Healthbox Files IPO Prospectus Highlighting AI-Driven Transformation of Healthcare Big Data
“Big Data,” “Artificial Intelligence,” and “Internet of Things” are terms increasingly used in the healthcare industry.
“Artificial Intelligence (AI)” was coined in 1956, but in recent years, the term has surged in popularity due to the exponential growth of data, advances in algorithms that enable machines to “think, work, and react” like humans, and improvements in computational power and storage capacity.
The concept of big data emerged in the 1990s, describing datasets that are so large or complex that traditional databases or data processing application software cannot capture, manage, and process them within a reasonable timeframe, even under low-latency conditions.
The accumulation of big data is driven by the Internet of Things (IoT), a term that has been evolving since it was first used in 1999 as the “Internet for Things,” when radio-frequency identification (RFID) was at the core of the IoT concept.
Nowadays, the Internet of Things (IoT) encompasses everything connected to the internet, including sensors, smartphones, medical devices, and wearable devices. All of these facilitate real-time data collection and upload, leading to the rapid accumulation of health-related big data.
Recently, Healthbox, an innovative consulting and fund management services company, released "Leveraging Big Data" (Harnessing Big Data) report, which aims to explore the relationship between the healthcare industry and big data. The main contents include:
Background: What Is Big Data?
Outlook: How to Leverage Big Data?
Analysis: What Should Be Noted When Leveraging Big Data?
Applications: Real-World Applications of Big Data
Below is the main content of the report, compiled by VCBeat (WeChat Official Account: vcbeat), for your reference:
Background: What Is Big Data?
Over time, the terms “big data,” “Internet of Things (IoT),” and “artificial intelligence (AI)” were coined separately. Today, they have formed a distinct convergence in the rapidly evolving technological landscape, shaping how we collect, perceive, and analyze health-related data.
1956: The term “artificial intelligence” (AI) was coined by computer scientist John McCarthy, who convened an academic conference on the subject.
1990–1999: The term “big data” emerged to describe datasets that were too large or complex to be processed by traditional databases.
1999–2008: The concept of the Internet of Things (IoT) emerged during this period, initially referring to data acquisition through radio-frequency identification (RFID) technology.
Today, human capabilities in artificial intelligence are expanding rapidly. AI is a key component in collecting and analyzing the vast amounts of data generated every second by the Internet of Things (IoT), including all data connected to the internet.
The opportunities for big data in the healthcare sector appear endless, yet many thought-provoking questions remain:
What Types of Data Do We Collect?
What is the source of this data?
What gaps exist in the data we already have, and how can we fill these gaps?
How are these data currently being used, and what are other potential applications?
How can we protect this data to prevent cyber intrusions, data security breaches, and other forms of cybersecurity risks?
The Four “V”s of Medical Big Data Include Volume, Velocity, Variety, and Validity. The widespread adoption of electronic medical records (EMRs), the accelerated discovery of determinants in precision medicine, and the rapid development of wearable biosensors have led to a surge in personal data sources, resulting in an exponential increase in the absolute volume of health data.
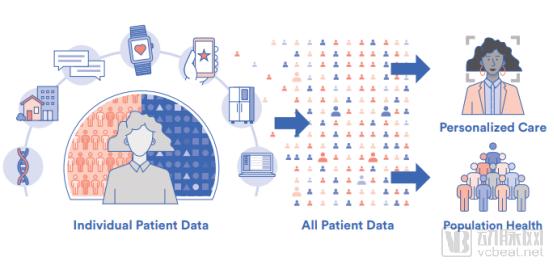
Image source:Healthbox
The evolution of real-time data acquisition and uploading by sensors, smartphones, medical devices, and wearable devices has led to the accumulation of big data. The data being collected are characterized by high volume, velocity, and variety. To leverage this data and ensure its validity for the benefit of humanity, big data poses challenges to evidence-based precision medicine.
In addition to traditional biometric health measurements, there is a wealth of sociodemographic, geospatial, and non-medical metadata that interact meaningfully to determine the health status of individuals or populations.
Challenges in Creating Interoperability Among Traditional Data Systems
Nowadays, we need to integrate a broader range of data across different siloed data sources. To enable big data to meaningfully shape care decisions, it is crucial to determine the validity and accuracy of all these diverse measurement methods, their derived inferences, and the actionable conclusions we draw from this data.
Prospects: How to Leverage Big Data?
Although this may seem daunting, these four “Vs” align well with the needs of healthcare transformation, namely the shift from a fee-for-service industry to an information-based and value-driven healthcare delivery model. Acquiring comprehensive data to describe population characteristics, as well as precise data to tailor decisions to individual needs, will be crucial for informing and prioritizing healthcare strategies, thereby guiding precision medical decisions for specific individuals.
The growing emphasis on preventive interventions, the increasing personalization of treatment for evolving patient conditions, and the coordination of care throughout the entire patient journey have made it essential to acquire, interpret, and continuously analyze patient data. This also necessitates the timely processing of large volumes of data.
Social determinants of health are significant underlying drivers of health outcomes, necessitating the integration of diverse and rapidly expanding data inputs to inform actionable decisions. But how can executable decisions be derived from these data?
