared with researchers through certain mechanisms, it would assist them in identifying patterns, providing personalized healthcare and treatment plans, and developing new drugs.
If genomic data sharing is realized, there is an opportunity to create a genomic data market worth over billions of dollars. Both the owners of genomic data and those who demand it will benefit from this.
So, how can a trading market for gene sequencing be established? What issues must be addressed to make its genuine creation possible? This is precisely what this article aims to elucidate.
This article uses Nebula Genomics as a case study for illustration. It is also a case that Blue Fox Notes has recently focused on, which attempts to create a gene sequencing market by leveraging blockchain technology and models.
Nebula Genomics is seeking to drive the development of the gene sequencing industry by exploring multiple avenues.
First, Nebula Genomics must continue to drive a significant reduction in the cost of gene sequencing; only in this way can more ordinary people participate. Greater participation means more genomic data.
Secondly, most people are concerned about new technologies, especially those involving personal privacy and security, such as gene sequencing, and they often have reservations. If the concerns of the general public are not addressed, even low-cost solutions will face barriers to mainstream adoption. Therefore, Nebula Genomics prioritizes enhancing the security and protection of genomic data.
Finally, there are clear buyers for genomic data in this industry. However, the amount of genomic data currently available to these buyers is extremely limited. Nebula Genomics also aims to enable buyers of genomic data to access more data more efficiently.
Based on the clear framework outlined above, Nebula Genomics seeks to address these challenges through blockchain technology, achieving its goals in a decentralized and encrypted manner.
Let’s first examine what genomic data is. Drawing on relevant genomic resources, Blue Fox Notes provides a brief overview of the fundamental concepts of genomic data.
DNA (deoxyribonucleic acid) is a chain-like molecule that encodes the blueprint of every organism. DNA consists of four building blocks, and its chain-like molecules vary in length. The building blocks of DNA are represented by letters: A (adenine), T (thymine), C (cytosine), and G (guanine). The total amount of DNA found in a cell is referred to as its genome. Genes are sequences of DNA that encode instructions for protein production and function as versatile molecular machines. The human genome contains approximately 6.4 billion letters. Most functional sequences in the human genome remain an unexplored frontier.
So, why sequence DNA?
Scientists discovered the function and structure of DNA during their research, attempting to read more DNA sequences, study them, and identify patterns. As previously mentioned, gene sequencing was initially prohibitively expensive, making it virtually inaccessible to the general population. However, technology in this field has advanced rapidly. Next-generation sequencing platforms enable the parallel reading of hundreds of millions of molecules. These technological advancements have led to a dramatic reduction in the cost of DNA sequencing. Additionally, targeted sequencing of protein-coding regions of the genome has further helped lower costs.
Currently, there are numerous direct-to-consumer genetic testing companies on the market, such as Ancestry and 23andMe. Both companies employ DNA microarray-based genotyping for genetic testing. However, instead of sequencing continuous DNA strands, this approach identifies individual nucleotides at roughly regular intervals. As this method does not provide comprehensive base identification, the data generated currently hold relatively limited value for genomic data owners and researchers.
From whole-genome sequencing data, individuals can gain a comprehensive understanding of their genetic makeup. Researchers can also continuously update and refine their findings using larger datasets. Whole-genome sequencing data holds greater value for researchers. For instance, whole-genome sequencing is the only method capable of identifying variants in non-coding DNA. In practice, more than 90% of clinically significant DNA regions lie within non-coding areas. This implies that whole-genome sequencing could become a primary means of discovering therapeutic targets. Currently, the sequencing approach has advantages over microarray-based genotyping methods. If its superior efficacy can be demonstrated in practical applications, it will have a substantial impact on the genomics market.
What are the benefits for individuals?
The preceding text also briefly mentioned the potential benefits of genomic sequencing for individuals. The following section elaborates on these benefits in greater detail.
The genomes of any two individuals on Earth are 99.9% identical. The remaining 0.1% accounts for individual differences. Within this 0.1% variation, there are over four million genetic variants that contribute to distinctions among people, including physical traits, personality, and disease susceptibility.
This means that if whole-genome sequencing is performed for every individual, each person’s unique genetic characteristics can be identified. This information can guide optimal decision-making in health-related areas, including weight loss, exercise, medical treatment, and reproduction. If this becomes a reality, it will herald the advent of an era of personalized precision healthcare, enabling proactive preventive measures tailored to each individual’s genomic profile.
