Artificial Intelligence in Healthcare: Seizing Four Key Opportunities and Addressing Four Major Challenges
Artificial intelligence (AI) is increasingly being applied in the pharmaceutical and medical device industries, where it holds promise for improving the efficiency of product development and providing innovative solutions to extend patient survival. However, this emerging field will pose challenges to existing regulatory systems. Therefore, stakeholders must collaborate to ensure the smooth evolution of regulatory frameworks to adapt to the changes brought about by AI.
VCBeat (WeChat: vcbeat) has compiled the relevant report from PharmaLex. The main contents of this article include:
Four Major Opportunities: AI Is Poised to Enhance R&D and Lifecycle Management of Medical Products
1. Use AI tools to evaluate the inclusion/exclusion criteria for clinical trials;
2. Use artificial intelligence to identify clinical activities in Phase II clinical trials;
3. Extract data from unstructured text;
4. Automate administrative tasks.
Four Major Challenges: AI’s Deep Integration into Clinical Practice Faces Regulatory Hurdles
1. How to validate AI software that continuously "learns";
2. How to evaluate safety signals from new AI-based clinical endpoints;
3. How to Review AI-Enabled Medical Technologies;
4. AI Systems Require Data—Who Owns Patient Data?

Opportunity 1: Using AI Tools to Evaluate Inclusion/Exclusion Criteria for Clinical Trials
In clinical trials, artificial intelligence can be used to evaluate inclusion and exclusion criteria related to imaging or histopathology. This application is anticipated, as the first generation of diagnostic tools leveraging AI technology has already entered the market. With these tools, the assessment process for existing inclusion/exclusion criteria will become faster, while costs will decrease due to improved standardization.
AI tools are particularly important for low- and middle-income countries. When diagnosing diseases requires biological samples such as blood or tissue, these countries often lack domestic experts to evaluate the samples. AI tools can effectively streamline this process, enabling researchers to conduct sample assessments locally without the need for complex and time-consuming cross-border transportation.
Opportunity 2: Leveraging AI to Identify Clinical Activities in Phase II Clinical Trials
Leveraging artificial intelligence to assess the clinical efficacy of new drugs can reduce costs, accelerate clinical development, and bring novel therapies to patients sooner—for instance, by evaluating imaging endpoints from CT or MRI scans in Phase II trials. AI-based algorithms can optimize the interpretation and assessment of imaging results, reducing inter- and intra-reader variability, thereby enhancing the sensitivity and specificity of measurements. If this process no longer requires radiologists, it can effectively expedite measurement workflows and lower costs.
Another application is the development of novel clinical trial endpoints, as artificial intelligence (AI) algorithms can help reduce the number of patients required for trials. For example, patients with Parkinson’s disease can wear accelerometers on their wrists, similar to fitness trackers. These accelerometers provide continuous data on motor impairments and their changes over time. AI algorithms then evaluate this data to distinguish whether patients are in an "ON" or "OFF" state, thereby recording whether the medication effectively improves their condition. Compared with patient diaries or the Unified Parkinson’s Disease Rating Scale (UPDRS), this assessment method significantly reduces variability, because the UPDRS cannot measure the exact timing of ON and OFF states. If such clinical endpoints are validated, the reduced variability may facilitate the recruitment of fewer Phase II patients to determine the therapeutic efficacy of a new drug.
Figure 1 illustrates a clinical study on Parkinson’s disease, focusing on sample size and the impact of continuous monitoring. According to the current UPDRS-III scale, over a 12-month period, more than 300 patients (150 per arm) would be required to detect a greater than 40% slowing in disease progression compared with standard care, such as patient diaries. By employing accelerometers for continuous monitoring, approximately 80 patients (40 per arm) are sufficient to achieve 80% of the desired statistical power.
This reduces the previously assumed endpoint variability by a factor of four compared with the UPDRS-III. Such a reduction in variance is plausible because the UPDRS-III scale is associated with substantial variability and can typically be assessed only a few times per year (e.g., four to six assessments), as it requires patients to visit the hospital for evaluation in the off-medication state (without levodopa [L-dopa]). Continuous, rather than intermittent, assessments better capture individual trajectories of motor activity. Moreover, reducing the sample size lowers study costs and accelerates execution.
