Artificial Intelligence-Powered Intelligent Medical Record Coding: Enabling Accurate DRG Reimbursement and Healthcare Payment Reform
As the importance of the medical record face sheet in healthcare payment and process control increases, the accuracy of its coding data has drawn growing attention. Random inspections of real-world data from various hospitals have revealed that the accuracy of medical record face sheet coding falls far short of regulatory requirements.
To ensure that statistical work and approval baselines are well-founded, hospitals must strictly control the quality of medical record front sheets, rigorously improve the documentation quality among all medical staff, and enhance physicians’ professional ethics and expertise. Meanwhile, technical tools should be employed to assist in reviewing data accuracy and completeness, vigorously promoting the standardization and normalization of medical record front sheet documentation. This will ensure high-quality statistical work and achieve an integrated framework encompassing medicine, statistics, information science, and computer applications.
Meanwhile, it is essential to strengthen communication and collaboration between medical records departments and technical departments, enabling advanced technologies such as artificial intelligence to assist physicians in their daily workflows, thereby enhancing work efficiency and quality.
Columnist: Dr. Liu Zhichen, a senior DRG expert and postdoctoral fellow in Public Administration at Fudan University

Professional Profile: Postdoctoral Fellow at the Postdoctoral Mobile Station in Public Administration, Fudan University, and the Postdoctoral Workstation of the Statistical Information Center of the National Health and Family Planning Commission. A senior strategic expert in the big health sector. With nearly a decade of strategic consulting experience in internet healthcare and the big health industry, he previously served as Director of Strategic Consulting and Scientific Research Business Development at a listed domestic IT solutions and services provider. He spearheaded the planning of numerous forward-looking innovative business models for the big health sector and presciently predicted that reforms in medical payment methods, particularly Diagnosis-Related Groups (DRG), would become a key initiative in deepening China’s healthcare reform during the 13th Five-Year Plan period. As the overall project lead, he participated in a pilot project for DRG-based medical insurance payment reform at the prefecture-level city level in China. He assisted the city’s Medical Insurance Bureau in designing the top-level framework for the citywide DRG payment system reform and implemented the necessary IT system tools to support its execution.
I. Current Status of Intelligent Coding for Electronic Medical Records
Computer-assisted coding tools have been in existence for many years. However, there is currently no consensus in China on the concept of intelligent coding, and the understanding of its implementation remains at a relatively superficial level. Most existing studies on intelligent disease coding are based on diagnoses provided by physicians, offering possible suggestions based on diagnostic keywords to guide coders through step-by-step operations to arrive at the final code (see Figure 1). Another approach involves setting up logical rules within medical record management systems to prompt coding (see Figure 2). Neither approach fundamentally resolves the alignment between diseases and codes, nor does it reflect the essential process of reviewing medical records during coding. Therefore, these methods constitute a form of pseudo-intelligence.
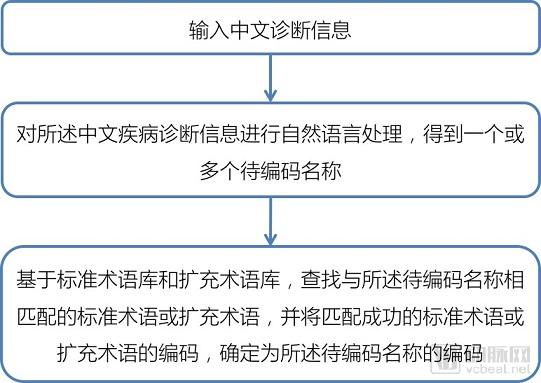
Figure 1. Coding Based on Diagnosis and Standard Library Queries
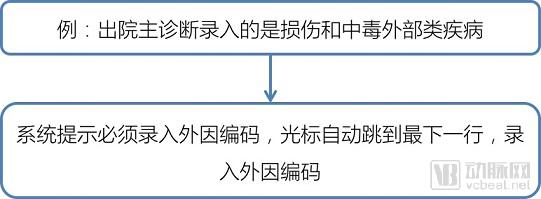
Figure 2. Rule-based Coding Prompts in the Medical Record System Settings
II. Principles of Applying Artificial Intelligence Technology to Intelligent Coding
With the enhancement of computing power, artificial intelligence technologies based on deep learning have experienced explosive growth. AI technology can mimic the human brain to perform a certain degree of logical and non-logical reasoning across various fields, ultimately achieving decision-making capabilities similar to those of humans.