From a prescription perspective, more than 7% of FDA-approved drugs are affected by genetic variants, leading to adverse drug reactions in some patients. With whole-genome sequencing, physicians can prescribe more appropriate medications and dosages for their patients. For example, warfarin is a commonly used anticoagulant; however, it may cause internal bleeding in certain patients who carry genetic variants that enhance its anticoagulant effect.
From the perspective of preventive treatment, approximately 2% of individuals carry early-onset pathogenic variants in highly “actionable” genes. These genes are associated with conditions for which treatments exist and may alter individual outcomes. For instance, mutations in the BRCA1 and BRCA2 genes significantly increase the risk of breast and ovarian cancer. From a preventive standpoint, it is recommended that women with these genetic variants undergo regular screening.
For most people, the number of lethal variants carried in their genetic makeup is small, yet issues remain. For instance, fatty liver disease affects 80 million Americans, but it can be difficult to detect; moreover, genetic variations in over 50% of the population increase the risk of complications from fatty liver disease.
From the perspective of eugenics and healthy reproduction, prospective parents can undergo genomic sequencing to assess the potential health status of their future children. Disease-associated variants inherited from both parents contribute to the risk of disease in their offspring. Currently, 5% of the global population suffers from genetic disorders, the vast majority of which are inherited from previous generations. These conditions can be detected through whole-genome sequencing.
In terms of weight loss, genetic variants have been found to influence the effectiveness of weight loss strategies. This means that different individuals respond to different effective weight loss approaches, allowing for the development of personalized weight loss plans based on an individual’s genetic variants.
In terms of physical exercise, genetic variants are also associated with athletic performance, including endurance, muscle mass, and risk of sports-related injuries. For instance, the risk of ligament tears is linked to variants in collagen genes. In individuals carrying certain genetic variants, head impacts in sports such as boxing can significantly increase the risk of brain disorders. This indicates that different genetic variants exert varying effects on athletic function across individuals. It helps explain why some athletes, such as Lionel Messi in football, can sustain elite-level performance for more than a decade, while others, despite high innate talent, have a “glass-body” constitution and are prone to injury. Part of this variation is attributable to individual genetic variants. Genetic variant sequencing can serve two purposes: first, to assess an individual’s potential for sustained competitive performance; and second, to enable targeted prevention and improvement strategies.
The final area is gene editing. Genetic engineering first requires the identification of genetic variants that underlie physical traits and disease susceptibility. Genome editing is then performed based on these findings. For instance, inactivating the myostatin gene may potentially cure muscular dystrophy.
From the perspective of industry demand, why does the industry have such strong motivation to acquire genomic and phenotypic data?
Researchers, biotech companies, and pharmaceutical companies are all constrained by factors such as the scarcity of genomic data, low data quality, inefficient data collection, and high data acquisition costs.
The availability of genomic data remains low. This is primarily due to the currently small sample sizes, as few individuals have undergone whole-genome sequencing. Without large-scale genomic datasets, it is challenging to establish associations between genetic variants and traits. Beyond data availability, research leveraging machine learning techniques, such as deep learning, is also required; meaningful results can only be obtained through extensive model training. Currently, the field of genomics still struggles to acquire the volume of data necessary for AI-driven learning.
From the perspective of phenotypic data, such data encompasses information on all individual characteristics, including medical history. Phenotypic data is used in conjunction with genomic data to identify associations between genetic variants and traits. However, several issues currently exist with phenotypic data: First, data requesters are not interested in random datasets but rather in datasets from individuals with specific phenotypes; consequently, data buyers acquire data from individuals exhibiting certain phenotypic traits. Second, owners of genomic data must be willing to provide corresponding phenotypic data, as genomic data alone has limited utility without it. Finally, the quality of currently collected phenotypic data is inconsistent, and collection through intermediaries presents significant challenges.
From the perspective of data acquisition, efficiency is low. Currently, pharmaceutical and biotechnology companies obtain genomic data from non-profit or for-profit organizations. However, the entire purchasing process is inefficient and struggles to meet demand. First, the data procurement process lacks automation, requiring manual steps such as contract signing, payment, and data transfer; these labor-intensive tasks are insufficiently efficient for data acquisition. Second, genomic and phenotypic data from different sources are typically encoded in disparate data formats, making the standardization of diverse datasets extremely time-consuming. These issues pose significant challenges for biotechnology and pharmaceutical companies.
