White Paper Unveils Full AI Model Training Lifecycle in Hospitals for the First Time
Insomnia has become a widespread condition; it is difficult to cure, highly complex, and poses significant challenges for research. Data from the U.S. Centers for Disease Control and Prevention (CDC) show that more than one-third of American adults suffer from insufficient sleep.
Typically, physicians conduct sleep monitoring by attaching traditional sensors to patients, such as chest belts, nasal cannulas, and EEG electrodes. These uncomfortable methods can themselves induce insomnia, rendering the collected data unrepresentative.
To improve patient sleep, researchers from MIT and Massachusetts General Hospital, in collaboration with NVIDIA, are using AI and Wi-Fi-like signals to monitor patients without the need for any wearable sensors.
Researchers installed specialized wireless devices in bedrooms, allowing monitored individuals to sleep at home. The device collects signals reflected from the subjects and transmits the data back to researchers via the cloud. By analyzing how individuals in the bedroom affect radio frequency signals, along with measurements of pulse, respiratory rate, and movement, researchers can identify different sleep stages: light sleep, deep sleep, rapid eye movement (REM), or wakefulness.
Furthermore, the researchers conducted a study on the sleep of 25 participants over 100 nights. Sleep stages were scored at 30-second intervals, with the data partitioned into separate training and testing sets. Its cloud-based service enables remote signal acquisition and execution of algorithmic models.
Researchers at the Massachusetts Institute of Technology (MIT) used NVIDIA GPUs for model training and inference on back-end cloud services. In addition, they utilized NVIDIA’s cuDNN library and the TensorFlow deep learning framework.
Research on sleep stages holds broad application value, as sleep stage detection technology can be used to monitor conditions such as depression. This use case highlights new application scenarios for “AI + Healthcare.”
AI Applications: From Research to Clinical Practice
Nowadays, deep learning technology is gradually transitioning from research to clinical applications in the healthcare sector. The types of data involved have also expanded beyond radiology and pathology data to include other forms of clinical data, such as electronic health records, hospital operations data, and genetic data.
However, the training and deployment of AI algorithms in hospitals remain immature. This is because achieving clinical impact through deep learning requires not only cutting-edge algorithms but also several other key components:
• Clinicians need to be involved from the outset of the project to clarify the intended use of the AI model;
• Access to annotated clinical datasets;
• Develop machine learning models;
• Integrated into clinical workflows;
• Infrastructure for model deployment;
• Validated in real-world clinical settings.
Based on this, NVIDIA, the world’s leading GPU company, has collaborated with the Clinical Data Science Center (hereinafter referred to as the “CCDS”) of Massachusetts General Hospital and Brigham and Women’s Hospital in Boston, Massachusetts, USA, to establish a scientific training cycle for AI projects. Reportedly, the typical project cycle at CCDS is grounded in clinical feedback, including continuous input from radiologists and frequent evaluations of recent research.
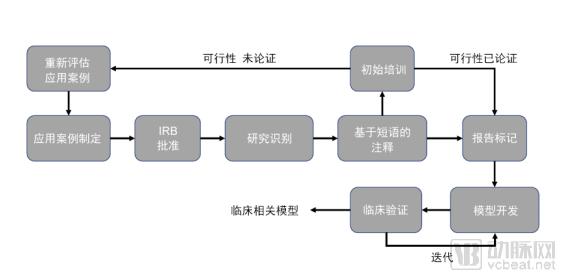
During the typical project cycle of CCDS, dedicated hardware infrastructure is crucial for AI model training, as it serves as the foundation for the entire model development and deployment process.
Hospital clinical systems have limited computational requirements; hospitals tend to favor systems with high reliability and long uptime to meet moderate computing and data access needs. In contrast, high-performance GPUs, high-speed network connections, high-performance storage, and the broadband access patterns required for training neural networks far exceed the capabilities of hospital IT teams.
Clinical Applications of Deep Learning: Hardware Infrastructure Must Meet Computational Demands. Deficiencies in High-Performance Computing Infrastructure at Most Hospitals Are Severely Hindering the Implementation of AI Projects.
This article is excerpted from NVIDIA’s white paper, “Developing Deep Learning Models for Hospitals: A Case Study on Clinical Data Science Centers.” It details how NVIDIA collaborated with the CCDS to leverage its high-performance computing capabilities in addressing various challenges encountered during AI model training, including image processing and initial model development, large-scale model training, and clinical validation.
To learn about the complete process of AI model training, please scan the QR code below to obtain the NVIDIA officially licensed white paper:

Image Processing and Initial Model Development
Once the studies are annotated, the CCDS team begins early-stage model development.
