VoxelCloud's IPO Prospectus Highlights Breakthroughs in Small-Data Learning for Medical Imaging AI
In recent years, the emergence of deep neural networks has, to some extent, disrupted the development trajectory of the medical imaging industry. With the integration of artificial intelligence, algorithms are gradually taking over the complex and repetitive tasks in imaging-related departments, offering hope for alleviating the shortage of physician resources.
However, AI also has its limitations. From the current development perspective, effective artificial intelligence algorithms are mostly concentrated on diseases with large amounts of standardized data. After all, to achieve high-quality AI diagnosis, a large number of high-quality labeled images are required for preliminary algorithm training.
These data-related characteristics limit the widespread application of medical AI. In reality, data on rare diseases and complex, refractory conditions are scarce, and data collection is further hindered by concerns over patient privacy and data security. Moreover, the annotation of medical images is costly; it often requires the development of specialized annotation tools and must be performed by experienced physicians. Due to these combined factors, high-quality annotated medical image datasets for certain clinical problems are extremely scarce, thereby impeding the development of corresponding AI solutions.
Fortunately, the challenges facing AI are not insurmountable. In retrospect, humans can identify novel entities from very few samples; can machines replicate this capability? The answer is likely yes. A series of small-data learning methods recently emerging in the field of medical AI aim to mimic human discriminative abilities. By reducing the volume of data required for recognizing specific target images, these approaches seek to ultimately overcome the problems of limited data availability and lack of standardized datasets in the medical domain.
To achieve few-shot learning, certain specific conditions must be met. For instance, the model must have already absorbed a substantial amount of data from existing categories before being exposed to only a minimal amount of data from new categories, thereby enabling the formation of a few-shot learning model. Therefore, the key to few-shot learning lies in incorporating appropriate prior knowledge into the algorithm.
In the medical field, positional prior information for organs is widely present across many medical imaging modalities. For instance, in CT images, the liver is primarily located in the upper right quadrant of the abdominal cavity, while the spleen resides in the upper left quadrant. Such positional priors are highly beneficial for AI-based identification of specific organ classes.
In their paper “Location Sensitive Local Prototype Network For Few-shot Medical Image Segmentation,” published at the top-tier conference ISBI 2021, VoxelTech proposed a location-sensitive local prototype network (see Figure 1) based on spatial prior information. The study constructed a training dataset using liver and spleen imaging data, then applied an algorithm that leverages such prior knowledge to the task of few-shot kidney image segmentation, thereby enabling AI model training through few-shot learning.
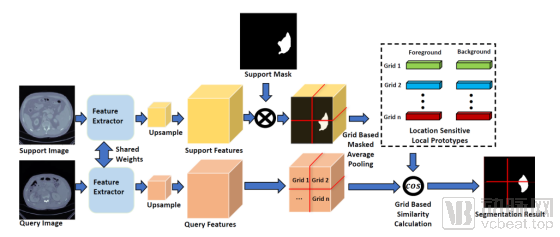
Figure 1: Framework of the Local Prototype Network Based on Location Prior Information
Experiments conducted on the publicly available CT organ segmentation dataset Visceral demonstrate that the proposed framework improves the Dice Score by 10% compared to current state-of-the-art methods, significantly advancing technical progress in the field of few-shot organ segmentation.
In addition to the difficulty of data acquisition, researchers also face the problem of inconsistent data sources during training.
Due to the diversity of imaging equipment, environments, and protocols used in medical imaging, there are significant differences in population distributions across hospitals and health examination centers. Consequently, it is challenging to collect and annotate sufficient training data to comprehensively cover image features from diverse sources. If there is a substantial distributional discrepancy (domain shift) between the training data and the actual test data, the resulting model often exhibits suboptimal performance.
VoxelTech’s paper “Extreme Consistency: Overcoming Annotation Scarcity and Domain Shifts,” published at the top-tier conference MICCAI 2020, provides a direction for addressing this issue. Specifically, the paper introduces the concept of extreme consistency, with the core idea being to incorporate extreme image transformations (such as substantial and intense adjustments in brightness, contrast, rotation, and scale) into the training data to enhance its diversity. This approach is based on the assumption that such extreme transformations do not alter the semantic meaning of the images. For example, blood vessels in fundus images still correspond to the vessels themselves even after undergoing extreme rotations and changes in brightness and contrast.
To realize this concept, the paper designs a semi-supervised algorithm (semi-supervised learning, see Figure 2) that enforces the constraint of semantic consistency before and after extreme variations, thereby enhancing the model’s robustness to distribution shifts. The proposed method was evaluated on the ISIC skin lesion segmentation dataset and two fundus vessel segmentation datasets (HRF and STARE), demonstrating its superiority in terms of robustness and accuracy under conditions of data scarcity and significant distribution shifts.
