ITBT Cross-Disciplinary Integration Gains Momentum: A New R&D Paradigm Poised to Reshape the Future of Biopharmaceuticals
With the convening of the inaugural China Bio-Computing Conference, ITBT has once again been thrust into the industry spotlight. Robin Li, Founder, Chairman, and CEO of Baidu, as well as Founder and Chairman of Biotope, delivered the opening address. Distinguished scientists, including Academicians Weinan E, Yigong Shi, Chen Dong, and Weihong Tan from the Chinese Academy of Sciences, delivered keynote speeches, drawing widespread attention within the industry.
The conference organizer, BioMap, is China’s first life sciences platform company driven by biological computing technology, founded by Robin Li last year. AndBiological computing is precisely the core meaning of “ITBT.”。
ITBT is a new concept derived from artificial intelligence and big data, representing an organic integration of information technology (IT) in computational science and biotechnology (BT) in life sciences, with a focus on big data algorithm-driven biopharmaceutical development.
Computational science and life sciences were originally two parallel, independent fields. However, with the rapid advancement of computational science in recent years, these previously unrelated sectors have increasingly intersected: computational science has begun to serve as a tool empowering life sciences, thereby accelerating the efficiency and enhancing the quality of new drug development. This cross-disciplinary integration has given rise to the concept of “ITBT.”
The inaugural China Biocomputing Conference also seemed to convey a signal:ITBT has already emerged as an independent sub-sector, with the potential to reshape the future R&D models and market landscape of the biopharmaceutical industry.。
Faced with such a hot emerging sector, many in the industry are watching with anticipation. Why did ITBT emerge? What disruptions will its rise bring to traditional biopharmaceutical models? Which biocomputing companies exist globally? What challenges will they face in their future development, and how can they break through?
Initial exposure to ITBT may feel unfamiliar, but the concept of medical AI empowering new drug development is already well known. The “computational IT” in ITBT refers to computing in a broad sense, encompassing artificial intelligence and machine learning. This means that,ITBT belongs to the broad medical AI sector.。
Beyond AI-enabled drug discovery, applications of medical AI also encompass healthcare informatics, intelligent diagnosis and treatment, and medical imaging. Among these, adoption in healthcare informatics emerged earliest, intelligent triage has achieved the broadest application, and medical imaging is witnessing the most rapid development. In contrast, although AI’s entry into drug discovery lagged behind other sectors, it commands a substantial market size.Accounting for over 35% of the total artificial intelligence market share。
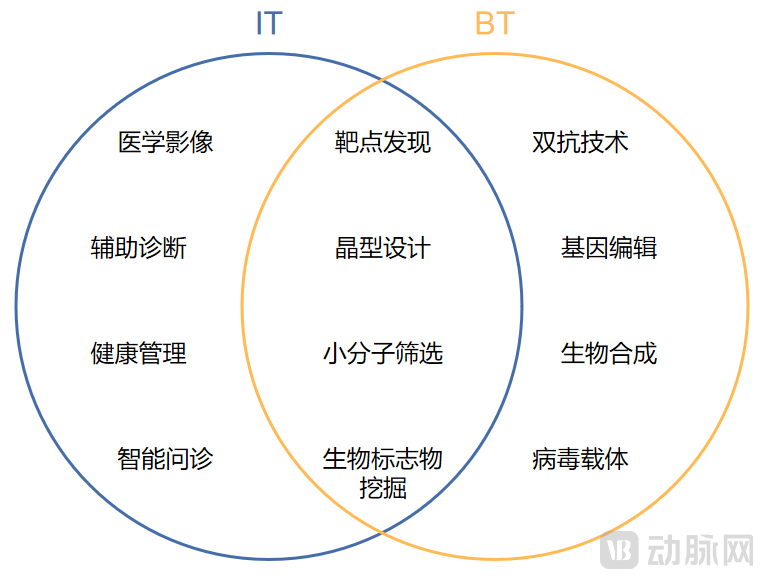
In recent years, to delineate the specialized sub-sectors of medical AI across various scenarios, investment institutions have defined medical AI in the context of new drug development as “ITBT.” 5Y Capital was among the first domestic investment firms to propose the ITBT concept. As early as 2017, it recognized the potential of this sector and made early investments in ITBT companies such as XtalPi, Xbiome, Xing Kang Yuan, Starpharm, and DrugAI.
