Are AI Medical Companies Ready for China's NMPA Review Guidelines on AI-Enabled Medical Devices?
Six months after the National Medical Products Administration (NMPA) conducted a public welfare training session on “Registration and Application for AI-Based Medical Devices,” the official detailed guidelines regarding approval requirements have finally been released. During the conference held six months ago, the NMPA provided a meticulous analysis of every stage influencing the approval of medical artificial intelligence devices, offering exhaustive explanations for each specific metric. This time, the NMPA has formally issued to AI enterprises the approval-related document titled “Key Points for the Approval of Medical Device Software Using Deep Learning for Assisted Decision-Making” (hereinafter referred to as the “Key Points”), thereby establishing the specific metrics relevant to the approval process in an official documentary format.
Compared to the previous meeting, the National Medical Products Administration (NMPA) did not devote excessive space to procedural introductions. Instead, the document directly addressed six key points: data quality control for AI software, algorithm generalization capability, clinical use risks, the direct impact of data quality control and algorithm generalization capability on clinical use risks, and the indirect impact of failures in computational resources (i.e., the operating environment) used for computing power.
Specifically, the Guidelines consist of five sections: scope of application, key points for regulatory review, software updates, relevant technical considerations, and instructions for registration submission materials. Each section provides a highly detailed introduction to the indicators involved.
It should be noted that this document not only addresses considerations for computer-aided diagnosis, but also specifies requirements for non-clinical decision support software and traditional artificial intelligence software, as well as considerations related to third-party databases, mobile computing, and cloud computing.
Drawing on the content of the “Key Points,” VCBeat interviewed several professionals in the field of medical artificial intelligence, aiming to identify the development directions for “Healthcare + AI” in the second half of 2019 from within the policy framework.
From the perspective of approval processes and focal points, the fundamental principle of software regulation—risk-based lifecycle management—has long been established. The key elements required for its implementation, including scope of application, risk considerations, requirements analysis, software validation, and clinical trials, have become standardized; however, details within these areas continue to be refined.
Key Review Points: The evaluation focuses on data quality control, algorithm generalization capability, and clinical use risks. Clinical use risks should account for the direct impact of data quality control and algorithm generalization capability, as well as the indirect impact of failures in computational resources (i.e., the operating environment) used for computing power.
Specifically, VCBeat extracted six keywords from the "Key Points," which clarify the critical considerations for AI companies during the approval process.
The scope of the guidelines covers two categories of software.
1. Deep Learning-Assisted Decision-Making Medical Device Software: Software that utilizes deep learning techniques to assist in decision-making, based on medical device data (medical images and medical data generated by medical devices, hereinafter collectively referred to as “data”).
2. Software that utilizes deep learning techniques for pre-processing (e.g., image quality improvement, acceleration of imaging speed, image reconstruction), workflow optimization (e.g., one-click operation), and routine post-processing (e.g., image segmentation, data measurement), among other non-clinical decision support functions, may refer to these review points.
It is important to note that deep learning software is no longer categorized into AI Standalone Software (AI software that constitutes a medical device in itself) and AI Software Components (AI software embedded within a medical device). Instead, products are classified based on whether they “assist in decision-making,” thereby emphasizing the “auxiliary” function of the product. Meanwhile, this also clearly indicates that non-decision-support software will enter the approval process through similar pathways.
The review raised concerns regarding software data quality control, algorithm generalizability, and clinical use risks. Clinical use risks should consider the direct impacts of data quality control and algorithm generalizability, as well as the indirect impact of failures in the computational resources (i.e., operating environment) used for computing power, across six aspects.
These six aspects represent the actual challenges faced by AI companies. Data quality determines the maturity of algorithms; generalization capability refers to the universality of AI products across different populations; and clinical trials are a key constraint on the current development of AI products. Each of these issues has hindered a number of AI enterprises.
So, after reiterating these key regulatory points, will the NMPA propose corresponding solutions to assist AI companies? Or must we still wait for time to provide the answer?
During the approval process, data collection should consider quality control requirements for activities such as data acquisition, data preprocessing, data annotation, and dataset construction to ensure data quality and algorithm design quality.
In actual regulatory review, data plays a critical role throughout the approval process. According to VCBeat, multiple artificial intelligence companies had their applications for the “Special Approval Procedure for Innovative Medical Devices” rejected by regulatory authorities on grounds such as: “failure to specify the primary source institutions for datasets used in training, tuning, and testing”; “absence of information on the distribution of primarily collected data”; “lack of test data from different devices and source institutions”; “insufficient details on personnel qualifications and numbers required for quality control in data annotation”; and “absence of user testing based on real-world data with adequate sample sizes.”