Humans are unable to process the vast amounts of existing data, nor can they independently draw meaningful conclusions. Dr. Lily Peng, a medical doctor and product manager at the Google Brain AI Research Group, points out that while human intelligence is best suited for integrating a small number of highly “high-impact” factors, artificial intelligence excels at sorting through and identifying patterns among large volumes of “low-impact” or ambiguous factors. This represents the complementary role that machine learning and artificial intelligence can play as indispensable partners to human intelligence, helping healthcare providers cope with massive, rapid, and diverse data streams from all directions.
Deriving valid conclusions from these vast amounts of data requires redesigning existing decision-making processes by integrating machine learning with human intuition and domain expertise to make effective clinical decisions and enhance the value of care. If appropriately incorporated into the evolving models of care delivery and decision-making, big data and artificial intelligence can serve as effective drivers and catalysts for beneficial change, rather than merely adding unnecessary complexity to the workflows of practicing clinicians.
The days when a patient’s private physician served as the sole source of truth are gone. Whether discussing heart attacks, strokes, trauma, cancer, or complex post-acute care, decisions are made through the collective consideration of a team, not to mention the patient’s own choices and research into their condition.
As we shift from broadly applicable population norms and general standards of care to tailoring care based on the customized needs of specific individuals, extensive empirical data supported by artificial intelligence analytics will be required to define individualized norms relevant to a given patient. Although randomized controlled clinical trials conducted within defined populations aim to control for confounding factors and isolate the effects of interventions in experimental settings, the actual study participants rarely accurately reflect the broad diversity of individuals encountered in the real world.
From a pragmatic perspective, it is unfeasible to design trials for direct patient care that account for all the nuances and personalized encounters in the real world. Therefore, AI-driven parsing and analysis of big data will play a pivotal role in guiding personalized, real-world decision-making.
If big data and artificial intelligence are to effectively support clinical decision-making, four potential challenges must be overcome:
1. Eliminate bias in data collection;
2. Acknowledge the inherent conflict between anonymity and specificity;
3. Conduct meaningful validation of the collected data;
4. Understand potential causal relationships.
Analysis: What Should Be Considered When Leveraging Big Data?
Medical data is disorganized. At the most fundamental level, despite our efforts to standardize medical terminology, diagnostic coding, and more, there remains significant variation in how individual providers describe, conceptualize, and articulate their observations of patients. Typically, the validity and value of any exploration, discovery, and analysis performed on all data are only as strong as the clarity and validity of the underlying datasets. These issues pertain solely to the volume and velocity of the collected data, which must be interpreted.
Standardization, semantic classification, and established concept ontologies are essential steps in “data cleaning,” which are required to standardize large datasets before they are ready for useful analysis using artificial intelligence technologies.
In addition to these considerations, each researcher’s distinct approach to big data introduces inherent biases. Such biases may encompass the categories of data evaluated and the methods used for data collection (e.g., which populations were sampled and which sampling tools were employed, potentially leading to the selective inclusion or exclusion of data within the dataset).
Assume that the power of high-dimensional data lies beneath unobserved confounding factors within the data. Unfortunately, this assumption is far from being a settled conclusion, posing a threat to the validity of conclusions drawn by artificial intelligence technologies from big data. For example, if one fails to account for a variable that is a significant driver of the desired outcome, applying apparent conclusions to scenarios where the covariate relationships with the confounder change may be incorrect and misleading.
This touches upon the root of the intersection between human domain expertise and artificial intelligence, as well as the “major effects” processed by the human brain, which machines may overlook while detecting minor influencing factors.
Theoretically, in the process of harnessing the power of big data, it should be permissible to protect the security of personal identities and health information by anonymizing the sources of individual data points. The value of big data in the real world lies in its analyzability, which provides insights to guide personalized precision medicine decisions for individual patients. The breadth of big data encompasses metadata elements that have the potential to de-anonymize personal identities.
Ultimately, a balance exists between the value generated by open and shared big data and the limited risk of re-identifying data sources (which may infringe upon patient privacy). Appropriate precautions must be taken during structural analysis to prevent the reverse engineering (or back engineering) of patient identities.
However, it is worth noting that the benefits of sharing and opening up data outweigh the risks of re-identifying individuals. Society will have to make an ethical trade-off between the advantages of shared and open-access data and the limited but real possibility of re-identifying individuals through reverse-engineering segmented data. Addressing these issues requires human wisdom rather than artificial intelligence.
It is reasonable to hypothesize that more robust, high-dimensional characterization of patients and their conditions will facilitate a better understanding of the contexts driving specific disease processes. However, it remains to be demonstrated whether effective interventions guided by such data and analytics can reduce costs, enhance satisfaction, and improve the consumer experience.
Therefore, we must integrate data, AI-derived knowledge, and informed clinical decision-making into clinical processes and workflows, weaving them together tightly to unlock the potential benefits for patient care. We also need to conduct well-structured clinical trials to demonstrate that the incremental benefits of data-driven care processes are sufficient to justify any costs incurred by these decisions.
