NVIDIA Clara Advances in Medical Imaging and Genomics: Empowering AI-Driven Healthcare Innovation

NVIDIA
Artificial Intelligence Computing Service Provider
NVIDIA’s Annual GTC 2019 Event Concludes by Jinji Lake in Suzhou. On stage, Jensen Huang unveiled fewer hardware products this year, adopting a strategy of quality over quantity. Clearly, NVIDIA devoted more time and energy in mid-2019 to software development. With existing hardware already powerful enough, NVIDIA aims to enable developers to leverage their tools more efficiently.
In the medical field, NVIDIA currently positions itself as an assistant to healthcare AI developers. Simply put, NVIDIA does not directly engage in the research and development of medical applications; instead, it has developed a suite of toolkits to enable medical AI developers to better leverage data.
In this direction, NVIDIA has concentrated nearly all of its achievements within the NVIDIA Clara platform. Based on existing applications, the platform’s primary function is to help researchers in medical imaging and genomics address challenges related to data and computational power.
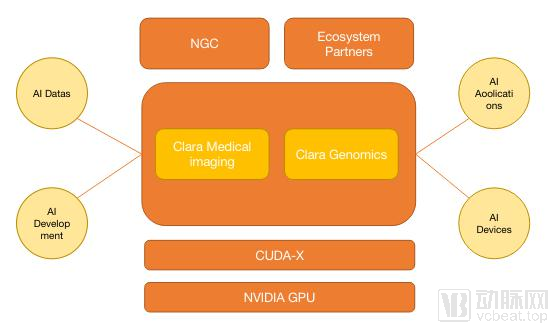
NVIDIA CLARA Architecture
Medical imaging is a primary application domain for NVIDIA Clara. Its toolkit offers functionalities such as transfer learning, federated learning, and real-time imaging. This section primarily introduces deep learning automation, federated learning, and NVIDIA’s efforts in optimizing PACS systems.
When deep learning was just emerging, the medical data accessible to artificial intelligence companies could hardly be considered big data. However, as medical AI enterprises have increasingly integrated into hospitals, they have gained access to more de-identified data through clinical and research collaborations.
Problems have thus arisen. Many enterprises process tens of thousands, or even up to 100,000, imaging cases per day; however, to enable AI to verify the correctness of its judgments or to improve the accuracy of AI algorithms, researchers must feed the AI with larger volumes of annotated data.
Based on the current market, AI companies typically recruit recent graduate students from hospitals to perform annotation tasks, at a cost of RMB 20–30 per data set. Interns usually take 20–40 minutes to process one set of low-level data; however, achieving more refined annotations requires 1–2 hours.
This data acquisition method presents two significant challenges. First, AI training requires large volumes of data, yet it is difficult for enterprises to recruit enough interns to perform annotations, resulting in prohibitively high costs. Second, image annotation typically demands highly qualified personnel; interns often miss nodules or make annotation errors, rendering the data obtained through this approach of limited value to enterprises.
To address this need, NVIDIA has integrated deep learning automation components into Clara, enabling developers to directly use these components for medical image segmentation.
NVIDIA’s experimental data show that, with the application of this toolkit, the time required for individual pulmonary nodule segmentation can be reduced to 8–15 minutes, and physicians’ delineation efficiency can be improved by 4–8 fold. Furthermore, rough estimates indicate that pancreatic delineation speed can be increased by 4-fold, and splenic delineation speed by 10-fold.
NVIDIA’s federated learning algorithms have a broad range of applications, with key use cases including autonomous driving and healthcare.
The security of medical data is self-evident. Many hospitals, even if they allow developers to use their de-identified data, do not permit the data to leave the hospital premises. This results in AI developers creating a separate model for each hospital they engage with; however, due to data heterogeneity, the robustness of these models varies significantly, making them difficult to apply in clinical practice.
Federated learning is designed to address the aforementioned issue. Although patient data cannot leave the hospital, models can. Therefore, can we directly aggregate these models? The answer is yes. The essence of federated learning algorithms lies in aggregating different models to achieve a unified model across multiple institutions without requiring patient data to leave the hospital.
During the model fusion process, NVIDIA employs a specialized encryption method to ensure that data within each model remains confidential and is not leaked.
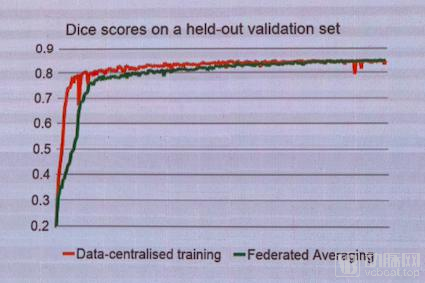
Through a fusion experiment involving 13 user groups, NVIDIA obtained the results shown in the figure above. The red line in the chart illustrates the changes in algorithmic accuracy generated by a single deep learning model, while the green line depicts the changes in algorithmic accuracy after fusing 13 models under federated learning. It can be observed that as the data volume increases, the two curves closely overlap. This experiment demonstrates, to a certain extent, the viability of federated learning.
However, new challenges continue to emerge. If there are significant discrepancies among various models, how can federated learning autonomously “filter out the noise and retain the signal”? “Incremental learning” will be a key focus of NVIDIA’s next phase of research.
To improve the efficiency of hospital PACS systems, NVIDIA has developed a PACS system optimization component that enables AI-based enhancement and reconstruction of raw images prior to their conversion into DICOM format, thereby generating higher-quality data within the PACS system. The specific architecture of Clara Deployment is shown in the figure below.