Tracing the development history of the ITBT industry requires a return to the trajectory of China’s new drug R&D and the evolution of artificial intelligence. In 2015, the Chinese pharmaceutical sector witnessed the notable “July 22 Incident,” which propelled domestic pharmaceutical companies toward innovative drug development. Subsequently, 2017 was hailed as the inaugural year for innovative drugs in China, marked by the frequent introduction of approval policies for new drug clinical trials and market launches, leading to a large number of new drugs being approved to enter clinical trials.
If innovative drugs are the seeds, then artificial intelligence is the soil. Also in 2017, the State Council issued the “Notice on Issuing the Development Plan for the New Generation of Artificial Intelligence,” emphasizing the use of artificial intelligence to carry out large-scale genomic identification, proteomics, metabolomics, and other research as well as new drug development, and to promote intelligent pharmaceutical regulation.
Biocomputing (ITBT) began to take root at this juncture, with its growth hinging critically on information technology (IT). “Breakthroughs in computational methods herald a revolution in human cognition,” stated Academician Shi Yigong at the inaugural China Biocomputing Conference. “With the advent of artificial intelligence, this century will witness disruptive transformations!”
These changes are already becoming apparent in ITBT. With the rapid development of computational science in China, supercomputers, algorithm optimization, and the continuous accumulation of medical big data have collectively created the ideal conditions—favorable timing, geographical advantages, and human resources—for the advancement of ITBT.
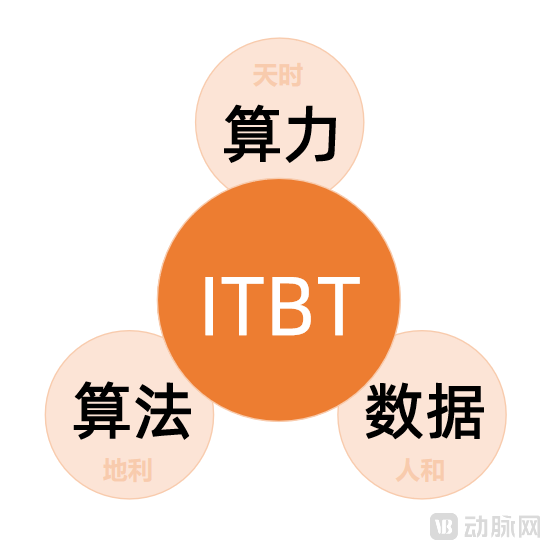
“The development of biological computing bears a striking resemblance to the evolution of the internet. Three key metrics drove the growth in internet search volume: the number of internet users, time spent online, and the number of web pages. Similarly, the field of biological computing is propelled by three analogous key indicators,” said Robin Li, using a straightforward analogy to explain the driving forces behind the development of the ITBT (Information Technology-Biotechnology) industry at the inaugural China Biological Computing Conference.Driving the Development of the ITBT Industrycorrespond to the three key indicators, respectivelyComputing Power, Algorithms, and Data。
FromComputing PowerFrom a broader perspective, China’s computational power has reached world-class levels. China is home to six national supercomputing centers, located in Wuxi, Tianjin, Jinan, Shenzhen, Changsha, and Guangzhou, respectively. Among them, the Sunway TaihuLight supercomputer at the National Supercomputing Center in Wuxi achieved a computing speed of 125.4 petaflops (12.54 quadrillion calculations per second) in 2016, becoming the fastest supercomputer globally. It provides computational and technical support for fields such as biomedicine, financial analysis, and information security in China.
FromAlgorithmFrom a broader perspective, various machine learning algorithms are undergoing continuous iterative optimization. As the core of artificial intelligence, these algorithms uncover the hidden relationships between drugs and diseases, as well as between diseases and genes, thereby building robust underlying computational architectures. Through constant trial and error alongside practical application, they are progressively refined, ultimately enabling the algorithms to align ever more closely with authentic human logic.
FromDataFrom a broader perspective, human biomedical research has accumulated vast amounts of medical data, including genomics, transcriptomics, proteomics, metabolomics, and small-molecule data. These data are derived not only from the extensive body of publicly available medical literature but also from proprietary databases independently developed and accumulated by pharmaceutical companies and contract research organizations (CROs). With the advancement of diverse human observational techniques, the volume of accessible biological indicator data is increasing, and even larger-scale multi-omics datasets are expected to be generated in the future.
