NVIDIA Unveils Privacy-Preserving Federated Learning System for Medical Imaging at MICCAI 2019

NVIDIA
Artificial Intelligence Computing Service Provider
As one of the world’s most prestigious conferences on medical imaging, MICCAI 2019 (Medical Image Computing and Computer Assisted Intervention) was held in Shenzhen from October 13 to 17, 2019. This marked the second time the conference had been hosted in China since 2010.
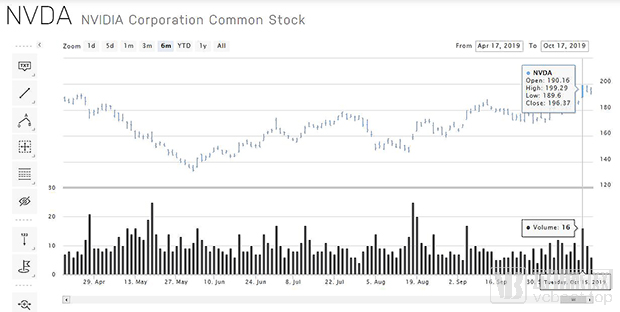
As a leading supplier of computer graphics hardware, NVIDIA jointly unveiled the first privacy-preserving federated learning system for medical imaging with King’s College London at the conference. In response, NVIDIA’s stock price surged. On October 15, it opened at $190.16 and climbed as high as $199.29, just shy of the $200 mark. The stock ultimately closed at $196.37, representing a 5.27% increase from the previous day’s close of $186.53 and marking its highest closing price since November 15, 2018.
A reporter from VCBeat (WeChat ID: vcbeat) was invited to attend the media briefing held by NVIDIA during MICCAI 2019. At the briefing, Kimberly Powell, Vice President of Healthcare at NVIDIA; Liu Tong, General Manager of High-Performance Computing and Industrial AI Business in China at NVIDIA; and Nicola Rieke, Senior Research Scientist at NVIDIA, introduced the first privacy-preserving federated learning system designed for medical imaging. Meanwhile, we have also compiled an overview of NVIDIA’s recent advancements in the healthcare sector.

NVIDIA Vice President of Healthcare, Kimberly Powell
Federated Learning: Addressing the Pain Points of Deep Learning
To train models that match the proficiency of medical experts and achieve the precision required for clinical applications, AI algorithms must be trained on large datasets of cases that adequately represent real-world clinical environments. Taking radiologists as an example, to become experts in a specific subspecialty, they typically handle at least 15,000 cases per year and require 15 years of practice to reach expert-level competence—accumulating a total of 225,000 cases. In other words, artificial intelligence needs to learn from a comparable volume of medical records to attain the same level of expertise as radiology specialists. Unfortunately, the largest currently available open-access database contains only 100,000 cases, which still falls short of meeting the data requirements for AI training.
The situation becomes even more complicated when rare diseases are taken into account. For conditions that affect one in every 1,000 people, even an expert with three decades of experience would encounter only approximately 100 cases of a specific disease.
Individual healthcare institutions may possess archives containing hundreds of thousands of records and images; however, due to privacy concerns and regulatory requirements, these data remain completely isolated and inaccessible to one another, forming “data silos.” As a result, both AI enterprises and healthcare institutions deploying AI are forced to rely solely on their limited internal data sources. This constraint has made the bottlenecks in the practical application of AI increasingly apparent. If the shortage of high-quality annotated data persists, it could even lead to a decline in the current wave of enthusiasm for AI in healthcare.
To address this issue, federated learning has emerged. Unlike traditional approaches that require uploading all data to a central server, federated learning enables multiple institutions to iteratively train models using their local data and subsequently upload and share the model updates. This process does not involve sensitive clinical data or patient privacy.
Let us illustrate this with a specific case. Suppose three hospitals decide to collaborate in establishing a central deep neural network to assist in the automated analysis of brain tumor images. If they opt for client-server federated learning, the centralized server will maintain the global deep neural network. Each participating hospital will receive a copy of this neural network model to train using its own data.
After several rounds of local iterative training, participants send the updated version of the model back to the centralized server. This process transmits only the fully trained model, rather than sending pathological data as in conventional approaches. Upon receiving the uploaded model updates from various locations, the server updates the global model based on these contributions. Subsequently, the server shares the updated model with participating institutions, enabling them to continue their local training.
