After a Decade of Losses, IBM Watson Health Files for IPO Amid Planned Divestiture
On February 18, The Wall Street Journal reported that International Business Machines Corp. (IBM) was exploring options to divest its Watson Health unit. Watson Health could potentially be sold to private equity firms or healthcare companies, or merge with a special purpose acquisition company (SPAC). At this juncture, IBM has little choice but to proceed.
A Brief History of Watson Health: The Origins Trace Back to 2011In 2011, IBM, equipped with certain natural language understanding capabilities, designated healthcare as the core focus for translating artificial intelligence research into practical applications, thereby embarking on the long journey of Watson Health. Throughout the AI training process, Watson learned from globally renowned medical institutions, including Memorial Sloan Kettering Cancer Center (MSK), Mayo Clinic, and Quest Diagnostics. In China, such resources would be considered imperial-level privileges. Yet, by the end of the story, Watson still failed to become a distinguished physician.
The collapse of the partnership with The University of Texas MD Anderson Cancer Center in 2017 marked a pivotal turning point in the shattering of the grand vision: to cultivate IBM’s envisioned virtual physician, MD Anderson fully covered IBM’s $62.1 million in R&D costs. After this substantial sum was exhausted, Watson still failed to achieve effective clinical application, plunging MD Anderson, which already faced financial constraints, deeper into a quagmire of fiscal distress.
Since then, Watson has undergone multiple rounds of large-scale layoffs, setting it on an irreversible path of decline. When asked about Watson today, a domestic distributor involved in the field declined to elaborate, merely remarking, “Everyone here considers it a failed product.”
From Global Acclaim to Quiet Demise: Watson’s Decade in Healthcare Is a Microcosm of Medical AI Development. After Burning Through Tens of Billions of Dollars, What Lessons Has Watson Truly Bought Us?
Let us return to the year Watson entered the healthcare sector. After IBM charted an ambitious course for it, the first mentor it engaged was the renowned Memorial Sloan Kettering Cancer Center (MSK). A mentor’s expertise shapes a student’s capabilities; thus, MSK, famed for its oncology care, naturally dictated Watson’s orientation. Coupled with IBM’s own transformation into a “cognitive solutions and cloud platform company,” Watson was tasked with becoming a virtual physician that “applies next-generation AI cognitive technologies to cancer treatment.”
In line with this vision, IBM Watson Health has successively developed three unique cancer treatment solutions to assist physicians worldwide in diagnosing and treating patients: Watson for Oncology, Watson for Clinical Trial Matching, and Watson for Genomics.
The names of the three solutions are shrouded in mystery, yet their content is straightforward to understand. The first, Watson for Oncology, is IBM’s best-selling product, designed to provide patients with multiple treatment options and augment the professional expertise of oncologists. The second, Watson for Clinical Trial Matching, helps identify suitable patients for drug clinical trials. The third, Watson for Genomics, leverages gene sequencing technology to enable precision cancer treatment.
IBM’s insights into AI are beyond doubt. Even today, these three objectives remain the primary directions for AI applications and continue to pose significant challenges. Therefore, the issue still lies with the product itself.
Let us first discuss the most important product, Watson for Oncology. This is a single-disease Clinical Decision Support System (CDSS) designed to perform multi-round assessments based on patient text and imaging data, combined with knowledge already acquired by Watson (covering 13 cancer types, including breast cancer, lung cancer, and colorectal cancer), and ultimately output results. Its specific processing logic is as follows.
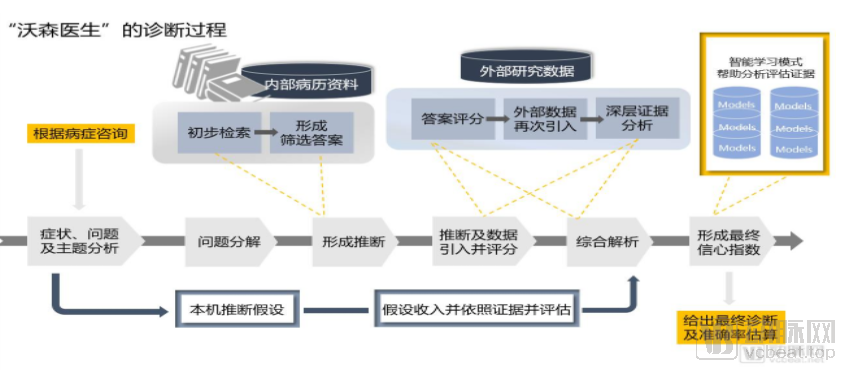
In practice, Watson’s diagnostic process can be broadly divided into four steps, namely:
1. Input medical records by entering patients' diagnostic data from multiple time points into the system, including structured data (such as electronic medical records) and unstructured data (such as medical images);
2. Analyze medical data, retrieve existing knowledge graphs, and search and analyze the input medical data to ultimately provide multiple potentially effective treatment plans for each patient;
3. Regimen ranking: Rank various treatment options according to credibility metrics.
4. Output Results: Ultimately, the patient receives a comprehensive report on recommended cancer treatment plans. This report includes several recommended options, alternative considerations, and non-recommended regimens, with detailed information on survival rates, incidence of adverse reactions, and drug interactions for each option, thereby helping doctors and patients understand the efficacy and risks associated with each treatment plan.