“As medical data continues to accumulate, we appear to have reached a critical threshold: integrating sufficient biological data and leveraging AI as a bridge can significantly accelerate new drug development,” said Le Song, Chief AI Scientist at BioMap. “We are eager to collaborate with peers in the pharmaceutical and biocomputing industries to identify new avenues where AI can facilitate drug discovery.”
With the enhancement of China’s computational power in computing science, the refinement of algorithms, and the cumulative accumulation of medical big data over the years, the ideal conditions have converged to foster the emergence of ITBT (Information Technology–Biotechnology integration). Tan Guangming, Director of the High-Performance Computing Center at the Institute of Computing Technology, Chinese Academy of Sciences, affirmed that shifting drug development from experiment-driven to digital-driven approaches, thereby enabling the supply side to deliver high-quality and efficient products, represents a highly promising trend.
Traditional pharmaceutical companies rely on empiricism for drug development, which not only results in low success rates but also poses challenges such as prolonged development cycles and high costs. From clinical discovery to market approval, a new drug...Average duration: 10–15 years,R&D Costs Reach $3 Billion,The average success rate is less than 10%.。
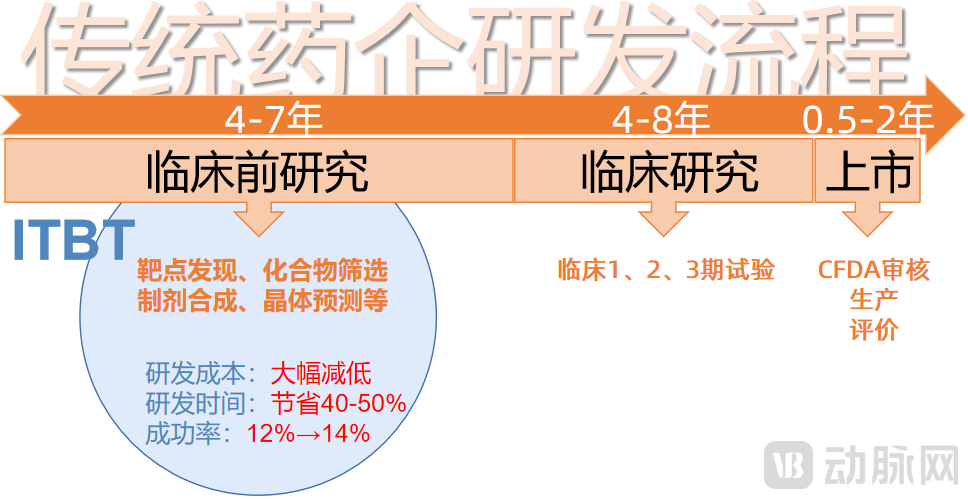
The emergence of the ITBT model may change this status quo. As the fastest-growing and most promising market within AI healthcare applications, new drug development, empowered by computational science and information technology (IT), can leverage its advantages in algorithms and computing power to assist multiple stages of the drug discovery process, thereby accelerating target identification, compound synthesis, formulation development, and crystal structure prediction.
This form of support is, in essence, a process of “digitalization.” Zhao Yu, Deputy Director of the Zheyuan-Turing-Darwin Laboratory at the Institute of Computing Technology, Chinese Academy of Sciences, told VCBeat: “Digitalizing cellular functions, disease mechanisms, drug mechanisms, and patient data on computers enables high-dimensional ‘patient-drug matching.’”
InTarget DiscoveryIn this context, ITBT leverages natural language processing (NLP) techniques to retrieve and analyze vast unstructured databases of literature, patents, and clinical trial reports, identifying potential yet overlooked correlations between pathways, proteins, mechanisms, and diseases. This enables the generation of novel, testable hypotheses for the discovery of new mechanisms and therapeutic targets.
InCrystal Form PredictionFurthermore, ITBT can leverage cognitive computing to achieve efficient, dynamic configuration of drug polymorphs and predict all possible polymorphic forms of small-molecule drugs. Polymorphic changes can alter the physical and chemical properties of solid compounds, leading to variations in clinical efficacy, adverse effects, and safety profiles, thereby posing challenges to drug development.