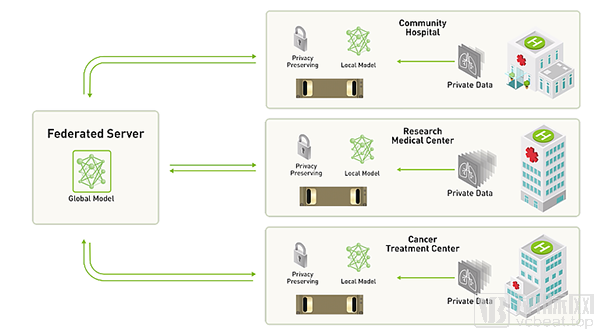
In fact, over the course of several training iterations, the shared model is exposed to a much broader range of data than any single organization possesses internally, resulting in more effective training. Meanwhile, since only the model needs to be transmitted, the requirements for network transmission bandwidth are significantly reduced.
Since the training of the global model does not rely on specific data, the departure of one hospital from the model training team will not halt the training process. Similarly, a new hospital can join the program at any time to accelerate model training.
Federated learning enables multiple organizations to collaborate on model development without the need to share sensitive clinical data or compromise patient privacy. The industry hopes that this novel approach will resolve the current data dilemmas facing AI. Compared with traditional models, federated learning can also encourage different institutions to cooperate in creating a model that benefits all parties.
Google was the first to apply federated learning in actual development. The Gboard keyboard, showcased at the Google I/O 2019 conference, utilizes this novel model training approach. Previously, because local input data from keyboards contained substantial user privacy information, it was not feasible to upload such data for training predictive models used in smart input methods. With federated learning, each Android device can train the model locally and then upload the model updates for aggregation, thereby accelerating the development of input method technologies.
Precisely because federated learning holds the potential to address the current dilemmas facing AI, it is garnering increasing attention within the industry. At MICCAI 2019, Shaohua Zhou—editorial board member of IEEE TMI and Medical Image Analysis, area chair for CVPR and MICCAI, and co-chair of the MICCAI 2020 Program Committee—identified federated learning as one of the three possible future directions for AI development.
The outcome of NVIDIA’s collaboration with King’s College London is the first privacy-preserving federated learning system designed for medical imaging. In addition to conducting comparative analyses of various aspects of federated algorithms that handle momentum-based optimization and imbalanced training nodes, this system also features enhanced privacy protection.
Federated learning can ensure a high level of privacy security, but it is not impregnable. Theoretically, by understanding the underlying operational logic and performing model inversion attacks, it is indeed possible to reconstruct the data. Therefore, researchers from NVIDIA and King’s College London have introduced the Sparse Vector Technique (SVT) into this model. By adding “noise” to blur the data and altering the granularity of the original data, the difficulty of model inversion attacks is significantly increased.
NVIDIA V100 Tensor Core GPUs were utilized throughout both the training and inference processes. This technological achievement will also be integrated into the Clara SDK, released late last year, to enable better utilization by developers. Meanwhile, it is evident that because federated learning distributes the model training process—originally centralized on a central server—to various locations, it imposes certain hardware requirements on participating institutions, thereby increasing the number of GPUs needed to some extent.
Meanwhile, large-scale federated learning projects are being launched. The UK-based MELLODDY consortium is primarily focused on drug discovery. It brings together 17 partners: ten leading pharmaceutical companies, including Amgen, Bayer, GlaxoSmithKline, Janssen, and Novartis; two top European universities—KU Leuven and Budapest University of Technology and Economics; and four startups.
NVIDIA has partnered with MELLODDY to leverage NVIDIA’s AI platform for improving drug discovery. Meanwhile, through federated learning, the model is trained on the world’s largest collaborative drug compound dataset without compromising data privacy.
Despite the numerous advantages of federated learning, certain policy restrictions still need to be overcome. For instance, most countries and regions, including China, require that data be stored locally. In theory, cross-regional federated learning does not violate such regulations; however, practical implementation is evidently far more complex.
“NVIDIA is now primarily focused on developing tools and the overall infrastructure, making it more reasonable for each region to establish its own training centers. Meanwhile, we are also building a local medical team in China. Our participation in MICCAI 2019 was driven not only by the need to publish our results but also by the opportunity to meet with potential partners.” Kimberly believes that establishing a local network is the solution that best serves the interests of all parties.
Liu Tong, General Manager of High-Performance Computing and Industrial AI Business at NVIDIA China, also provided an explanation. He stated that NVIDIA’s primary objective remains to empower the AI industry with GPUs. Whether to establish shared federated learning data centers depends entirely on the considerations of local regions or individual institutions. “We simply provide a convenient approach for implementing this technology. For example, a province may have 30 hospitals. Decisions such as whether to share data for model training, whether to set up a shared center, and whether to use private or public cloud are all determined by the institutions themselves.”