Regarding the aforementioned issues, the Key Points state that quality control for data acquisition devices should clearly specify compatibility and acquisition requirements. Compatibility requirements should provide a list of compatible acquisition devices or technical specifications based on the data generation method (direct or indirect generation), clarifying requirements for the manufacturer, model and specifications, and performance indicators of the acquisition devices. If there are no specific requirements for the acquisition devices, corresponding supporting documentation should be provided.
Acquisition requirements shall clearly specify the acquisition method of the imaging device (e.g., conventional imaging, contrast-enhanced imaging), acquisition protocols (e.g., MRI imaging sequences), acquisition parameters (e.g., CT tube voltage, tube current, exposure time, slice thickness), and acquisition precision (e.g., resolution, sampling rate).
If existing historical data are used, the requirements for data collection equipment and the criteria for assessing data collection quality (e.g., personnel, methods, metrics, and acceptance criteria) shall be clearly specified. Meanwhile, the collected data shall undergo de-identification to protect patient privacy. The de-identification process shall clearly define the type (static or dynamic), rules, extent, and methods of de-identification.
The document also provides clear requirements for data preprocessing, data annotation, and dataset construction; however, these requirements are relatively straightforward, requiring enterprises only to implement them in accordance with the specified formats, which will not be elaborated upon here.
In addition to the requirements for standard naming, the “Key Points” address issues related to algorithm training and cybersecurity protection.
Among these, algorithm training requires training and tuning based on the training set and tuning set. It is necessary to clearly specify requirements such as evaluation metrics, training methods, training objectives, tuning methods, and the curve of training data volume versus evaluation metrics.
Evaluation metrics should be selected based on clinical needs, such as sensitivity and specificity. Training methods include, but are not limited to, the holdout method and cross-validation. The training objectives must meet clinical requirements, with evidence such as ROC curves provided for verification. The tuning approach should clearly define the algorithm optimization strategy and implementation methods. The training data volume–evaluation metric curve should demonstrate the adequacy and effectiveness of the algorithm training.
In terms of cybersecurity protection, requirements for building software cybersecurity capabilities shall be determined based on cybersecurity properties such as confidentiality, integrity, and availability, in conjunction with the software’s intended use, usage scenarios, and core functions, so as to address cyber threats such as cyberattacks and data theft. For relevant requirements, refer to the Cybersecurity Guidelines.
Common cyber threats to AI-based software include, but are not limited to, framework vulnerability attacks and data poisoning. Framework vulnerability attacks refer to cyberattacks that exploit vulnerabilities in the off-the-shelf frameworks used by algorithms, while data poisoning refers to cyberattacks conducted by contaminating input data.
Software validation is a key focus of the current “Key Points.” The document explicitly states that companies should submit clinical evaluation data based on clinical trials in accordance with software guidance principles, i.e., either clinical trial data for the product under application or clinical trial data for similar products or software with substantially equivalent core algorithms to those of the product under application.
For clinical trials, the Key Points recommend prioritizing a non-inferiority controlled design using products of the same type or clinical reference standards (i.e., clinical gold standards). If no products of the same type are available and obtaining clinical reference standards is difficult (e.g., due to ethical concerns), alternative methods may be adopted, such as employing a superiority controlled design comparing user decision-making assisted by software versus user decision-making alone. The determination of non-inferiority or superiority margins must be supported by sufficient clinical evidence. Furthermore, to account for inter-user variability, a multi-reader multi-case (MRMC) trial design may be selected.
“Key Points” recommends that enterprises select observation indicators based on factors such as the target population and pathological changes. In principle, sensitivity, specificity, and ROC/AUC should be chosen as the primary observation indicators. Additionally, depending on the software’s characteristics, other metrics—such as derivatives of sensitivity/specificity, derivatives of ROC/AUC, intraclass correlation coefficient (ICC), Kappa coefficient, time efficiency, and data utilization rate—may also be selected as observation indicators. Inclusion and exclusion criteria should be established based on the epidemiological characteristics of the target disease to ensure the rationality and adequacy of positive and negative sample selection. In practice, however, most enterprises tend to select sensitivity, specificity, and ROC/AUC as their primary observation indicators.
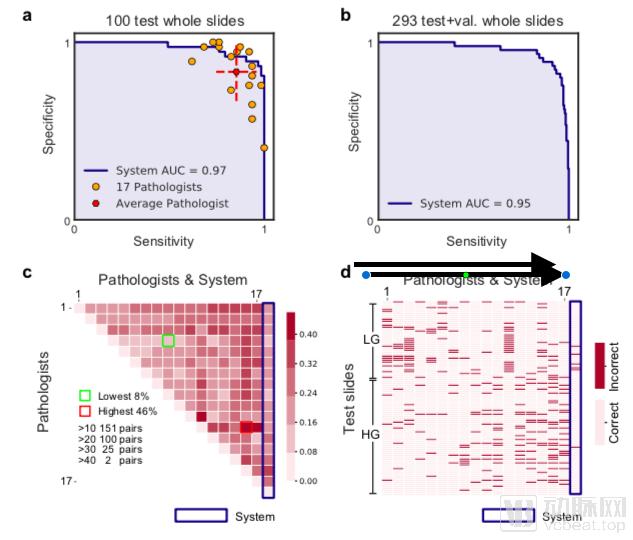
The identification of pathological images requires the use of AUC as an evaluation metric. The image is sourced from the paper “Pathologist-level Interpretable Whole-slide Cancer Diagnosis with Deep Learning.”