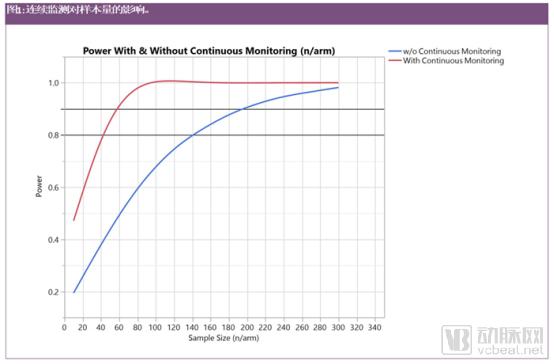
Researchers anticipate that this technological advancement will have the greatest impact on Phase II clinical trials, as Phase III trials require a sufficiently large patient population to accurately assess the safety of new products and to validate Phase II results in a larger sample size. Furthermore, before any new clinical endpoint can serve as a routine surrogate endpoint to demonstrate clinical benefit, it must undergo extensive validation.
Opportunity 3: Extracting Data from Unstructured Text
We can obtain valuable information from unstructured text sourced from health bureaus, healthcare companies, and the internet. This includes relatively complex information, such as that related to intelligent regulation, as well as simpler data. Once extracted and transferred into databases, researchers can easily evaluate these data.
New tools for text mining using natural language processing (NLP) offer novel possibilities for extracting information and data from documents and subsequently uploading them automatically to databases for analysis. AI-based tools are now available that can extract data from unstructured text, such as product characteristic summaries, to identify medicinal product information (IDMP), such as substance names or strengths (see Figure 2).
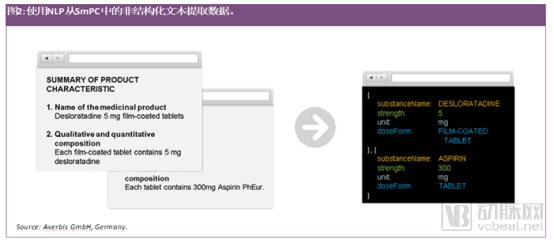
Text mining tools enable health authorities and pharmaceutical companies to better prepare Chemistry, Manufacturing, and Controls (CMC) documentation and guidelines. These tools assist health authorities in evaluating documents across various applications and marketing authorizations, such as identifying identical chemical impurities in products during the manufacturing process or sourcing specific raw materials for the production of new biological entities. This will help regulatory reviewers improve their decision-making processes, while simultaneously assisting pharmaceutical companies in automatically extracting information from health authority regulations and integrating it into intelligent regulatory systems. Both tasks require Natural Language Processing (NLP) software capable of understanding CMC documents. Such software needs access to vast amounts of data to achieve expected results quickly, efficiently, and with high quality, thereby delivering maximum benefit to health authorities and industry stakeholders.
Opportunity 4: Automating Administrative Tasks
Health authorities and healthcare workers manage a substantial volume of administrative tasks, which robotic process automation (RPA) and machine learning (ML) can help alleviate. For instance, a review by the Regulatory Optimization Group (ROG) revealed that approximately 400 full-time employees are employed by relevant authorities and the industry in the European Union to manage Type IA variations. At the AI Alliance Conference, attendees discussed how AI/RPA could automate the handling of Type IA variations, under the premise that companies may implement these changes without prior authorization approval, provided they notify health authorities within a specified timeframe.
One application of artificial intelligence in this area is the intelligent extraction of information from scanned documents (such as registration certificates or copies of trade registers) and the transfer of this information into databases using the “SPOR” standards, covering entities, products, organizations, and reference data (see Figure 3 for details). This technology has already been applied to the automated processing of invoices, where data from invoices can be extracted into ERP systems.
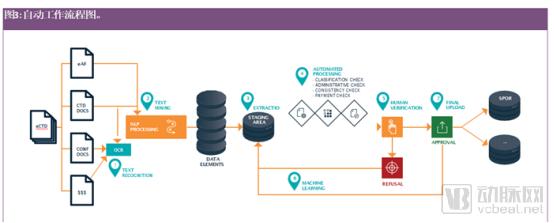
Note: Optical Character Recognition (OCR) converts text and graphics from (scanned) images into machine-readable data/text.