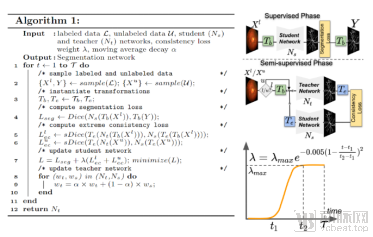
Figure 2: The left side shows the pseudocode for the semi-supervised learning method based on extreme consistency, and the right side illustrates the network architecture diagram.
In addition to issues concerning data sources, the segmentation and annotation of existing data also entail substantial costs for researchers. In China, image data annotation is extremely expensive, particularly for pixel-level medical image segmentation, which incurs even higher labor costs. Consequently, a significant body of recent research has aimed to address two typical problems found in imperfect medical image segmentation datasets:
·**Scarcity of Annotations.** Only an extremely small fraction of images in the dataset have segmentation annotations.
· Weak Labels. Image data in the dataset is only partially annotated, contains noisy annotations, or has only image-level class labels without pixel-wise segmentation annotations.
To address these two issues, the paper “Embracing Imperfect Datasets: A Review of Deep Learning Solutions for Medical Image Segmentation,” published by VoxelCloud in the top-tier journal Medical Image Analysis, provides a systematic and detailed review and categorical summary of existing approaches (as shown in Figure 3). Based on the specific deficiencies of medical image segmentation datasets, the paper offers practical guidance for selecting appropriate solutions.
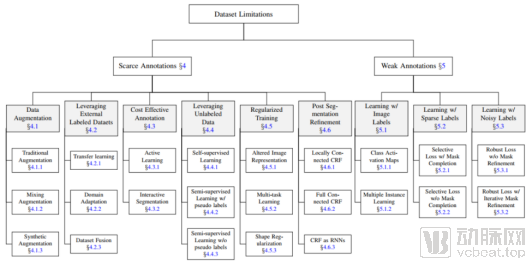
Figure 3: Summary of Dataset Defects in Medical Image Segmentation and Corresponding Training Strategies
In recent years, VoxelTech and the research team from Shanghai Jiao Tong University have collaborated to participate in multiple medical AI challenges, achieving outstanding results. The VoxelTech team secured third place in the macular localization task of the ADAM challenge, held at the ISBI 2020 academic conference. The ADAM challenge, jointly organized by Baidu Lingyi Zhihui and the Zhongshan Ophthalmic Center of Sun Yat-sen University, comprised four tasks, including macular localization, and attracted nearly 400 participating teams from more than 20 countries.

The macular region is a critically important functional area of the fundus. Precise localization of the macula is highly beneficial for further auxiliary diagnosis. A major challenge in this task is that many fundus diseases severely affecting vision occur in the macular region, causing significant morphological changes compared to normal maculae. This leads to insufficient robustness in existing common deep learning models for localizing pathological maculae. The Voxel Technology team innovatively designed a dual-stream network that fuses fundus images with corresponding vessel segmentation information. By leveraging the shape and orientation of retinal vessels to estimate macular location, this approach significantly improves the localization accuracy for severely diseased macular regions. In the ADAM competition finals, the model achieved an average macular localization error of 25 pixels (ranking third), demonstrating considerable clinical applicability.
In addition, the VoxelCloud team achieved outstanding results in the COVID-19 Lung CT Lesion Segmentation Challenge - 2020, ranking 2nd in the key pneumonia segmentation metric, Dice Score, and 3rd in the weighted ranking across all metrics.

The COVID-19-20 International Challenge was an international competition co-hosted by Children’s National Hospital, NVIDIA, the National Institutes of Health (NIH), and the Medical Image Computing and Computer Assisted Intervention Society (MICCAI). The challenge focused on the segmentation and quantification of lung lesions (primarily ground-glass opacities) caused by SARS-CoV-2 infection. It aimed to investigate the feasibility of using deep learning-based models for segmenting pneumonia lesions in the quantitative analysis of COVID-19 CT images, thereby aiding in the differential diagnosis of COVID-19. The COVID-19-20 International Challenge attracted more than 200 teams from 29 countries.
The award-winning COVID-19 segmentation model employs the nnU-Net framework, a deep learning architecture that has demonstrated outstanding performance across various medical image segmentation tasks. It performs automated optimization and parameter estimation for all stages of image segmentation, including image preprocessing, network architecture, and the learning process. To address the deviation in model optimization caused by noisy annotations and the prevalent foreground-background class imbalance in medical imaging, the VoxelTech team selected Noise-Robust Dice Loss as the optimization loss function. Ultimately, the model achieved a Dice Score of 0.6581 (ranking 2nd) on the same-source test set.