AtCompound ScreeningLeveraging the powerful computing capabilities of IT, virtual screening can be performed on candidate compounds to more rapidly identify those with higher activity. According to data from 36Kr’s “AI + Healthcare” industry research report, AI-assisted virtual screening of compounds can, on average,Save 40-50% of the time,Annual Savings of ¥26 Billion in Compound Screening Costs。
Theoretically, integrating IT technologies into the drug development process and leveraging deep learning to analyze and process molecular structures can establish highly accurate prediction systems across various stages of R&D. This approach reduces uncertainty at each stage, thereby shortening the development cycle, lowering trial-and-error costs, and improving the success rate of drug development. According to a report by TechEmergence, projects involving artificial intelligence technologyNew Drug Development Success Rate Can Increase from 12% to 14%。
Driven by ITBT, the traditional biopharmaceutical industry will undergo diversified structural changes, which can be primarily interpreted from two perspectives: pharmaceutical companies and CRO/CDMO service providers.

On the pharmaceutical company side, the entry of ITBT will accelerate competition in the new drug R&D market, particularly inSmall-Molecule DrugsFurthermore, given that the R&D logic for small-molecule drugs is more linear and intuitive than that for large-molecule biologics, information technology (IT), through multidisciplinary integration, can enable the rapid identification of optimal small-molecule compounds for promising reserve targets from academic research institutions—even protein targets whose structures have not yet been determined by scientists.
A relevant executive from WuXi AppTec also affirmed the positive impact of ITBT on the field of small-molecule drug discovery at the inaugural Bio-Computing Conference. ITBT-driven pharmaceutical companies can generate batches of small-molecule candidate compounds targeting specific biological targets. With the optimization of algorithmic engines, each generation of candidate drugs exhibits synergistic effects, working together to support the iterative development of superior therapeutics.
In the long run, enterprises leveraging ITBT hold a comparative advantage over traditional small-molecule drug R&D companies in identifying small-molecule compounds for specific targets, thereby generating more pronounced head-scale effects at the drug discovery stage.
However, Zhang Chunming, Executive Vice Dean of the Western Institute of Advanced Technology at the Institute of Computing Technology, Chinese Academy of Sciences, also pointed out that ITBT’s digital therapeutics experimental platform will not directly replace pharmaceutical companies. Instead, it will operate according to the 80/20 rule: 80% of the work is performed computationally, while the remaining 20% still requires human intervention. Nevertheless, companies adopting computational medicine technologies will inevitably displace those that do not; such is the trend.
From the perspective of CROs/CDMOs, some ITBT companies choose to focus on a specific stage of new drug development, providing technical services based on that stage—such as compound screening, molecular design, and crystal structure prediction—to pharmaceutical companies or medical institutions, thereby accelerating the new drug development process.
This model of providing “computing services” represents a new type of CRO/CDMO. Such ITBT enterprises implement diverse business models in their practical collaborations with pharmaceutical companies; for instance, some may partner through compound intellectual property (IP), jointly advancing the IP from clinical trials to market launch.
Although it is a brand-new concept, the convergence of IT and BT has not emerged only in recent years. Enterprises have been leveraging computational science to empower biopharmaceuticals for several years. Yudo Bio, XtalPi, and Zheyuan Technology are among the earliest domestic companies in the field of biological computing. With the advancement of artificial intelligence technologies and the accumulation of medical data resources, an increasing number of new enterprises have entered the IT-BT sector. Star Pharmaceuticals, founded in 2019, and Bioto Biosciences, established in 2020, both conduct exploratory research and development in biomedicine based on big data mining in healthcare.