Leveraging advanced artificial intelligence technologies to explore quality control issues in medical record front pages, particularly in code correction and assistance, has demonstrated considerable feasibility. Specific functionalities include intelligent automatic ICD coding, automated determination of the principal diagnosis in cases with multiple diagnoses, and intelligent code consolidation alongside rational cost optimization. Quality control of medical record front page data can be implemented through either a partial or a comprehensive approach. The partial approach relies solely on data contained within the medical record front page, employing relevant analytical methods for processing and analysis to ultimately achieve data correction, optimization, and auditing. The comprehensive approach enables complex data quality assessments when additional information is available, such as electronic medical records, prescription data, and examination results.
The algorithms underlying the application of artificial intelligence (AI) technology in intelligent coding are all based on natural language processing (NLP). NLP enables computers to understand, analyze, and process unstructured text through methods drawn from computer science, information engineering, and AI. In electronic medical records (EMRs), information such as patients’ chief complaints, past medical history, symptoms, diagnosis and treatment processes, and clinical diagnoses is mostly stored in the form of unstructured natural language. Leveraging this disorganized yet highly valuable data to assist in coding the front page of medical records is a critical component in improving hospital management efficiency and quality. Specifically, the steps involved in text processing include:
1. Word Segmentation
Word segmentation is the process of splitting a text sequence into individual words. For example, “diabetic peripheral vascular disease” can be segmented into “diabetes,” “peripheral vessels,” and “pathology.” This process relies on a comprehensive medical knowledge base; otherwise, the accuracy of word segmentation and subsequent text processing steps may be compromised.
2. Word Embedding
Simply put, word embeddings are a type of word representation in which words with similar meanings have similar representations; the term serves as an umbrella for methods that map vocabulary to real-valued vectors. The resulting word vectors are not only low-dimensional but also encode semantic information. For example, the vectors corresponding to “cancer” and “malignant tumor” are close together in the vector space, whereas those for unrelated terms such as “cancer” and “car” are far apart. In this way, computational operations enable computers to “understand” word meanings in a human-like manner.
3. Named Entity Recognition
Following tokenization and word embedding, computers can begin to identify entities with specific meanings within the text. In the medical field, these entities include those related to patients’ basic information (such as name and age), medication names, disease names, and surgical procedure names. Some common entities may be contained within knowledge bases, making their identification straightforward. However, recognizing less common entities requires the implementation of specialized algorithms.
Through the above three steps, computers can already understand the semantics of text quite well. Taking code assistance as an example, computers can achieve this through two approaches: “rule-based” and “artificial intelligence.”
4. Rule-Based
“Rule-based” systems rely on the accumulation of extensive medical knowledge. By employing coding logic and rules, they align and match processed text with standard coding descriptions to achieve accurate coding. The construction of such logic and rules depends on content information from various sections of electronic medical records (EMRs), including patient demographics (gender, age), clinical diagnoses, surgical procedures, imaging findings, and pathological reports. Building a “rule-based” intelligent coding system requires significant time and expert resources, and entails high maintenance costs. However, once established, it delivers superior coding performance and offers strong interpretability of the coding pathways.
5. Artificial Intelligence
The “artificial intelligence” approach enables the rapid construction of a relatively reliable coding model. Its core principle lies in transforming the coding task into a classic text classification problem. In the context of intelligent medical coding, the input consists of electronic health record (EHR) texts, while the output corresponds to the assigned medical codes for those cases. Through training on large volumes of accurate historical data, computer algorithms learn to extract features from the text and associate these features with specific coding labels, thereby completing the learning process.