“Of course, we have engaged with numerous AI startups that are helping clinical healthcare partners build training platforms. You could also say that we support the broader community by assisting these startups in building their platforms,” he further explained.
Clara's Calculations
In 2012, AlexNet, designed by Geoffrey Hinton, then a professor at the University of Toronto, and his student Alex Krizhevsky, improved the accuracy of computer image recognition by an order of magnitude and won the 2012 ImageNet competition. This marked the beginning of a new era in deep learning. AlexNet utilized two NVIDIA GeForce GTX 580 graphics cards to accelerate the training of deep convolutional networks, demonstrating the immense potential of GPUs in AI applications.
Since then, NVIDIA has become one of the most critical hardware components for AI acceleration. The GPU’s particular proficiency in handling parallel workloads enables it to accelerate convolutional neural networks by a factor of 10 to 20, thereby reducing data training iteration cycles from several weeks to just a few days. After several generations of hardware upgrades, the CUDA-X platform is now ubiquitous in the AI field. As Kimberly Powell, Vice President of NVIDIA Health, stated, NVIDIA has become the engine of the AI industry.
The vision of an “AI engine” has underpinned NVIDIA’s strategic initiatives in the healthcare sector over the past few years. In late 2016, NVIDIA launched its first artificial intelligence supercomputer, the DGX-1. Its computational performance is equivalent to that of a high-performance computing cluster with 250 nodes, reducing network training time from weeks to days. In March 2018, NVIDIA introduced the DGX-2, powered by the next-generation Tesla V100 GPUs, which increased computational power tenfold within six months and became the first deep learning system to surpass 2 petaflops in performance.
Drawing on its early experience in the gaming market, NVIDIA has placed particular emphasis on the development of supporting software and APIs. In 2018, NVIDIA launched the Clara AI platform. This platform supports scalability from entry-level devices to the most demanding 3D imaging systems, integrating AI into next-generation medical instruments to serve as a tool for early disease detection, diagnosis, and treatment. The Clara AI platform has been adopted by GE Healthcare’s Edison AI platform and Nuance’s AI Marketplace.
The Clara AI platform can also leverage AI to empower legacy equipment. For instance, a hospital may have a CT scanner that is 15 years old and completely lacks support for reconstruction algorithms or artificial intelligence analysis algorithms. After installing the Clara platform, this CT scanner only needs to be connected to a server via a network to access the latest algorithms through the Clara AI platform.
Within a few months, NVIDIA released the Clara SDK. This software development kit provides developers with a suite of GPU-accelerated libraries for computing, advanced visualization, and AI acceleration, and offers containers for building hardware-abstracted applications through subsequent updates. The aforementioned federated learning capability will be integrated into the Clara SDK.
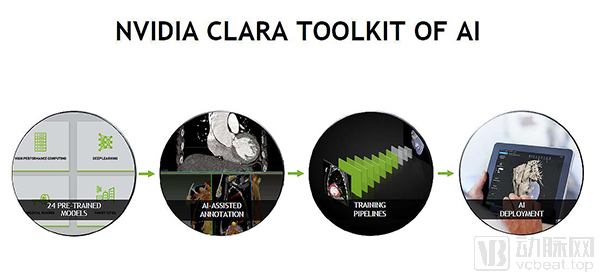
Kimberly also introduced other updates to the Clara SDK, which has undergone multiple iterations since its initial release. The latest version features a fully preconfigured workflow, allowing developers to bring their own models to the platform for training, thereby offering a more developer-friendly experience.
The new version of the Clara SDK also integrates several open-source tools. For instance, the new medical imaging viewer allows observation of images from three perspectives, functioning as an AI-assisted analysis tool. Thus, it offers greater convenience from a user’s perspective.
Finally, performance optimizations have been implemented, particularly reducing data loading time during training—developers have reported that data loading can sometimes take longer than model training itself. Additionally, the new SDK version enables automated multi-GPU training, eliminating the need for user intervention.
For NVIDIA, the Clara SDK is undoubtedly a powerful strategic asset. Drawing on its early experience in pioneering the gaming market, NVIDIA places immense importance on development tools and APIs. After attracting developers with superior hardware performance, these tools and APIs significantly facilitate their work, thereby fostering strong developer loyalty to NVIDIA’s products and enabling the company to build its own ecosystem. This integrated software-and-hardware strategy has allowed NVIDIA to overcome numerous obstacles and defeat many competitors on its GPU journey, growing into today’s giant in the fields of GPUs and general-purpose computing.