VCBeat has conducted a brief overview of companies worldwide involved in ITBT:
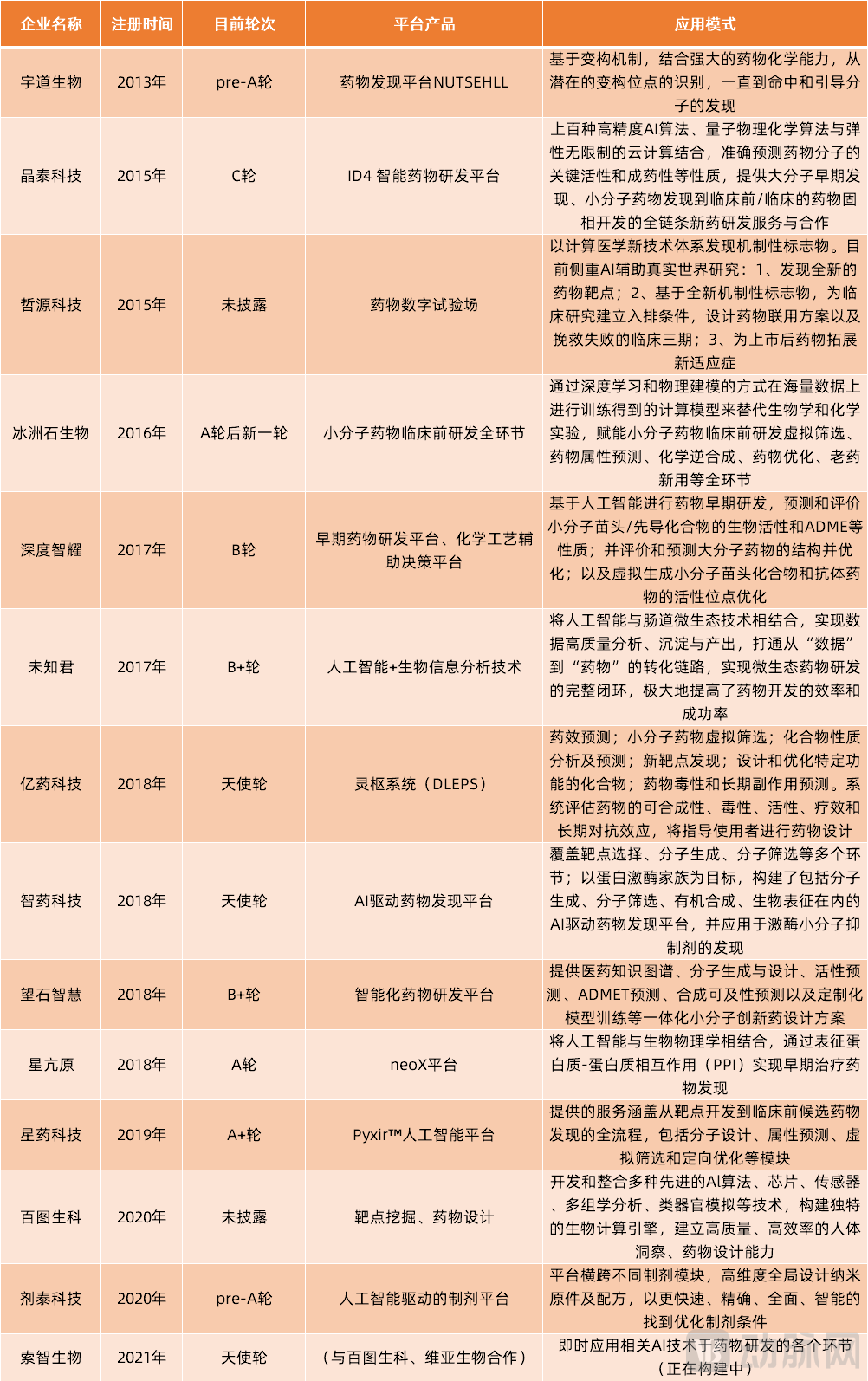
Overview of Typical Chinese Companies Involved in the ITBT Sector
As can be seen, among the 14 typical Chinese enterprises involved in ITBT drug R&D that we have compiled,Eight companies not only possess independent ITBT technological capabilities but have also independently established their own clinical-stage novel drug pipelines based on these capabilities., namely Yudao Biotech, Iceland Spar Biotech, Xbiome, Yiyao Tech, Zhiyao Tech, Xingkangyuan, Xingyao Tech, and Suozhi Biotech;
Additionally6 companiesXtalPi, Zheyuan Technology, DeepIntel, WisdomRock, BioMap, Jitai TechnologyMore focused on providing drug development services, such companies place greater emphasis on leveraging their AI expertise to collaborate with pharmaceutical firms, jointly building and advancing drug pipelines.
Notably, concurrent with the inaugural China Bio-Computing Conference was the announcement of a collaboration between Biotree and Suozhi Medical. Biotree focuses on building bio-computing engines, such as AI algorithms, while Suozhi Medical was established with the joint support of Biotree and Viva Biotech, aiming to create a new paradigm for drug discovery powered by artificial intelligence.