Regarding the results of clinical trials, the "Key Points" recommend independent evaluation by third parties. The implementing institutions should be representative and diverse, distinct from the primary sources of training data. They should have as broad a geographic distribution as possible and include as many institutions as feasible to confirm the algorithm's generalization capability.
For example, for a software product whose primary objective is to improve the time efficiency of assisted diagnosis, where there are no equivalent products on the market and it is difficult to obtain clinical reference standards, the clinical trial design may adopt a crossover controlled design comparing user decisions made with the aid of the software versus user decisions made independently. The primary endpoints should include sensitivity, specificity, and time efficiency; among these, sensitivity and specificity may be evaluated using a non-inferiority design, while time efficiency should be evaluated using a superiority design.
In fact, many companies in China have already attempted to validate the real-world effectiveness of artificial intelligence products through multicenter trials. On May 30 this year, Shukun Technology released its multicenter study results comparing its AI against the gold standard, a practice worthy of emulation by other enterprises.
Finally, the Key Points indicate that a retrospective study based on existing historical data is sufficient for clinical evaluation, with no mention of prospective studies. According to insiders, there have been no cases in which AI products’ clinical evaluations were approved through prospective studies.
“The Key Points” state that the declared software name must comply with the naming conventions for generic names of standalone software, reflecting characteristic terms such as the processing object (e.g., CT images, fundus photographs), target disease (including lesions and disease attributes), and clinical purpose (e.g., auxiliary screening, auxiliary identification).
The scope of application for standalone software intended to assist in clinical decision-making shall clearly specify the intended use, usage scenarios, and core functionalities, including but not limited to: data processing objects, target diseases, clinical indications, eligible patient populations, target users, settings of use, requirements for data acquisition devices, and limitations on clinical use.
The enterprise must provide: 1. The core algorithm section of the software description document shall include corresponding algorithm research data in accordance with these review points; 2. A statement on the compliance of data sources; 3. Data on the analysis of factors influencing algorithm performance, as well as comparative analysis data of algorithm performance evaluation results under various test scenarios.
This section is relatively straightforward; however, VCBeat has learned that some companies have still had their applications rejected by regulatory authorities for reasons such as “discrepancy between the product and its actual intended use.”
In addition to the six key points mentioned above, the "Key Points" also address issues such as third-party databases, evaluation databases, and cloud deployment. However, there are no significant changes compared to previous policies. Instructions for use shall be implemented in accordance with the "Provisions on the Administration of Instructions and Labels for Medical Devices."
Requirements for Non-Decision-Support Software, Traditional AI Software, Third-Party Databases, and Mobile and Cloud Computing. The "Key Points" propose the following evaluation requirements: "For pre-processing software functions, algorithm performance evaluation and clinical evaluation shall in principle be conducted; for workflow optimization software functions, only algorithm performance evaluation is required, without the need for clinical evaluation; for conventional post-processing software functions, algorithm performance evaluation is in principle sufficient, whereas entirely new functions shall undergo clinical evaluation."
Following the government’s announcement, VCBeat reached out to AI companies such as Deepwise Medical, Shukun Technology, and TomoDeep. Regarding the policy itself, most companies indicated that it does not differ significantly from previous policies; rather, the “Key Points” provide more detailed planning in certain specific areas. In practice, these companies have been carrying out approval procedures in an orderly manner in accordance with existing policies.
It is worth noting that some companies, which preferred to remain anonymous, stated that they are also attempting to conduct clinical evaluations through prospective studies, aiming to gain recognition by exceeding standard requirements; however, the outlook remains uncertain.
Some Companies Are Striving for Innovation Amid the Approval Process
Regarding the policy itself, Zhang Jinglei, founder of Jingmeng Consulting and a long-time analyst of medical policies, offered a different perspective. He believes that while the policy provides a detailed description of the approval process for artificial intelligence, serving to standardize and clarify procedures, it does not mean that Class III medical device certifications will be issued imminently. On the contrary, this may signal that the government will impose stricter regulation on AI-based medical products.
Nevertheless, given that AI’s role as an “auxiliary” diagnostic tool has been firmly established, where should related companies direct their efforts under this definition?