Genomic big data is not yet true "big data," making it difficult to utilize for machine learning and hindering subsequent research and development. It is estimated that only 1 million people, representing less than 0.02% of the global population, have undergone whole-genome sequencing. Even so, because whole-genome sequencing for a single individual typically generates a substantial volume of data—approximately 200 gigabytes—it requires computationally intensive processing. This implies that if hundreds of millions of people undergo genomic sequencing in the future, significant challenges will arise. First, vast storage capacity will be required to store genomic data. Second, network transmission speeds will pose difficulties for data sharing. Third, the processing and analysis of large-scale genomic data will demand substantial computational power.
The purpose of the Nebula network is to address the aforementioned issues.
The Nebula model is fundamentally different from traditional approaches. It seeks to reshape the gene sequencing industry through a decentralized framework, establishing a genomic data trading marketplace that offers its own solutions for data ownership, privacy and security protection, economic systems, and big data readiness.
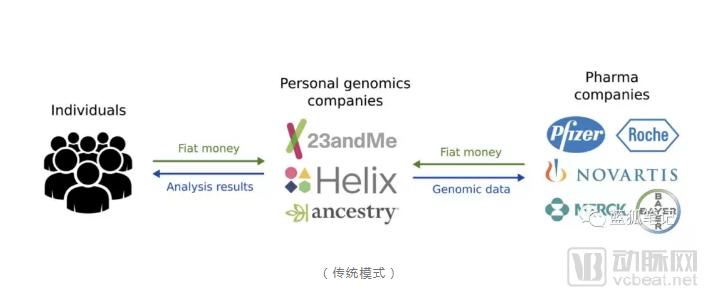
(Traditional Model)
First, data control and security protection.
In the traditional business model of the gene sequencing industry, customers not only pay gene sequencing companies for analytical results, but these companies also monetize the genomic data a second time by selling it to pharmaceutical and biotechnology firms that require such data.
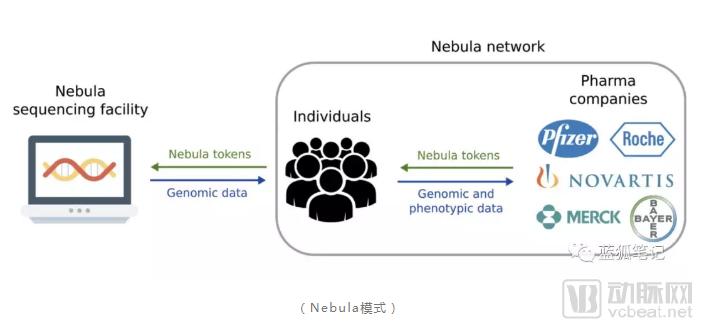
The Nebula model operates differently: after individuals pay sequencing service providers, the resulting sequencing data belongs to the individuals (in the future, if sequencing instruments become affordable, individuals may even perform sequencing themselves). Biotechnology and pharmaceutical companies must purchase genomic sequencing data directly from users rather than from traditional sequencing companies. This shifts the ownership rights of genomic sequencing data.
Meanwhile, gene sequencing data is also protected through the Nebula network. Individuals store their own data, including personal gene sequencing and phenotypic data. Data owners control access permissions. Furthermore, Nebula employs Intel’s Software Guard Extensions (SGX) and homomorphic encryption to encrypt shared data and enable secure analysis.
To protect individual privacy, data owners remain anonymous during data transactions, while data buyers must be transparent. All data transaction records are immutably stored on the Nebula blockchain.
Second, the token model rather than the fiat currency model.
In the traditional model, individuals pay fiat currency to gene sequencing companies to obtain sequencing results, and biotechnology and pharmaceutical companies also pay fiat currency to gene sequencing companies to acquire research data.
In Nebula’s token economic model, an internal economic system has been established.