When data is abundant and of high quality, artificial intelligence algorithms can achieve excellent performance; however, limited data volume and a high prevalence of data errors can cause the computer to “learn incorrectly,” resulting in suboptimal outcomes. Furthermore, compared with rule-based intelligent coding, AI models exhibit poor interpretability, which is a major factor limiting the application of artificial intelligence in many healthcare scenarios.
Therefore, the ideal AI-assisted coding system for medical record front pages should be built on a foundation of medical knowledge and empowered by artificial intelligence algorithms. Such a system can retain strong medical interpretability while leveraging the efficiency and scalability of AI algorithms.
III. Key Technologies of Artificial Intelligence in Intelligent Assisted Coding
Various models developed based on artificial intelligence algorithms, such as advanced natural language processing and machine learning technologies, are applied to medical record front-page data, which primarily consists of diagnostic codes. The specific technical architecture is shown in Figure 3, which includes the following features.
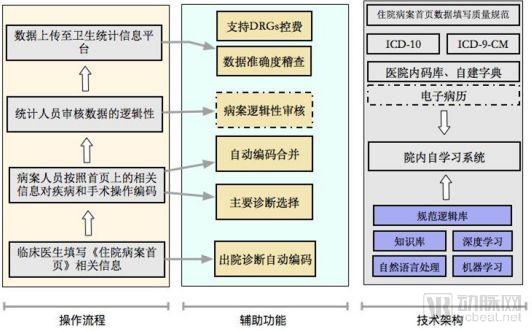
Figure 3 Quality Control Framework for the Front Page of Medical Records
Raw discharge diagnosis information is a critical source of data on the medical record face sheet, and in most cases, it appears in natural language form (i.e., textual diagnostic content manually entered by physicians). Meanwhile, the national standardized ICD coding systems (including ICD-10 and ICD-9-CM versions) also define standard diagnostic descriptions based on natural language. Typically, physicians need to select the appropriate corresponding codes from those automatically matched by the system, based on keywords or complete diagnostic entries they have input. However, in many instances, physicians’ documentation styles differ significantly from the formats used in ICD standards; consequently, keyword searches sometimes fail to retrieve the corresponding ICD codes.
However, this issue can be optimized through knowledge base accumulation and natural language processing (NLP) algorithms. NLP algorithms can perform semantic analysis on the discharge diagnoses written by physicians. They decompose and structure core terms along with their modifiers, such as degree, etiology, pathology, anatomical site, and clinical manifestations. Consequently, information points from different components can be analyzed in distinct ways. For instance, for the primary diagnosis “open fracture of the right humerus,” NLP can break it down into “open,” “right,” “humerus,” and “fracture,” which respectively denote the diagnostic category, laterality, anatomical location, and pathological content. This allows for detailed analysis of each component to identify the corresponding major categories within the ICD coding system.
Furthermore, the medical knowledge base can organize and normalize various expressions referring to the same diagnosis, while also refining the associations among different medical terms. For instance, in the above example, the knowledge base can determine that the “right humerus” is a part of the “humerus,” which is located in the upper arm. Consequently, all incompatible ICD codes are excluded, thereby optimizing the candidate results.
In addition to medical knowledge, the coding process requires coders to possess a certain degree of logical judgment. For instance, they must select the appropriate principal diagnosis from multiple discharge diagnoses, or properly combine and code diagnoses that can be merged when faced with multiple diagnostic entries. Under these circumstances, machine learning and deep learning algorithms can provide a certain level of assistance in this process.
There are many methods for calculating linguistic similarity. Based on prior exploratory experience, single-method approaches yield suboptimal performance in automated coding assistance. Therefore, it is necessary to explore whether models generated by integrating multiple methods can achieve higher usability. Meanwhile, applying neural networks to integrate and correlate the limited variables from various individual algorithms can facilitate the development of new deep learning models with certain logical capabilities, building upon existing algorithms. Some candidate research algorithms are listed in Table 1.