Watson “learns” by continuously adjusting its internal processing algorithms to yield high-probability correct answers for certain questions, such as identifying cancer in radiological images. The correct answers must be known in advance so that the system can be informed when it has made a correct or incorrect determination. The more training cases the system can process, the higher its accuracy rate becomes.
However, if the data itself is flawed, Watson’s diagnoses, which are based on this problematic knowledge, will naturally be compromised.
For AI systems that rely on knowledge graphs, the breadth and accuracy of knowledge determine the precision of the AI’s judgments. However, if knowledge is not adequately described, the trained AI will encounter issues. For example, if Knowledge A tells Watson that prolonged hospitalization increases the risk of deep vein thrombosis (DVT), while Knowledge B tells Watson that hospitalization is not the root cause of DVT, humans can easily distinguish the logic between these two statements, but AI cannot. As such logically contradictory descriptions accumulate, the accuracy of AI-assisted diagnosis will decline.
Another issue stems from errors inherent in the data itself. If we encounter a patient diagnosed with ovarian cancer whose recorded gender is male, would we still use this data for further clinical research? If we discover that more than twenty patients who underwent examinations on the same day all share the exact same date of birth in the pathology report summary, how extraordinary must such “coincidence” be? Before constructing any natural language processing (NLP) models, these inconsistencies that contradict standard medical logic and common sense must be resolved.
The third issue is the lack of ability to uncover knowledge hidden beyond existing data. For example, in the patient’s “one chief complaint and five histories,” researchers need to extract a field named “history of smoking.” The required annotation outcome is either “Yes” or “No.” Since these two terms do not appear explicitly in the medical records, it is necessary to deconstruct the logic by clarifying what information should be identified from the records to ultimately determine whether the patient has a history of smoking.
Watson failed to provide satisfactory solutions to the three aforementioned issues. Instead, IBM invested $4 billion in acquiring data companies such as Explorys, Phytel, and Merge Healthcare, and partnered with numerous renowned medical institutions. These extensive efforts significantly expanded Watson’s knowledge base but did not effectively enhance its logical reasoning capabilities.
Furthermore, Watson’s foundational “data” originates from MSK. Although IBM has global ambitions, MSK’s diagnostic approach may not be applicable to every region. Taking China as an example, differences in lifestyle, dietary habits, and even genetics lead to variations in diagnosis. Watson, with insufficient localization, struggles to adapt to these differences and provide accurate diagnostic results.
Moreover, judging from Watson’s reasoning process, its analysis requires the integration of structured electronic medical record data with unstructured imaging data, necessitating AI capabilities to handle heterogeneous data. In China, this is typically divided into two distinct stages of AI application, with separate AI systems responsible for computation at each stage; thus, Watson appears to have been overly hasty. Consequently, even with the support of the imaging AI company Merge Healthcare, Watson has, in the view of Chinese physicians at least, failed to deliver impressive results, offering only standardized recommendations that fall within the existing competence of clinicians.
Nevertheless, despite the lack of effective AI logic and automated algorithms for detecting data quality issues, Watson’s knowledge graph remains highly valuable. Watson has clearly recognized this, as evidenced by Watson for Clinical Trial Matching, which helps identify suitable patients for clinical drug trials, and Watson for Genomics, which enables precision cancer treatment through gene sequencing technologies.
Compared with AI-assisted diagnosis tools that are geared toward physicians, these two products place lower demands on logical reasoning and instead emphasize the richness of literature and data—conditions that Watson can fully meet. However, this also presents a challenge: if the entry barriers are too low, companies will struggle to build sufficient competitive advantage. The issue lies in the limited market size, as databases constitute the foundation for medical big-data firms, and competition is intense. In China, HLT and Inspur Health both offer services consistent with Watson for Clinical Trial Matching. Meanwhile, the market for Watson for Genomics does not impose high requirements on AI capabilities, with upstream sequencing institutions holding greater bargaining power.
Excessive hype has often drawn criticism to medical AI, with Watson setting a poor precedent in this regard. After defeating two of the greatest contestants in history on the American quiz show Jeopardy! in 2011, IBM made bold claims that “humans would be replaced.” As late as 2019, many healthcare AI entrepreneurs were still emphasizing that their AI systems were “not intended to replace physicians, but to empower them.”