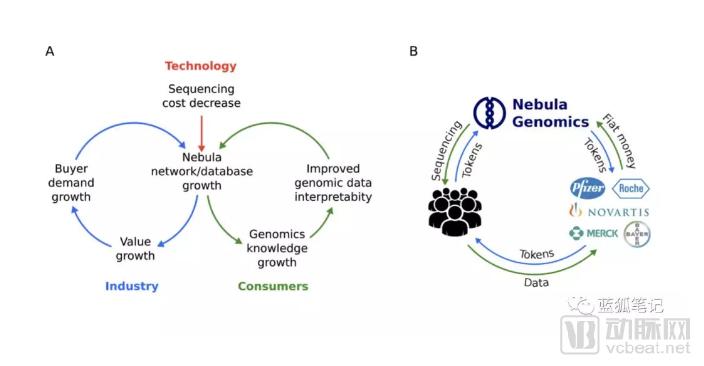
As shown in the figure above, Nebula tokens are primarily used to facilitate circulation within its internal economic system. Individuals must pay with Nebula tokens to access personal genetic sequencing services at Nebula’s sequencing facilities, while biotechnology and pharmaceutical companies also need to use Nebula tokens to purchase genomic and phenotypic data.
In this model, the value appreciation of Nebula tokens is primarily rooted in the overall growth of the Nebula network. By reducing sequencing costs, it attracts more individuals to participate in genomic sequencing, while rising industry demand further drives down these costs. As genomic data accumulates, users benefit from enhanced applications such as disease prevention, weight management, and fertility care, which in turn boosts demand for both genomic and phenotypic data. Within the Nebula economic ecosystem, Nebula tokens serve as the circulating medium, with their value increasing in tandem with the overall valuation of the Nebula network.
Again, the cost of gene sequencing is lower.
Nebula significantly reduces sequencing costs by providing a marketplace for genomic sequencing data. Why is this the case? First, individuals without existing genomic sequencing data can join the Nebula network and obtain such data by paying tokens. Since biotechnology and pharmaceutical companies are interested in individuals with phenotypic data, these companies can provide subsidies, thereby lowering the cost of genomic sequencing. Meanwhile, as more institutions participate in sequencing, demand will increase; potentially, users may one day access genomic sequencing services free of charge. Additionally, users who already possess genomic sequencing data can generate revenue by selling their data through the Nebula network.
Fourth, higher data collection efficiency.
The Nebula Network drives user willingness to undergo genomic sequencing by tapping into the gene sequencing market. In particular, it holds potential positive implications for disease prevention, weight management, and eugenics, thereby significantly increasing users’ inclination to participate in sequencing. Meanwhile, the Nebula Network addresses the problem of data silos by resolving data fragmentation through decentralized private data storage. Individuals or organizations possessing genomic data can provide their data on the Nebula Network while retaining data ownership. Furthermore, data seekers and providers can connect directly, enabling targeted access to high-quality phenotypic data. Survey tools powered by smart contracts on the Nebula Network help data buyers acquire target data more efficiently. The Nebula Network provides standardized formats for genomic and phenotypic data. Finally, the effective application of smart contracts accelerates data procurement by automating contract signing, payment, and data transfer, making the process far more efficient than traditional manual procedures.
Finally, prepare for the big data explosion.
Given the massive scale of genomic data, allowing data owners to store their own data resolves the issues associated with centralized data storage. The Nebula project leverages available edge network storage space. Furthermore, to facilitate computation on genomic data by data consumers, Nebula introduces a specialized data encoding format that also enables rapid transmission of genomic data over networks. Data consumers can readily utilize any computing hardware resources supporting Intel Software Guard Extensions (SGX), allowing them to analyze data on computing nodes provided by Nebula Genomics, on their own nodes, or on other third-party nodes.
The Nebula network is built on the Blockstack platform and the Ethereum-powered Nebula blockchain. So, what nodes make up the Nebula network? Where does its genomic data come from? How is genomic sequencing data processed? How is it stored? How are privacy and security ensured? Where are the transaction records of sequencing data and phenotypic data recorded? Will it decentralize the sequencing process in the future?
These are all critical issues in building a truly viable genomic data trading market.