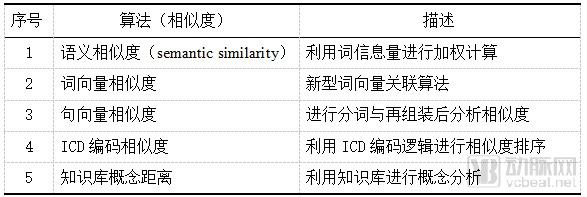
Table 1 Study Algorithms
To achieve accurate selection and combined coding of primary diagnoses, the model must possess robust self-learning capabilities and strong noise resistance. A characteristic of existing in-house coding data—even including historical data submitted to regulatory authorities—is that it still contains numerous subtle errors and biases. Consequently, when training such models, ensuring a certain degree of error tolerance in the absence of complete and error-free training data has become a highly challenging proposition.
IV. Recommendations for Promoting the Application of Intelligent Coding of Electronic Medical Records in the Reform of DRG Payment Systems
With the gradual advancement of DRG-based payment reform, the quality of medical record face sheets is becoming increasingly important, and the accuracy of coding requires significant attention. Many health IT vendors in the market have also begun to focus on quality control for medical record face sheets and the technical implementation of intelligent assisted coding. As artificial intelligence technology continues to advance, AI-driven intelligent assisted coding based on electronic medical record data will offer broader prospects.
Based on the author’s research, several vendors in the current market have already conducted substantial explorations and promoted market-oriented applications to a certain extent, contributing to improved data quality of medical record front pages and enhanced coding accuracy. However, to support the nationwide rollout of DRG payment system reform under the national healthcare insurance framework, top-level design is still required. Specific recommendations are as follows:
1. Implement a standardized and uniform version for completing the medical record face sheet
Although the national government has issued unified requirements for completing the medical record front sheet, in practice, many cities still use inconsistent versions. It is recommended that the National Health Commission or the National Healthcare Security Administration take the lead in promoting a standardized version for medical record front sheet submission, ensuring that the data required by this version meets all data needs for DRG grouping.
2. Implement a unified DRG grouper, release a compatible coding system, and establish a mechanism for regular maintenance and updates
Currently, the mainstream grouper versions in China include CN-DRGs, C-DRG, and the Shanghai version of DRGs. To accommodate different DRG groupers, various schools of thought have developed their own coding systems. Due to significant discrepancies among these different coding systems, they fail to meet the requirements for health information infrastructure development, data sharing, and exchange as mandated by healthcare reform. Therefore, strengthening unified management of disease classification coding and implementing uniform standards has become an inevitable trend.
Therefore, it is recommended that the state adopt a top-level design approach, fully integrate and leverage the strengths of various schools of thought, and establish a unified national statutory version of the DRG grouper, along with corresponding coding standards and rules. A mechanism for regular maintenance and updates should also be instituted to ensure scientific grouping, comparability across diseases, and robust technical support for DRG-based payment systems.
3. Establish a unified national clinical database for medical record front pages and electronic medical records, and set up a dedicated department to implement top-down unified data quality supervision
Based on international experience, a prerequisite for the successful implementation of Diagnosis-Related Groups (DRGs) payment systems in various countries is the availability of accurate clinical and cost data. Consequently, when establishing DRG payment frameworks, countries typically set up specialized departments responsible for data collection, processing, supervision, and auditing.
Taking Germany as an example, the country has specifically mandated InEK (Institut für das Entgeltsystem im Krankenhaus, Institute for the Hospital Remuneration System) to undertake the reform and development of DRGs. One of InEK’s primary responsibilities is the collection and analysis of data from healthcare institutions, with a dedicated data center established to organize and aggregate the data submitted by these entities. Clinical data are primarily used for diagnostic classification systems and procedural classification systems. After being collected and aggregated by InEK’s data center, the data are submitted to DIMDI (Deutsches Institut für medizinische Dokumentation und Information, German Institute for Medical Documentation and Information) for diagnostic and procedural coding. The processing, aggregation, and audit of clinical data by InEK’s data center serve as a crucial safeguard to ensure accurate coding and grouping by DIMDI.
At the coding level, DRG-related coding in Germany is performed by physicians or professional coders in most hospitals. Each hospital has a medical control center responsible for ensuring the accuracy and optimization of coding. The medical control center is also responsible for liaising with the Medical Service of the Health Funds (MDK) during the professional review process.
