Deepwise AI Achieves Major Research Milestones with Five Papers Accepted at ICCV 2019 Following Strong Presence at MICCAI 2019

DeepWise
Developer of Artificial Intelligence Medical Imaging Diagnosis System

The paper submission process for ICCV 2019 has recently concluded. DeepWise Research Institute had five papers accepted, one of which was selected for an oral presentation. ICCV, short for the IEEE International Conference on Computer Vision, is recognized as one of the three premier conferences in the field of computer vision, alongside the Conference on Computer Vision and Pattern Recognition (CVPR) and the European Conference on Computer Vision (ECCV). Held biennially worldwide, ICCV features exceptionally fierce competition for paper submissions and acceptance. At the previous conference, ICCV 2017, a total of 2,143 papers were submitted, with only 621 accepted, resulting in an acceptance rate of 28.9%. According to the official data released this year, the conference received a total of 4,328 submissions—double the number from the previous edition—intensifying the competition among high-quality papers. Ultimately, 1,077 papers were accepted, yielding an acceptance rate of 24.8%.
The proceedings of the International Conference on Computer Vision (ICCV) often represent the latest developments and trends in the field of international computer vision. This year, the five papers accepted from DeepWise cover research directions that include both medical image analysis and fundamental methods in computer vision. Among them, two papers represent innovative breakthroughs in the application of artificial intelligence in healthcare, which will further drive the continuous innovation and development of DeepWise’s Dr.Wise® AI-assisted medical diagnostic products, enabling AI technology to better serve clinical practice.
One paper, titled “Learning with Unsure Data for Medical Image Diagnosis,” was jointly researched by DeepWise, Peking University, Capital Medical University, and Microsoft Research Asia. This study primarily addresses how to better leverage uncertain medical annotation data for training diagnostic models.
In clinical scenarios, when a disease is still in its early stages, image-based disease prediction alone often struggles to assign definitive “disease/normal” labels to certain cases due to insufficient signals and information. Such samples are referred to as “uncertain” data. However, “uncertain” does not imply that the data are invalid. In clinical practice, patients are frequently advised to undergo follow-up examinations to obtain a final clinical diagnosis, thereby avoiding irreversible medical errors or losses that may result from hasty predictions. Nevertheless, most current machine learning methods overlook “uncertain” data and primarily model only “disease” and “normal” samples, leading to suboptimal identification of “uncertain” cases.
To address the aforementioned issues, this paper proposes the problem of “learning with uncertain data” and formulates it as an ordinal regression problem, thereby presenting a unified end-to-end deep learning framework. The framework design also incorporates: 1) cost-sensitive parameters to mitigate data imbalance, and 2) two parameters introduced into the training procedure to implement conservative and aggressive strategies. Experiments demonstrate that learning with uncertain data offers significant advantages and high effectiveness in tasks such as early diagnosis of Alzheimer’s disease (AD) and disease prediction for pulmonary nodules.
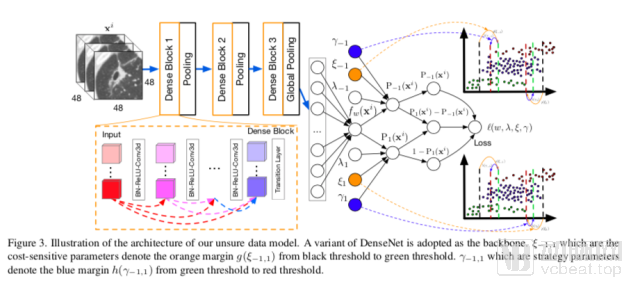
Uncertain Data Model Framework
Another paper, “Align, Attend and Locate: Chest X-ray Diagnosis via Contrast Induced Attention Network with Limited Supervision,” employs weakly supervised learning techniques for the detection of lesions in chest X-rays. As is well known, chest X-rays are widely used in outpatient/emergency examinations and health screening programs; therefore, automated methods for detecting abnormal findings on chest radiographs hold significant clinical value for the early diagnosis of thoracic diseases. Moreover, the classification and localization of abnormal findings in medical scenarios offer greater clinical utility and interpretability compared to simple classification of findings. However, due to the prohibitively high cost of data annotation, there is a severe shortage of publicly available high-quality annotated datasets, resulting in currently low accuracy for finding localization.