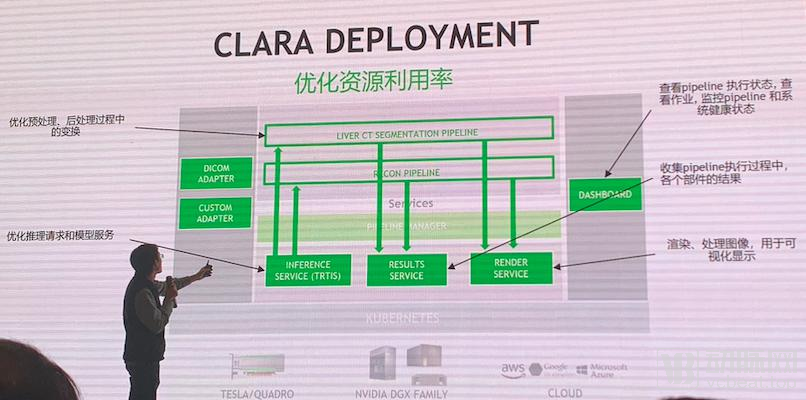
There are many applications for image enhancement of raw data, so what sets Clara Deployment apart? A radiologist told VCBeat that the difference between NVIDIA and Philips lies in the stage at which they process medical images. Philips’ image processing system operates before the PACS router, meaning enhancement is performed during image acquisition. In contrast, Clara Deployment’s processing occurs at a later stage and does not rely on the image processing capabilities of the imaging equipment itself.
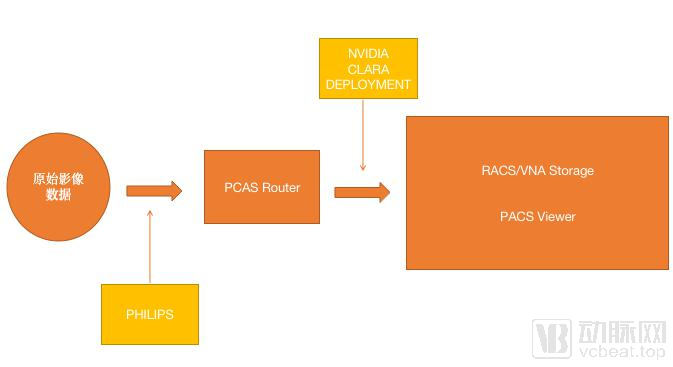
Raw imaging data enters the PACS workflow
Since the first human genome was sequenced in 2003, the cost of whole-genome sequencing has been declining at a rate far exceeding that predicted by Moore’s Law. From newborn genome sequencing to the launch of national population genomics initiatives, the field is flourishing and becoming increasingly personalized.
Advances in sequencing technology have triggered an explosive growth in genomic data. The total volume of sequence data doubles every seven months. This astonishing rate could lead to genomics generating more than ten times the combined data volume of other big data sources (such as astronomy, Twitter, and YouTube) by 2025, reaching double-digit exabytes.
Various new sequencing systems, such as BGI Group’s DNBSEQ-T7—the world’s largest genomics research consortium—are driving the widespread adoption of this technology. The system can generate up to 60 genomes per day, equivalent to 6 terabytes (TB) of data.
Leveraging the development of BGI Group’s flow cell technology and the acceleration provided by a pair of NVIDIA V100 Tensor Core GPUs, the DNBSEQ-T7 has achieved a 50-fold increase in sequencing speed, making it the highest-throughput genome sequencer to date.
However, the acceleration of sequencing is far from complete; scientists have put forth new demands as they observe the world at a more microscopic level. To meet these demands, NVIDIA continues to explore relentlessly.
The NVIDIA Parabricks genomics analysis package released at this GTC conference is designed to provide deeper insights into the molecular world.
Parabricks is a CUDA-accelerated genomic processing toolkit that can be used for variant discovery and produces results consistent with the industry-standard GATK Best Practices pipeline. Using this toolkit, relevant computations can be accelerated by 30–50 times, and deep learning can be leveraged for genomic variant detection.
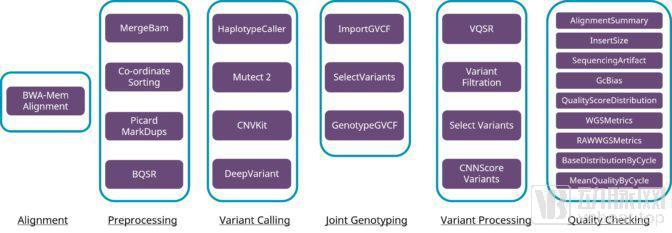 NVIDIA Parabricks: GPU-Accelerated GATK
NVIDIA Parabricks: GPU-Accelerated GATK
Today, BGI Genomics has begun using Parabricks. With several GPU servers, BGI Genomics can process genomes at the same rate as its sequencers generate data.
From the overall perspective of GTC, NVIDIA’s investment in medicine is not substantial; many applications were not specifically developed for healthcare but were instead generated through transfer.
Nevertheless, this does not hinder NVIDIA from powering the advancement of medical artificial intelligence. Whether it is federated learning, automated deep learning, or accelerated genomic processing, NVIDIA addresses the most fundamental and pressing challenges in the industry.
Looking back at the entire conference and the post-event interviews, “The more you buy, the more you save” was the phrase Jensen Huang repeated most often. However, in the fields of medical imaging and molecular science, what NVIDIA can deliver may well be “The more you buy, the more you see.”