A key lesson from Germany’s DRG payment system reform is the importance of data infrastructure development. The development of Diagnosis-Related Groups (DRGs) relies on multiple foundational conditions, including information systems, technical capabilities, and policy instruments. Among these, the availability of timely, accurate data on costs, clinical practices, and medical records is a decisive factor in the success of the reform. Building a robust data foundation requires time. Some countries have hoped to establish a DRG system within a month, but in reality, constructing a DRG system is a highly complex undertaking. In the United States, it took 15 years to establish the DRG system, starting with pilot programs in selected states before gradually expanding and refining it. Accurate data form the basis for rational pricing. For example, in Maryland, it took at least 4–5 years to determine the rates as data quality progressively improved.
Furthermore, the continuous evolution and updating of the DRG system itself require substantial data accumulation to better achieve ongoing improvements in disease classification, evaluation and monitoring of severity, as well as the summarization and validation of patterns within highly variable data.
The DRG payment system involves coordinated collaboration among multiple sectors, including health, human resources and social security, development and reform, hospitals, and commercial insurance. Data standardization and cross-departmental data sharing are critical safeguards for the smooth implementation and efficient operation of this payment system reform. It is essential to strengthen national-level requirements for data standardization and accelerate the establishment of mechanisms for cross-departmental data sharing, thereby ensuring data interoperability and facilitating the successful advancement of DRG payment reform.
Furthermore, active promotion of cross-departmental data integration should be pursued to enhance the effective supervision of the joint payment and utilization of medical insurance funds, thereby preventing medical insurance fraud. For instance, identity information can be completed and verified for authentic identity through data from public security authorities or telecommunications operators.
By leveraging rich data sources and real-time data acquisition capabilities, such as artificial intelligence, the Internet of Things (IoT), and 5G, we continuously enhance the accuracy of coding and Diagnosis-Related Groups (DRGs) classification through methods like data cross-validation.
With the rapid development of artificial intelligence (AI) technology, it is feasible to leverage AI-driven “intelligent coding” applications. By employing semantic analysis techniques, key thematic information can be directly extracted from electronic medical records (EMRs). Deep learning algorithms are then utilized to analyze and map this thematic information to discharge diagnoses. Physicians review the diagnostic analysis results and assign the corresponding codes. This approach enhances the accuracy of coding by medical coders and facilitates reverse oversight of coding quality and the data integrity of the medical record face sheet.
However, when implementing DRG-based payments, the Healthcare Security Administration primarily relies on grouping data derived from the medical record face sheet. Although some vendors are now attempting to leverage artificial intelligence to expand data collection from the medical record face sheet to electronic medical records (EMRs), both sources constitute retrospective data generated after patient discharge. Consequently, they do not enable real-time data acquisition or process control during the patient’s hospitalization.
It is recommended to fully leverage Internet of Things (IoT) technologies to collect nursing data, medical device data, environmental data, and patient data related to medical record content. Big data analytics should be employed to cross-validate the contents of medical records, thereby significantly enhancing the completeness, authenticity, timeliness, and credibility of medical record data. This approach also facilitates more precise clinical process management by hospitals and physicians regarding patients’ inpatient treatment, as well as better cost control over the use of pharmaceuticals and consumables. For healthcare security authorities, these process data can be cross-validated with coding data, thereby providing further auxiliary verification of coding accuracy.
Coding determines DRG grouping and payment standards. Therefore, the National Healthcare Security Administration should establish a dedicated body responsible for constructing a comprehensive mechanism for reviewing and supervising DRG costs, coding, and data quality.
With the future implementation of DRG payment system reforms, the data quality of medical record front sheets will directly impact hospital operational revenue. International experience indicates that following the adoption of DRG-based payments, there may be a tendency toward upcoding in certain healthcare settings. This necessitates that regulatory authorities strengthen the auditing and oversight of medical record front sheets by standardizing clinical data to prevent upcoding practices. All these factors underscore the critical importance of attaching high priority to the data quality of medical record front sheets.