Clearly, NVIDIA aims to replicate its past successes in the race for AI acceleration. The existence of the Clara SDK will grant NVIDIA a significant competitive advantage, potentially establishing it as the industry standard in the future. This is precisely why NVIDIA is currently not actively pursuing the establishment of unified industry standards. If NVIDIA GPUs are likened to the engine of the AI industry, then the Clara AI platform and Clara SDK serve as the turbocharger that delivers powerful performance to this engine within the AI healthcare sector.
When asked whether there were plans to collaborate with the industry to create a unified and efficient AI framework, Kimberly Powell stated that NVIDIA had no such plans. After all, NVIDIA has made substantial investments in the GPU sector and has become a widely recognized AI powerhouse. Coupled with advanced software stacks like the Clara SDK, which is specifically designed for AI in healthcare, NVIDIA GPUs have become the premier platform for training and deploying state-of-the-art AI solutions.
“Using CPUs for inference and training is not cost-effective in terms of both expense and time. While some simpler models may be run on CPUs, computationally intensive models such as those used for medical imaging are a different matter. Therefore, many people still choose to use GPUs,” stated Kimberly Powell.
Due to architectural differences, the Clara SDK cannot support GPUs from other manufacturers. NVIDIA clearly has no incentive to collaborate with the industry to establish a universal API or software toolset—after all, having worked hard to build such a pronounced advantage, who would be willing to treat it as charity? In fact, for the sake of compatibility, general-purpose tools are often less efficient than specialized ones. Take the battle for general-purpose computing in recent years as an example: OpenCL, which supports a wide range of GPUs from AMD, Intel, Qualcomm, and others, ultimately failed to compete against NVIDIA’s proprietary CUDA.
However, Intel’s recently released oneAPI may pose a strong challenge to NVIDIA. According to Intel, oneAPI supports both API-level and direct programming by providing unified languages and libraries, thereby delivering optimal code performance across diverse hardware platforms—including CPUs, GPUs, FPGAs, and AI ASICs—while significantly simplifying the development process. Given Intel’s current footprint in CPUs, FPGAs, and ASICs, along with its upcoming launch of GPU accelerators, if oneAPI truly delivers on these capabilities, it would be unwelcome news for NVIDIA.
Of course, even if the competitor’s claims are valid, it will still take considerable effort to catch up with the advantage NVIDIA has established. NVIDIA’s long-running “Startup Acceleration Program” includes more than 700 healthcare startups and brings together a large number of partners in the clinical field.
Meanwhile, in April 2019, NVIDIA entered into a collaborative agreement with the American College of Radiology (ACR). By integrating the Clara AI platform into the ACR AI-LAB, newly released by the ACR Data Science Institute, the partnership enables over 38,000 ACR members to leverage their own data to develop AI tools tailored to their specific needs. This development represents a significant boost to NVIDIA’s strategic layout in the healthcare sector.

Final Thoughts
Relying on continuous hardware advancements, NVIDIA’s position as the AI engine remains unshakable in the short term. In August 2019, NVIDIA’s AI platform achieved another major breakthrough in natural language models. It is worth noting that BERT is currently one of the best NLP models and has extremely high computational requirements. Compared with AlexNet in 2012, its computational scale has increased by 300,000 times.
NVIDIA used just a single server equipped with 1,472 V100 GPUs to reduce the training time for the BERT (Bidirectional Encoder Representations from Transformers) model from several days to merely 53 minutes. Subsequently, it completed AI inference in only 2.2 ms—well within the 10 ms threshold that meets the real-time requirements of most applications. Even with extensive optimization, CPUs still require over 40 ms to perform this task.
In just seven years, the scale of AI computation has grown by 300,000 times. To meet this surging computational demand and continue advancing its goal of becoming the “engine of modern AI architecture,” NVIDIA has proactively implemented significant changes. These extend beyond chip development to include hardware-integrated systems and diverse software stacks, all aimed at rapid deployment. The NVIDIA GTC conference will be held in Suzhou from December 16 to 19. VCBeat will continue to monitor what new breakthroughs NVIDIA unveils at the event.
To delve into “Applications of Federated Learning in Medical Imaging,” NVIDIA will host an online webinar from 20:00 to 21:00 on October 30. Interested participants are invited to scan the QR code below to register.

Scan QR Code to Register