Building and Deploying a Mask Detection Application Using NVIDIA NGC Collections

NVIDIA
Artificial Intelligence Computing Service Provider
AI workflows are complex. Building an AI application is not a simple task, as it requires the involvement of various stakeholders with domain expertise to develop and deploy applications at scale. Data scientists and developers need convenient access to software building blocks, such as models and containers, that are not only secure and high-performance but also provide the infrastructure necessary for building their AI models.
After building the applications, DevOps and IT managers need tools that can help them seamlessly deploy and manage these applications across various devices, including on-premises, cloud, or edge devices.
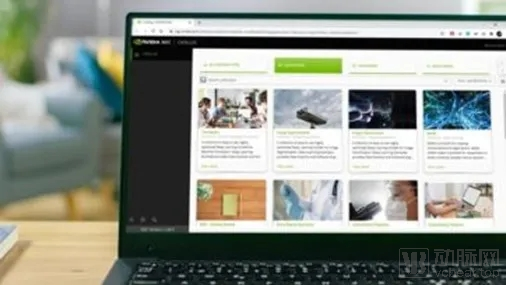
NVIDIA has built the NGC Catalog to simplify and accelerate AI workflows by providing easy access to GPU-optimized software, such as containers, pre-trained models, application frameworks, and Helm charts required for building AI applications.
In this article, we will demonstrate how to leverage the NGC Catalog and its core underlying features—such as collections, the NGC Private Registry, and AI Building Blocks—to build and deploy a face mask detection application. This example illustrates a complete development-to-deployment pipeline.
With the launch of NGC, NVIDIA has streamlined the entire user experience by consolidating the necessary containers, models, code, and Helm charts in one place, eliminating the need to locate and orchestrate various independent building blocks across catalogs.
You can find NGC collections for task-specific workloads, such as automatic speech recognition or image classification, as well as industry SDKs like NVIDIA Clara or the Transfer Learning Toolkit (TLT). If you wish to build an application for object detection, simply search for the relevant collection in the catalog, and you will find all related assets in one place.
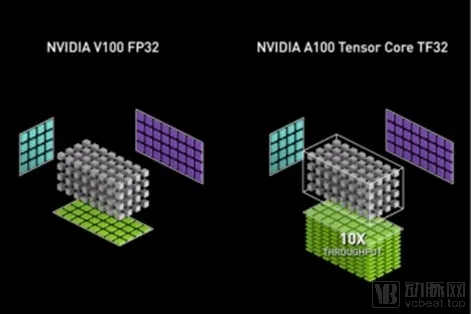
The NVIDIA Ampere GPU architecture introduces third-generation Tensor Cores and a new TensorFloat-32 (TF32) mode that accelerates FP32 convolution and matrix multiplication. TF32 mode is the default option for AI training with 32-bit variables on the Ampere GPU architecture. It brings Tensor Core acceleration to single-precision deep learning workloads without requiring any changes to model scripts.
Mixed-precision training using the device’s native 16-bit format (FP16/BF16) remains the fastest option, requiring only a few lines of code in the model script. Table 1 shows the mathematical throughput of A100 Tensor Cores compared with FP32 CUDA cores. It is worth noting that for single-precision training, the A100 delivers 10× higher mathematical throughput than its predecessor, the V100 training GPU.
TF32 is a new computation mode introduced in the Tensor Cores of the Ampere GPU architecture. For dot product calculations, which form the building blocks of matrix multiplication and convolution, it rounds FP32 inputs to TF32, computes the products without loss of precision, and then accumulates these products into FP32 outputs.
TF32 is exposed solely as a Tensor Core operation mode, not as a data type. All memory storage and other operations remain entirely in FP32; only convolutions and matrix multiplications convert their inputs to TF32 prior to multiplication. In contrast, 16-bit types provide storage, various mathematical operators, and more.