Based on international experience, the phenomenon of upcoding following the implementation of DRG-based payment exhibits varying characteristics depending on the specific system design. A review of foreign literature reveals that the likelihood and influencing factors of upcoding risk differ across markets, regulatory controls, and case-mix systems. These variations are illustrated in the figure below:
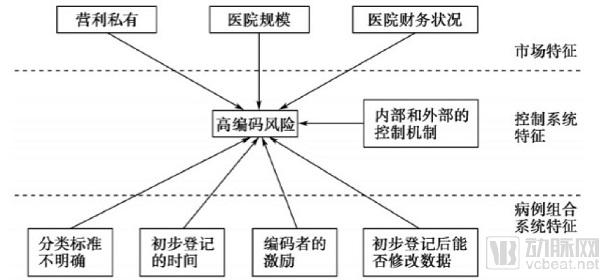
Figure 4. Factors Influencing the Risk of Upcoding in the DRG System
Therefore, it is recommended that the National Healthcare Security Administration, in alignment with the objectives of the Diagnosis-Related Groups (DRG) payment reform and the characteristics of the system, comprehensively design targeted incentive and penalty measures for regulatory oversight of upcoding risks at the institutional level, so as to minimize the risk of upcoding.
DRG involves a series of highly specialized key technical links, including coding, medical records, grouping, weight and rate calculation, and quality supervision. In view of the current talent situation in China, it is necessary to continuously strengthen the intensive training of professionals in different fields and build a mechanism for continuous cultivation, so as to provide professional talent support for the sustainable development of DRG payment system reform.
Particularly in primary care hospitals, secondary hospitals, and private hospitals, data quality has long been poor due to low levels of health informatics adoption, a shortage of professional medical record and coding personnel, and insufficient attention paid by clinicians to the accuracy of clinical data, especially coding. There is an urgent need for improvement. It is essential to rapidly enhance coding accuracy through specialized training and the use of informatics tools such as intelligent coding, thereby ensuring the accuracy of DRG grouping and the smooth implementation of payment system reforms.
Currently, data quality issues in medical record front pages are a widespread problem. The application of information software systems by intelligent coding vendors is still in the research, development, and pilot stages. It is recommended that the National Healthcare Security Administration fully integrate the product advantages of various vendors, select provinces, cities, and key hospitals with favorable infrastructure conditions to conduct pilots, implement trial initiatives, and gradually promote them based on the summary of pilot experiences.
The reform of the DRG payment system is a health economic reform that reshapes the distribution of interests within the healthcare ecosystem, involving stakeholder negotiations across the industry chain. Drawing on international experience, to better safeguard the interests of all parties, many top-level design rules, systems, and standards need to be codified into law. This would enhance the authority of the DRG payment reform and ensure its smooth implementation.
Therefore, China needs to clarify through legislation the series of rules, systems, and standards established in the top-level design for Diagnosis-Related Groups (DRGs), as well as the negotiation mechanisms among stakeholders, organizational forms and safeguards, data standards such as DRG grouping and coding, and quality supervision.
References
1. Zhu Mingyu. Research on Intelligent Coding of Medical Record Front Pages Based on Medical Artificial Intelligence Technology [J]. China Digital Medicine, 2018(4).
2. Gao Yi. WeChat Official Account: Pavilion in the Wind — Article: [Tea Talk on Health Insurance by the Hearth] Section 12: A Technical Perspective on Auxiliary Coding Systems for Medical Record Front Pages.
3. Lu Hui, Chen Jiaying. Comparative Study on the Risk of Upcoding in Case-Mix Systems in the United States, Australia, and the Netherlands[J]. Foreign Medical Sciences (Health Economics Fascicle), 2008, 25(3): 120-126.
Copyright Notice:
Most of the viewpoints presented in this article are derived from Dr. Liu Zhichen’s personal postdoctoral research findings. The cited articles and viewpoints reflect those of their respective authors, obtained from publicly available sources. Without prior permission, any use—including reprinting, excerpting, copying, or creating mirror images—is strictly prohibited.