This error encompasses two issues: first, it raised excessive expectations among investors, physicians, and even hospitals, thereby exacerbating the psychological disappointment of purchasers when product defects emerged; second, the product failed to adhere to a “human-centered” design philosophy, making it difficult to integrate into actual clinical workflows and thus unable to effectively alleviate physicians’ burdens and empower their practice.
Next is the issue of revenue. According to data provided by The Wall Street Journal, Watson’s annual revenue stands at $1 billion, a figure that is somewhat eye-catching.
Let us perform a simple calculation using 2019 data. Currently, the annual revenue of leading medical AI startups stands at approximately RMB 100 million. AI unicorn Unisound reports an annual revenue of RMB 219 million, while Yitu Technology’s annual revenue reaches RMB 717 million. Winning Health Technology Group generates RMB 1.9 billion in revenue. It takes the combined revenues of numerous such companies to match IBM Watson Health’s global revenue of RMB 6.5 billion.
Examining another set of data, The Wall Street Journal once revealed that the largest AI product in IBM’s Watson Health portfolio was Watson for Oncology. IBM typically charged $200 to $1,000 per patient, with consultation fees required in certain cases. According to a report by Shuzhi Wuyu (Digital Intelligence Stories), Fu Gang, Chairman of Baiyang Pharmaceutical Group, stated in a 2017 interview that patients bore the full cost of using the Watson oncology solution, at a price of RMB 4,500 per case. IBM reported that, as of the end of June 2018, the number of patients using Watson for Oncology had reached 84,000. Based on a 20% patient growth rate, the patient-side revenue from Watson for Oncology was estimated to generate approximately RMB 550 million in total income for IBM, far below the figure of $1 billion per year.
In November 2018, Watson, which was in a state of decline, had been deployed in nearly 80 hospitals across 43 cities in China, slightly lagging behind leading AI companies. Based on these figures, the revenue generated by Watson remained far short of recouping its tens-of-billions-level investment.
There is another issue that cannot be overlooked:Why would patients prefer an expensive virtual doctor for diagnosis over a more affordable chief physician?
Internally and externally, we can broadly categorize the issues with Watson into four points.
I. During the large-scale acquisition process, Watson’s workforce became significantly bloated. Following the MD Anderson incident, the Watson division reduced its staff by 50% to 70%, with the layoffs primarily affecting employees from the three acquired companies: Phytel, Explorys, and Truven.
2. Questions Remain Regarding Diagnostic Accuracy and Safety. In 2018, internal IBM documents were leaked, with multiple cases suggesting that Watson Health lacked accuracy and safety. In fact, over the course of a decade, Watson never received FDA approval, and IBM did not publish any scientific papers demonstrating how this technology impacted physicians and patients.
III. Issues with the Dataset. The dataset exhibits cognitive bias, lacks effective logical reasoning, and is deficient in quality control and localization optimization.
IV. Virtual Diagnosis Is a Pseudo-Demand; “Money-Burning Doctors” Are Not Profitable.
Now that IBM has shifted its strategy toward AI and hybrid cloud, abandoning Watson as a strategic asset has become inevitable. However, the decline of Watson does not signify the decline of AI itself; over the past decade of ups and downs, we have gleaned many valuable insights from this journey.
First, let us define AI. Accustomed to the concept of “Internet+,” we often use “AI+” to describe its medical applications. However, the internet itself constitutes a scenario, whereas current AI represents merely a specific application within a particular medical scenario—a technology serving that scenario. A more accurate term would be “+AI.” In other words, we should tailor requirements based on specific medical scenarios, rather than developing an AI algorithm and forcibly integrating it into a given workflow.
The benefits are evident. Insights from the development of the health informatics industry suggest that while healthcare requires AI, its need is not as absolute as often perceived. Current informatization policies emphasize data collection, organization, cleaning, reporting, analysis, and quality control across various accreditation frameworks. Many of these processes, particularly analysis and quality control, are difficult to achieve manually and necessitate data processing via NLP-based knowledge graphs. Although AI is seldom explicitly discussed in these contexts, it has become an indispensable component of next-generation information systems.
Revisiting Knowledge Graphs. To truly unlock the value of large-scale clinical electronic medical records, it is not sufficient to simply aggregate data as Watson did; rather, numerous challenges must be addressed. Among these, data quality governance, structured information extraction, and data normalization and standardization are particularly difficult to manage. These issues cannot be scaled through manual efforts alone and must be supported by natural language processing (NLP) technologies. This requires not only NLP algorithms, computational techniques, and engineering capabilities but also substantial medical domain expertise. Therefore, to achieve effective diagnosis, these problems must be resolved individually to construct robust logical frameworks.