Meanwhile, some large pharmaceutical companies and CRO/CDMO firms have also begun to expand their presence in the ITBT sector through collaborations, mergers, and acquisitions. For instance, WuXi AppTec invested in Insilico Medicine, a company that combines reinforcement learning with generative adversarial networks (GANs) for molecular discovery; Chia Tai Tianqing partnered with Alibaba Cloud’s medical AI division to obtain novel machine-learning-based compound screening methods.
In 2018, Roche acquired Flatiron Health, a cancer big data company, for $1.9 billion to provide the data and technical support needed for R&D, accelerating the launch of new drugs; in 2019, Jiangsu Hansoh Pharmaceutical partnered with Atomwise, a U.S.-based AI drug discovery company, to jointly design and discover potential candidate drugs targeting up to 11 undisclosed proteins across multiple therapeutic areas. It is reported that all of the world’s top ten pharmaceutical companies have entered the ITBT sector.

Representatives of Selected Overseas ITBT Companies
Atomwise: Compound Screening
Founded in 2012 and headquartered in San Francisco, USA, Atomwise is an AI-driven pharmaceutical company that leverages supercomputing for drug discovery. The company employs supercomputers, deep learning, and sophisticated algorithms to simulate the human analysis of compound molecules, screening potential drug candidates from tens of millions of options. This approach accelerates compound screening and new drug discovery while reducing research and development costs.
On August 11, 2020, the company secured $123 million in Series B financing, co-led by B Capital Group and Sanabil Investments of Saudi Arabia’s Public Investment Fund. Existing investors, including DCVC, BV Baidu Venture Capital, Tencent, Y Combinator, Dolby Family Ventures, and AME Cloud Ventures, continued to increase their investments. On October 6 of the same year, Atomwise received a $2.3 million grant from the Bill & Melinda Gates Foundation.
It is reported that Atomwise plans to further expand its collaborations with biopharmaceutical companies such as Eli Lilly, Bayer, Hansoh Pharmaceutical, BridgeBio Therapeutics, StemoniX, and SEngine Precision Medicine. To date, Atomwise has signed co-development agreements with its corporate partners valued at approximately $5.5 billion.
Exscientia: Small Molecule Compound Design
Founded in 2012 and headquartered in Oxford, UK, Exscientia is an automated AI-driven drug design company. Its platform leverages big data and machine learning techniques to automatically generate millions of small-molecule compounds targeting specific biological targets, based on existing drug discovery data. These compounds are then evaluated and screened according to criteria such as efficacy, selectivity, and ADME (absorption, distribution, metabolism, and excretion) properties. By integrating various algorithms, the company aims to reduce the drug development timeline from 4.5 years to just one year, while significantly decreasing the number of compounds that need to be considered in the early stages.
On April 27, 2021, Exscientia announced the completion of its $225 million Series D financing round, led by SoftBank Vision Fund 2, with participation from Novo Holdings and funds under BlackRock, the lead investors in the previous round. Other investors included Mubadala Investment Company, Farallon Capital, Casdin Capital, GT Healthcare Capital, Marshall Wace, Pivotal bioVenture Partners, Laurion Capital, Hongkou, and Bristol Myers Squibb. Meanwhile, SoftBank also provided an additional equity commitment worth $300 million, at Exscientia’s discretion.
Just a month earlier, on March 4, Exscientia completed a $40 million Series C financing round, with investors including funds under BlackRock, Novo Holdings, Evotec, Bristol Myers Squibb, and GT Healthcare Capital. Meanwhile, Exscientia has actively established drug discovery partnerships with Bristol Myers Squibb, Sanofi, Bayer, Sumitomo Dainippon Pharma, and multiple biotechnology companies.
Genesis Therapeutics: Molecular Generation and Property Prediction
Genesis Therapeutics, founded in 2019 and headquartered in San Francisco, USA, is a biopharmaceutical company dedicated to leveraging AI technology to drive the discovery and development of novel small-molecule drugs. The company combines novel deep neural networks, biophysical simulations, and large-scale scalable computational infrastructure to achieve automated molecular generation and property prediction. Reportedly, the company evolved from an AI technology platform developed by Dr. Feinberg while working in Dr. Vijay Pande’s laboratory at Stanford University, and was established after validation through a collaboration between Stanford University and Merck Research Laboratories.