This paper primarily focuses on the problem of sign classification and localization. Leveraging the high structural similarity of chest X-rays, we pair positive and negative samples and employ a Contrast Induced Attention mechanism in the high-level semantic space to guide the potential locations of lesions based on their differences. Furthermore, to address imaging variations caused by differences in acquisition angles and distances, particularly in bedside radiographs, we draw upon the Perceptual Loss commonly used in style transfer algorithms to train an Alignment Module that outputs correction parameters. This module aligns and corrects all chest X-rays to a statistically standard canonical structure (Canonical Chest). On the Chest X-ray 14 dataset, which has very limited location annotations, our method achieves significant improvements in both sign classification and localization accuracy, surpassing current state-of-the-art algorithms.
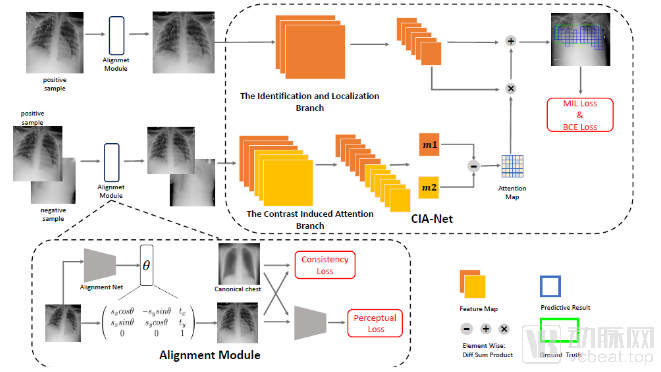
Algorithm Workflow: First, the alignment and correction module unifies paired positive and negative samples to the standard chest X-ray view via affine transformation; then, an attention mechanism derived from the differences between positive and negative samples is applied to the high-level feature space of the positive samples; finally, the main branch for recognition and localization outputs the category and location information of the signs.
Among the selected papers, three are research achievements from DeepWise Research Institute in the field of fundamental computer vision. The most notable is the oral presentation paper titled “Dynamic Graph Attention for Referring Expression Comprehension.” Referring Expression Comprehension aims to localize target objects in images based on given natural language descriptions, where the referring expressions may describe not only the target objects themselves but also their relationships with other objects. From the perspective of language-driven visual reasoning, the authors explore this complex multimodal problem by proposing a Dynamic Graph Attention Network that simultaneously models the linguistic structure of referring expressions and the relationships among objects in images, using the linguistic structure as guidance for multi-step visual reasoning. Experimental results demonstrate that the Dynamic Graph Attention Network not only achieves higher prediction accuracy than existing methods but also enhances the interpretability and visualizability of the visual reasoning process by progressively localizing target objects described by complex expressions. The other two papers present innovative research in video salient object detection and 3D human pose estimation.
Five Papers Accepted at ICCV 2019
1. Jingyu Liu, Gangming Zhao, Yu Fei, Ming Zhang, Yizhou Wang, Yizhou Yu. “Align, Attend and Locate: Chest X-ray Diagnosis via Contrast Induced Attention Network with Limited Supervision.” IEEE International Conference on Computer Vision (ICCV), Seoul, October 2019.
2. Botong Wu, Xinwei Sun, Lingjing Hu, Yizhou Wang. “Learning with Unsure Data for Medical Image Diagnosis.” IEEE International Conference on Computer Vision (ICCV), Seoul, October 2019.
3. Hai Ci, Chunyu Wang, Xiaoxuan Ma, and Yizhou Wang. “Optimizing Network Structure for 3D Human Pose Estimation.” IEEE International Conference on Computer Vision (ICCV), Seoul, October 2019.
4. Haofeng Li, Guanqi Chen, Guanbin Li, Yizhou Yu. “Motion Guided Attention for Video Salient Object Detection.” IEEE International Conference on Computer Vision (ICCV), Seoul, October 2019.
5. Sibei Yang, Guanbin Li, Yizhou Yu. “Dynamic Graph Attention for Referring Expression Comprehension”(Oral Presentation).IEEE International Conference on Computer Vision (ICCV), Seoul, October 201