1. CTD documents should be in searchable PDF format, but confirmation documents or proof of payment require OCR;
2. Text mining uses NLP to convert unstructured information from text into structured information/data, such as the address of the MAH or manufacturer, product, substance name, dosage form, and route of administration;
3. Extract the confirmed structured information ("fragments") and transfer them to a staging area, where structured information is maintained during processing;
4. As part of the automated processing, perform various consistency checks;
5. The system displays the workflow and consistency check results; human operators can correct potential errors and ultimately approve the dataset;
6. The system gradually improves its performance by learning from human-reviewed corrections;
7. Transmit the identified structured information to the relevant databases using established standards (such as SPOR).
Challenge 1: How to Validate Continuously “Learning” AI Software
Artificial intelligence systems are continuously learning, giving them immense potential for application in future healthcare. However, this raises a critical question: how and when should AI-based software be validated as it continues to learn during use? One approach is to validate it in an interleaved manner, allowing for re-validation after a certain number of learning cycles. Another concern is whether the validation methods themselves introduce risks; researchers hypothesize that fully autonomous problem-solving systems carry higher risks and therefore require more rigorous validation than tools optimized using machine learning (ML) techniques. Furthermore, validation of both “human raters” and final outcomes is necessary. Consequently, discussions are essential in all cases to determine the most appropriate methods for validating AI-based software.
Challenge 2: How to Evaluate Safety Signals Generated from New AI-Based Clinical Endpoints
As previously emphasized, AI-based technologies facilitate the development of novel endpoints for identifying clinical efficacy. However, such data may encompass safety information that requires thorough evaluation. In the aforementioned example of continuous patient monitoring using wrist-worn accelerometers, the data can identify whether a patient has fallen or is physically active. Therefore, when implementing this new approach, careful consideration must be given to how safety signals are derived from and evaluated within these data.
Challenge 3: How to Review Medical Technologies Using AI
Increasingly complex medical devices and software, including those employing artificial intelligence (AI) technologies, are posing growing review challenges for regulatory authorities. For instance, the first AI software capable of identifying diseases without requiring expert intervention was recently approved. Furthermore, neural networks trained using deep learning techniques can diagnose melanoma from dermoscopic images. In the United States, such products are reviewed and approved by the Food and Drug Administration (FDA), whereas the European Union has a relatively well-established medical device certification system. Consequently, EU member states have designated 60 third-party notified bodies to determine whether medical devices and software comply with Directive 93/42/EEC. It is difficult for so many organizations to attain and maintain the necessary depth of knowledge to regulate increasingly complex technological products, particularly because they must understand not only the technology but also the diseases for which the devices are intended. The AI Alliance conference has questioned the decentralization of medical device and software reviews among EU health authorities, advocating instead for a centralized approach to ensure that appropriate expertise is available for assessment.
Challenge 4: AI Systems Require Data—Who Owns Patient Data?
Artificial intelligence systems require data for “learning,” and in many healthcare applications, the necessary data is derived from patients. Tools developed using such data may facilitate future patient care, but they may also be utilized solely for commercial purposes. In this context, the crux of the issue lies in determining who owns the data and the subsequently developed tools. The answer to this question is not straightforward; stakeholders—including patient groups, legal experts, healthcare providers, industry players, and hospitals—must collaborate closely to make case-by-case decisions in accordance with project scope and regulatory requirements. To promote the development of AI-based innovative tools using patient data, it is essential to establish and implement an international framework with consistent standards. Therefore, discussions on this topic are necessary and should address issues such as data anonymization.
This article is based on the AI Coalition Conference held this year in Basel, Switzerland, which discussed how health authorities and relevant industries should promote the use of artificial intelligence to accelerate clinical development and improve the efficiency of regulatory processes. Regulators participating in the discussion agreed that artificial intelligence offers countless opportunities for improving healthcare in the future, with its potential lying in:
1. Improve the reliability of data collected during clinical development;
2. Reduce the time and cost from product R&D to market launch;
3. Reduce the workload of personnel in health departments and related industries;
4. Develop more innovative medical products.
The application of artificial intelligence in the healthcare sector presents both opportunities and challenges. Neither regulators nor industry players across various countries are fully prepared to embrace this emerging innovation, necessitating a path of exploration and gradual advancement.