The first step in this process is to convert the research data into an easy-to-use file format. Images are copied from the clinical PACS through vendor-neutral archival of the research, minimizing risks to the clinical system. The images are then stored in a directory on a network storage solution, with access restricted to individuals listed on the approved IRB application.
Volumetric data (e.g., MR, CT) are typically converted from DICOM (the standard medical imaging format used by PACS) to NIfTI (a file format).
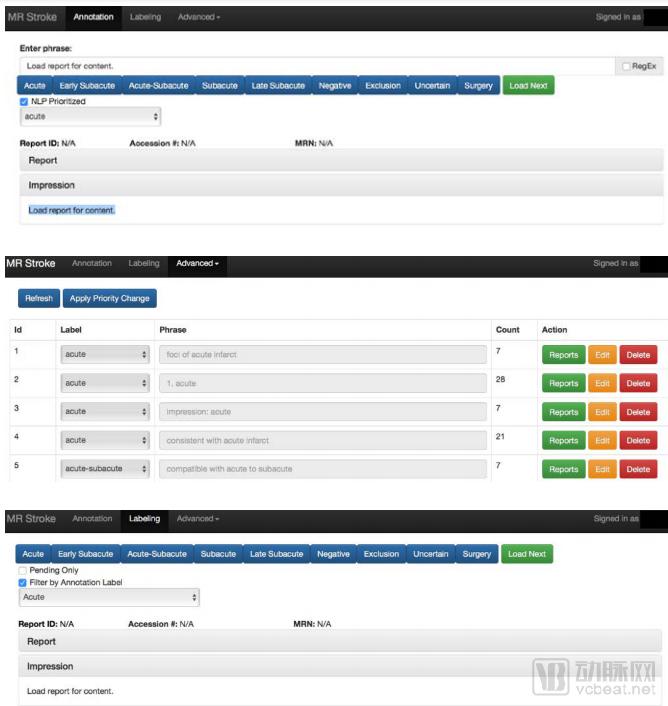
Using a custom-developed web application, the CCDS team annotates studies from radiology reports. Soft labels are initially assigned through phrase-based matching (top), followed by phrase reprioritization and quality assessment (middle). Finally, the CCDS team manually confirms the soft labels on a study-by-study basis (bottom).
The initial phase of model development also follows an interactive workflow. During these interactive sessions, the CCDS team develops and trains the models for a certain period to ensure functional correctness. Due to concerns regarding Protected Health Information (PHI), the CCDS team must initiate these interactive sessions remotely from the partner’s data center to ensure that PHI is stored locally on portable hardware.
This environment is designed to serve as a scaled-down version of the CCDS compute cluster. Therefore, the CCDS team allocates two to four high-performance GPUs (NVIDIA Tesla P100 or Tesla V100) to each machine learning scientist, supporting GPUDirect P2P for efficient intra-node communication and GPUDirect RDMA for inter-node communication.
When training models on volumetric data, these features offer significant advantages and have been proven to be both highly compute-intensive and memory-intensive. The 16GB of high-speed HBM2 memory, support for half-precision floating-point operations, and TensorCore mixed-precision matrix multiplication/addition (exclusive to the Tesla V100) substantially reduce the hardware requirements compared to consumer GPUs.
These benefits are embodied throughout the CCDS infrastructure. Although high performance is not a mandatory requirement during the early stages of model development, these features must be present in the development environment during cluster operations to ensure model correctness. Currently, the CCDS team is exploring two approaches to support this workflow:
1. Static Hardware Allocation: Each machine learning scientist is equipped with a dedicated machine, either a physical server or a virtual machine, on the machine
All explorations of image normalization techniques and initial model development can be conducted on this platform.
2. Dynamic Hardware Allocation: Nodes are allocated from the high-priority queue via the cluster scheduler. Compared to the initial request,
Individual requests to the second node will be deprioritized.
Large-Scale Model Training
Once a set of candidate architectures is identified, the CCDS team leverages the CCDS computing cluster to conduct large-scale training. Although the same hardware is used, these operations are mostly carried out in two steps:
1. Hyperparameter Search: Test candidate architectures with a variety of hyperparameter configurations to determine the optimal model configuration. This process depends on researchers’ preferences or is determined through random search or Bayesian Optimization. By leveraging the surplus capacity of computing clusters, a large number of configurations can be tested in parallel, transforming what was previously a sequential task of testing various architectures and configurations into a parallel one, thereby enabling rapid iteration and optimization of AI models.
2. Large-Scale Training: Once a limited set of model architectures and hyperparameter configurations is determined, each model is trained to convergence in order to identify the optimal model within the group. Successful large-scale training relies on parallelizing the model across GPUs with efficient inter-node communication.
In response, the CCDS team designed the cluster to accommodate the requirements of this workflow. The compute nodes are managed by IBM’s LSF scheduler.