Defining causal relationships is essential to begin translating patterns observed in data into informed interventions, where assumed causal variables can be modified to achieve proposed outcomes. In this process, the most critical step is ensuring that the analyzed data does not omit confounding factors that may have a causal relationship with the measured outcomes. Domain experts and human intuition must always work in synergy with artificial intelligence to confirm the absence of hidden confounders.
On the other hand, high-dimensional data provide opportunities to identify blind spots that the human brain has not considered; these blind spots may be causally related to biases inherent in human domain expertise and outcomes driven by heuristic assumptions. The use of machines can help humans uncover these undiscovered or unanticipated variables.
Before intelligent software can process large datasets and be programmed to think like humans, well-designed randomized controlled trials have long been regarded—and continue to be regarded—as a crucial method for avoiding hidden confounding factors. However, real-world big data are not always divided into intervention and control groups, and significant gaps often exist. Randomized controlled trials or cohort studies do not always provide the missing piece of the puzzle.
Artificial intelligence and machine learning can now provide statistical tools to determine measurements, fill data gaps, and synthesize “controls” for comparison with real-world evidence. These tools offer a path forward to compare observed outcomes from a given intervention with expected outcomes in the absence of that intervention, thereby enabling simulation of testing paradigms that allow for hypotheses regarding determinism and causality.
Applications: Real-World Applications of Big Data
Colin Hill, Chairman, CEO, and Co-founder of GNS Healthcare, envisions a causal machine learning process that first infers underlying causal mechanisms by examining relationships within high-dimensional data. Leveraging this information, “reverse engineering” enables the testing of potential causal relationships in simulated scenario environments. This approach, known as “forward simulation,” allows researchers to validate the effectiveness of causal hypotheses that are difficult to test in the real world.
In the realm of drug discovery, Dr. Mark Murcko, Chief Scientific Officer and Co-founder of Relay Therapeutics, proposed a theory on leveraging forward simulation of drug-target interactions for in silico screening of potential drug candidates to achieve efficacy against biologically validated targets. This simulation is grounded in a data-driven understanding of protein dynamics and functional changes during drug administration.
These approaches to understanding causal relationships combine human domain expertise with artificial intelligence applied to large datasets to predict therapeutic interactions between screened compounds and biological targets involved in disease processes.
While there are numerous theoretical opportunities for applying big data to research, artificial intelligence and machine learning have already made significant waves in healthcare services. The following section highlights companies that leverage big data for patient triage, diagnostic imaging, predicting practice variations, adverse outcomes, and drivers of treatment impact.
For example, Twiage is addressing emergency medicine by helping hospitals track metrics, allocate resources, and improve response times, thereby significantly impacting outcomes for patients with stroke, heart attack, sepsis, and trauma. Buoy Health leverages big data and artificial intelligence to triage patients directly and guide them to appropriate care settings. Patients can use an online application to chat with a bot, describe their symptoms, and be guided through a series of questions similar to those they would encounter in a physical care environment.
With advances in medical imaging technology and growing demand, Zebra Medical Vision aims to help radiologists identify abnormalities in imaging results more quickly. The company’s artificial intelligence algorithms can detect medical conditions, serving as a first set of “eyes” to enhance the efficiency of radiologists’ work.
GNS Healthcare puts the above theories of reverse engineering and forward simulation into practice, leveraging big data and artificial intelligence to run clinical trials, understand how drugs perform in the real world, and help determine the optimal interventions and timing for individual patients.
Agathos provides health systems with an analytics platform that collects insights and delivers feedback to providers, enabling them to visualize personalized and aggregated trends in patient data. This helps inform staffing, pre-rounding preparations, and coaching needs, as well as other requirements for improving clinical workflows and patient outcomes.
PhysIQ and Pascal Metrics are real-time patient monitoring solutions that leverage machine learning to detect subtle changes in a patient’s condition, whether following an acute episode or during hospitalization, and alert their care teams to take necessary action.
So, how can we leverage the relationship between big data and artificial intelligence to drive medical innovation?
The growth rate of new big data applications is as rapid as the data itself. As we continue to develop new methods for integrating big data into artificial intelligence, it has become clear that the following needs are critical:
1. "Clear" all collected data that may contain bias;
2. Standardized methods for data collection or unification;
3. Agree to the proper use of anonymized information;
4. Avoid the trap of confusing correlation with causation.
Image source:Healthbox
To fully harness the power of artificial intelligence, we must embrace collaboration with computers. In this way, we can benefit from both computational power and human intelligence, thereby leveraging big data to drive transformation.
These views are endorsed by Jensen Huang, CEO, President, and Co-Founder of NVIDIA, who also emphasized the importance of “data training,” defined as the process of learning from digital experiences. Meanwhile, as the capabilities of machine learning algorithms rapidly improve, humans must learn to work smarter and adapt to the “new normal,” allowing machines to automate commoditized tasks and freeing providers to perform human-centric care tasks that require a personal touch.
In this way, humans and artificial intelligence can collaborate to reach new heights in data analysis, clinical decision-making, and medical innovation.
(Compiled by Nie Guanghong)