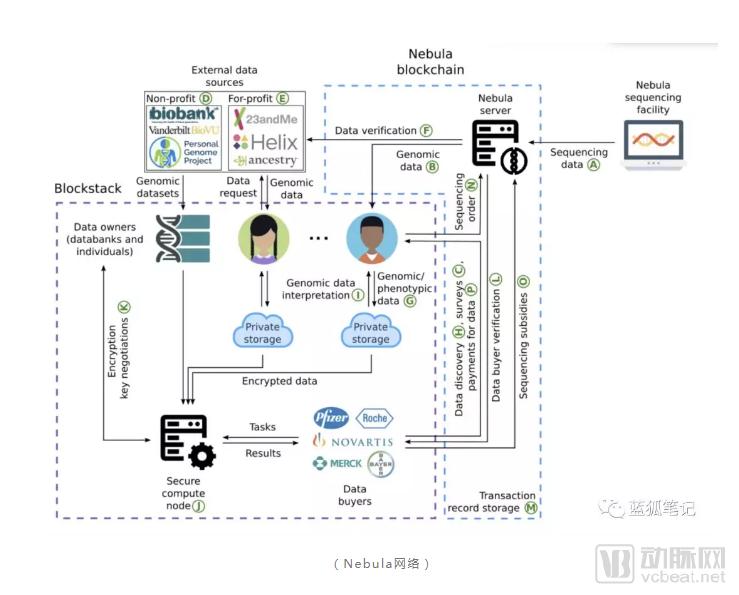
First, let’s look at the nodes of the Nebula network.
The Nebula network comprises data owner nodes, data buyer nodes, secure computing nodes, and the Nebula server. Data owner nodes consist of two types of entities: individuals who wish to share their genomic and phenotypic data, and organizations that possess genomic databases.
Data buyer nodes are typically pharmaceutical and biotechnology companies. They use Nebula tokens to purchase genomic and phenotypic data from data owners, and analyze the data on secure compute nodes. The full compute nodes run the Arvados open-source bioinformatics platform to process genomic data. Secure compute nodes can be operated by Nebula Genomics, data buyers, or other third parties.
The Nebula server primarily processes sequencing data generated by the Nebula sequencing facility, while also validating externally sourced genomic data and verifying the identities of data purchasers.
Secondly, how is the genomic data of the Nebula network obtained?
Nebula’s sequencing facility is expected to utilize next-generation DNA sequencing technology. This technology generates billions of short reads, each approximately 250 base pairs in length. The genomic data for a single individual typically comprises around 30x coverage of sequencing reads, resulting in file sizes of approximately 150–200 gigabytes. Nebula Genomics plans to partner with Veritas Genetics for sequencing services. Through this collaboration, Nebula Genomics can ensure regulatory compliance while avoiding the operational costs associated with maintaining a certified DNA sequencing facility.
In addition to genomic data generated by Nebula’s sequencing facilities, data from other sources may also be available on the Nebula network. For instance, data owners can use Nebula’s tools to convert their data into the genomic shard format. The Nebula server verifies the authenticity of the data, and data owners are required to provide evidence of its authenticity. Furthermore, organizations providing genomic datasets on the Nebula network must undergo verification by Nebula Genomics staff. Meanwhile, data owners may choose to provide data without verification, leaving it to market buyers to decide whether they are willing to pay for such data.
In addition to genomic data, phenotypic data is also required to fully leverage the value of the data. The generation of phenotypic data primarily relies on distributing questionnaires to data owners, who provide information on symptoms, prescribed medications, and diagnoses through their responses. Nebula is also participating in efforts to establish cross-database standards for phenotypic data.
Again, how is the Nebula genomic data processed?
Sequencing data generated on the Nebula network will be processed on Nebula servers. First, sequencing reads will be aligned to the human reference genome to reconstruct genomic sequences, followed by the identification of genetic variants. Meanwhile, to facilitate rapid transmission, the encoded list of variants must be designed for space efficiency. The encoding scheme should also support efficient computation, particularly for machine learning applications. Nebula will adopt a genome assembly-based encoding scheme.
The genome is divided into overlapping, variable-length sequences, with each tile represented by a hash digest of the contained sequencing data. Tile variants across all tile positions are aggregated in a tile library, which continuously expands as new genomic sequencing data and novel variants emerge. An individual’s genome is represented by an array of sequencing hashes. These hash arrays are transferred to the data owner’s node and can subsequently be shared with data requesters. This approach enables rapid network transmission, as the individual’s genome, represented by the hash array, has a size of only 10 megabytes.
Additionally, the sequencing read files will be transmitted to the data owner node. Although the files are large, approximately 150 to 200 gigabytes in size, they need to be transferred from the Nebula server only once. These data will not be shared with buyers. Once the file transfer is complete, all data will be deleted from the Nebula server.