Subsequently, delegate the submitted jobs to available resources and ensure a rational distribution of nodes. Submit jobs via Docker containers to manage development environments and ensure consistency, thereby simplifying cluster management and reducing the number of packages installed on each node.

The CCDS team recently received the world’s first Volta-based DGX-1 system.
Leveraging its user-friendly containerized environment, CCDS has made it remarkably easy to parallelize workloads across multiple nodes, utilizing GPUs with TensorFlow’s transparent synchronization operations and custom internal libraries. The CCDS team also relies heavily on NVIDIA’s NCCL library, which is integrated into the framework to enable efficient multi-GPU operations. This tool allows the team to reduce training time and shorten the model development cycle.
Clinical Validation
Clinical validation of models and tools is a critical step in the CCDS team’s development process. In academic contexts, a model is considered successful if its performance on the test set surpasses that of three to four radiologists. The CCDS team focuses on developing tools for clinicians to diagnose patients and has established a rigorous validation process to ensure the clinical feasibility of these models.
1. Pre-deployment Verification
Model validation commences during the model development phase. The CCDS team collaborates with clinicians to create cohorts and training sets.
The CCDS team collaborated with physicians to curate a vast training dataset. This dataset includes not only clear, ideal images with definitive positive or negative findings for specific diseases, but also studies of lower interpretive quality (e.g., those affected by scanner motion or image artifacts) and cases considered more “challenging” to interpret (e.g., simulations, atypical anatomy, and postoperative follow-up).
To further stress-test the model, the CCDS team evaluated it on consecutive studies acquired from hospital scanners. Given the large volume of images available daily, the CCDS team was able to continuously test the model throughout the development cycle.
2. Post-Deployment Verification
Following integration with the hospital’s clinical systems, the CCDS team needs to evaluate the model within clinicians’ daily workflows. This process facilitates the assessment of:
Model Performance: Does the model perform well in reading rooms, and does it meet radiologists' expectations?
Usability: Does the model and its user interface enhance the effectiveness and efficiency of clinical workflows?
In response, the CCDS team, together with clinical partners, tested the model’s performance and the usability of the tools through a highly collaborative and iterative process.
The software and user interface developers on the CCDS team continuously observe clinicians to understand tool adoption across reading rooms. Given the subtle workflow variations among different clinicians, the CCDS team implements changes at the departmental level rather than for individual radiologists to optimize usability.
This not only increases the likelihood that the model will enhance, rather than hinder, clinicians’ performance, but also helps drive adoption. As more radiologists use the tool and provide additional feedback, the team can further refine the model, creating a virtuous cycle.
Scanners, their sequences, imaging solutions, and reconstruction algorithms are constantly evolving, and teams cannot always detect these software or hardware upgrades.
Therefore, continuous monitoring is required to ensure that model performance does not degrade. Although manual feedback loops can be applied, such procedures are error-prone and increase the workload and additional responsibilities of radiologists. To eliminate this dependency and integrate clinical
To minimize physicians’ workload, the CCDS team automated this process; all model outputs are documented alongside radiologists’ reports. Analytical runs are conducted to evaluate model performance over time and flag significant changes.
Given the potential significant impact of downtime on patient care, hospitals intend to adopt a conservative approach toward the implementation of new technologies. Therefore,
Crucially, any new solution must be thoroughly validated prior to integration and must align with existing workflows.
It is highly beneficial. Although the emergence of deep learning in medicine has brought many new challenges to frontline work, the CCDS team has found that these difficulties can be overcome by appropriately combining creativity, vigilance, and careful selection of vendor solutions.
What technical support does NVIDIA provide?
Throughout the CCDS project, NVIDIA’s AI technology played a pivotal role, encompassing the following key technologies:
1. High-performance GPUs (NVIDIA Tesla P100 or Tesla V100), supporting GPUDirect P2P for efficient intra-node communication and GPUDirect RDMA for inter-node communication.
2. Cluster Infrastructure: The high-performance DGX-1 provides a robust computing platform. When connected via high-speed InfiniBand, it enables efficient training of large models with appropriate batch sizes on voluminous medical datasets.
3. Nvidia-docker enables seamless GPU integration into containers with its latest 2.0 release, further reducing friction. Other benefits already realized by CCDS include the ease of selecting TensorFlow releases, which often require specific versions of NVIDIA’s highly optimized cuDNN library; flexibility in choosing base containers, including non-NVIDIA containers when needed; and a straightforward approach to GPU isolation.
If you are an entrepreneur or investor in the medical AI sector, we highly recommend downloading this white paper to learn in detail how NVIDIA leverages high-performance computing to address the various challenges encountered throughout the entire lifecycle of AI model training in hospitals.