Fourth, how are genomic data and phenotypic data stored?
Data storage and access control will utilize the Blockstack platform, which also supports the development of decentralized applications. The Blockstack storage system allows users to choose their own storage providers, such as Dropbox, and manage data access permissions.
Blockstack also supports data discovery, enabling phenotype registries. Data requesters can query data owner nodes, browse past surveys, and identify data owners who have participated in specific questionnaires.
The tile library, referenced by a hash array representing an individual’s genome, is stored in public storage systems such as IPFS or BitTorrent. All nodes on the Nebula network can access the tile library. In particular, compute nodes access the tile library when performing data analysis.
5. How can secure computation of genomic data be achieved?
The Nebula Network currently utilizes the Arvados open-source bioinformatics platform to process and manage genomic and phenotypic data. Designed primarily for genomics and other large-scale biomedical data, this platform is employed by numerous major institutional clients, including IBM Watson. Furthermore, to ensure secure computation, Arvados operates within Intel Software Guard Extensions (SGX) enclaves on security-compliant computing nodes.
SGX is a set of instruction codes that extend the Intel x86 architecture and enable the creation of dedicated memory regions, where code and data are isolated and protected from external processes. In summary, Intel Software Guard Extensions (SGX) allow untrusted third parties to perform secure remote computations on private data. It facilitates secure computing with higher efficiency than homomorphic encryption and secure multi-party computation.
Furthermore, the hybridization of SGX with homomorphic encryption can accelerate specific computations. Within the Nebula network, data owners utilize secure computing nodes to encrypt and share personal genomic and phenotypic data.
A crucial initial step in many bioinformatics computations is the generation of contingency tables, which contain genomic variant counts and corresponding phenotypes. Contingency table computation involves only addition operations and can be performed using additive homomorphic encryption schemes. First, each data owner node encrypts the value 1 or 0 using an additive homomorphic encryption scheme to indicate the presence or absence of a genomic variant. Subsequently, the compute node sums all encrypted values outside the SGX enclave memory region. The encrypted sum can then be decrypted within the SGX enclave memory region for further computation. Thus, additive homomorphic encryption reduces the number of decryptions to just one.
There are two main drawbacks to using SGX. First, software must be carefully designed to run within the SGX-specific memory enclave without leaking private data. Second, all computations must be executed on Intel CPUs, meaning that computation cannot be accelerated by GPUs. However, subsequent machine learning tasks need to benefit from GPU acceleration.
To address this issue, Nebula adopts a hybrid approach that combines SGX-specific memory regions with data protection mechanisms for GPU-accelerated computing. Data aggregation and preprocessing occur within the SGX-specific memory region, while computationally intensive tasks are executed on GPUs outside this protected area. Preprocessing within the SGX-specific memory region safeguards data privacy through three methods. First, all data is fully anonymized, with SGX preprocessing obscuring the source of input data. Second, only aggregated data summaries, such as contingency tables, are processed. Genomic data is encoded using hash arrays, ensuring that raw genomic information is never exposed. Third, random noise is added to the data to enhance security.
Another advantage of the SGX-GPU hybrid model is that the complexity of Arvados can be kept outside the SGX-dedicated memory region, which significantly reduces the engineering workload.
Sixth, the Nebula Network provides seller privacy protection
The Ethereum blockchain provides a certain degree of anonymity protection for data owner nodes. Network addresses are encrypted identifiers and are not associated with any personal information. Furthermore, buyers are required to undergo verification. From the perspective of genomic data owners, they all wish to know who their data is being sold to and whether these buyers are trustworthy. To ensure buyer transparency, buyers must provide authentic information and be legally bound not to share the data with any third parties. These verification tasks are performed by Nebula staff.
7. Nebula Network’s Blockchain Services
All transaction records of the Nebula genomic data trading market are recorded on the Nebula blockchain, creating an immutable ledger.
Nebula will provide sequencing infrastructure to its partners, including cost-effective whole-genome sequencing services. These services can be paid for using Nebula tokens. Furthermore, costs are expected to decrease as DNA sequencing prices decline. Additionally, data buyers can subsidize individuals’ sequencing costs.
Furthermore, the Nebula survey tool leverages Ethereum blockchain smart contracts to enable data buyers to create highly customized surveys. For instance, all participants can be awarded an equal amount of Nebula tokens, or varying token rewards can be distributed based on individual contributions.
Data buyers can also use Ethereum smart contracts to purchase personal genomic data. After data owners receive token payments, their encrypted genomic data is transmitted to secure computing nodes for processing. Phenotypic data is purchased in a similar manner.
Eighth, valuable third-party applications will also emerge based on the Nebula network.
Unlike other centralized application platforms, Nebula adopts a decentralized model to aggregate genomic data. Genomic data is controlled by individual users themselves.
For instance, data owners can leverage Nebula’s variant interpreter to analyze their personal genomic data. Nebula’s variant interpreter is a decentralized application built on Blockstack that operates directly on users’ local data. The initial version of Nebula’s variant interpreter was based on Veritas’s variant interpreter. This creates a beneficial positive feedback loop: as the Nebula database expands, more associations between genes and health outcomes are identified, thereby enhancing the performance of Nebula’s variant interpreter. This, in turn, attracts more participants to the Nebula network. If achieved, this would result in a self-reinforcing system.
Finally, will Nebula also adopt a decentralized model for the sequencing process itself?
Compared with traditional models, Nebula has reached new heights in genomic data protection through decentralized data storage and secure computation. However, data generation still occurs within centralized sequencing facilities. If these facilities are compromised, genomic data may also be stolen. The only way to mitigate this risk is to decentralize the sequencing process itself.
Ideally, individuals would purchase DNA sequencing machines to perform sequencing themselves, thereby bypassing the need for centralized institutional sequencing facilities. Of course, this is not yet realistic. Current DNA sequencing instruments are large, expensive—with prices reaching up to $1 million—and difficult to operate, making them unaffordable for ordinary users. Nevertheless, technology is advancing; in the future, we may see DNA sequencers as compact as smartphones, with costs dropping to around $1,000. However, this will take time. During this transitional period, Nebula Genomics will continue to seek out the latest technologies to help individuals achieve affordable genetic sequencing. The ultimate goal is to develop an ultra-decentralized sequencing model.
Traditional gene sequencing models struggle to establish a genuine genomic data trading market, as they fail to resolve the issue of user ownership of genomic data, cannot effectively incentivize user participation, and thus face inherent barriers to acquiring large-scale datasets.
Leveraging the decentralized model of blockchain brings about change. Taking Nebula as an example, it first returns ownership of genomic data to individuals. Second, it establishes secure computing frameworks that protect user data. Third, it fully utilizes smart contracts, blockchain technology, and token systems.
As a result, Nebula’s model enables direct transactions between buyers and sellers of genomic data. Unlike traditional models, this approach reduces transaction costs. The cost reduction leads to more affordable genomic sequencing services, thereby encouraging broader participation. Increased participation enhances the value of the data, which in turn makes genomic sequencing services more clinically actionable, with significant implications for healthcare, reproduction, weight management, and general wellness.
In particular, the integration of genomic sequencing data, corresponding phenotypic data, and machine learning may yield many unexpected new discoveries for humanity and provide personalized health guidance for each individual. This holds sufficient appeal for the majority of people.
Furthermore, Nebula addresses privacy concerns through its decentralized model. To alleviate such concerns, genomic data owners within the Nebula ecosystem can store their genomic data privately while maintaining control over access permissions. Technologies such as encrypted secure computation are employed during data sharing. Meanwhile, data owners remain anonymous, whereas data buyers are required to have fully transparent identities. Nebula’s blockchain stores all transaction records, which are immutable.
For data demanders, acquiring high-quality genomic data and corresponding phenotypic data directly from individual users can reduce costs, facilitate the identification of patterns within the data, streamline new drug development, and enable the provision of personalized health solutions to users.
Given that the cost of genomic sequencing remains high and ordinary users still face usability barriers in adopting blockchain and related technologies, there is a long road ahead before a genuine genomic sequencing trading market can take shape. In this regard, we must maintain a clear-headed understanding and exercise ample patience.
As evidenced by the above discussion, blockchain technology and decentralized models have the potential to reshape the genome sequencing industry. It is anticipated that projects like Nebula will fully leverage blockchain to establish a truly scalable, decentralized marketplace for genomic data. Once a positive feedback loop is established, this will generate unprecedented industry-wide impact.