On December 2, 2020, Genesis Therapeutics announced the completion of a $52 million Series A financing round, led by Rock Springs Capital, with participation from T. Rowe Price Associates, Andreessen Horowitz, Menlo Ventures, Radical Ventures, Felicis Ventures, Jazz Venture Partners, Harpoon Ventures, Ulu Ventures, Propagator Ventures, and Open Field Capital.
The company has actively collaborated with biopharmaceutical companies worldwide. In October 2020, it entered into a multi-target collaboration agreement with Genentech, a subsidiary of Roche, to leverage Genesis Therapeutics’ expertise in graph machine learning and drug discovery. The partnership aims to identify innovative candidate drugs for therapeutic targets across multiple disease areas and jointly develop novel therapies.
Redesign Science: Small-Molecule Screening for Protein Targets
Redesign Science, founded in 2017 and headquartered in New York, USA, is dedicated to studying difficult-to-drug protein targets through powerful cloud-based parallel molecular dynamics simulation technology. The company’s proprietary AlphaSpace physics engine enables ultra-long-timescale molecular dynamics simulations of drug target proteins at atomic-level precision, facilitating the rapid screening of hundreds of millions of small molecules. By integrating classical mechanics with quantum mechanics, Redesign Science can perform rapid, high-precision modeling of any protein target, even those lacking structural data.
The company completed a multi-million-dollar seed funding round on October 15, 2019, led by Notation Capital, with participation from Morningside Venture Capital (now Five Source Capital), Third Kind Venture Capital, Refactor Capital, and others.
Meanwhile, Redesign Science has established multiple new drug development collaborations in disease areas such as cancer and inflammatory bowel disease (IBD). Through joint research with partners on a variety of diseases, Redesign Science plans to leverage its AlphaSpace physics engine to uncover previously unknown mechanisms of protein function and develop novel small-molecule drugs for disease treatment.
Although the sector is booming, ITBT remains in its early stages in China, facing numerous pain points and contradictions that urgently need to be addressed. On the IT side,Data Sources and Storage Issuesis one of them.
“Although data production has become industrialized, the capacity to understand and utilize data remains severely lacking, a deficiency that is particularly pronounced in the fields of biology and medicine.” Zhao Yu, Deputy Director of the Zheyuan-Turing-Darwin Laboratory at the Institute of Computing Technology, Chinese Academy of Sciences, believes that for some pharmaceutical companies, big data is not a tool but a quagmire.
Data serves as the cornerstone of ITBT development, encompassing multidimensional data acquired through various detection methods. “Previously, it was difficult to effectively integrate multidimensional data; however, with the incorporation of AI, multi-omics data can now exert a positive impact on disease diagnosis and target research,” stated Jiang Zhaoshi, Vice President of BioMap. “Massive databases play a crucial role in clinical drug target research.”
These data sources are primarily categorized into public and non-public domains. Public datasets encompass a vast array of scientific literature, patents, clinical trial reports, and more. However, such open-source data often lacks sufficient standardization, and as its granularity becomes increasingly fine, certain errors may obscure underlying patterns. “Developing more systematic datasets is a key direction that BioMap, as a biocomputing company, is striving to explore,” stated Liu Wei, Co-founder and CEO of BioMap.
Non-public data, such as the drug R&D data accumulated over many years by large pharmaceutical companies leveraging their proprietary technologies and R&D infrastructure, can also empower drug development. However, such data are scarce resources within the industry, and ITBT enterprises often have to access them through business collaborations and other means.
In terms of data storage, current solutions are primarily based on localized and cloud-based storage. With the anticipated growth in medical data, it is projected that by 2025, the volume of data generated in China requiring storage could reach over 20 exabytes (EB). Consequently, data storage and encryption will become critical challenges that ITBT enterprises must address for their long-term development.
On the other hand, while the ITBT model has accelerated the efficiency of new drug development, how should pharmaceutical companiesFrom Efficiency Gains to Ultimate Quality Improvement, namely, improving the success rate of clinical drug development is also a major challenge that ITBT companies need to address.
A relevant executive at WuXi AppTec noted that computing in the pharmaceutical industry is not merely a linear progression from 1 to 1, but offers numerous opportunities for advancement. At the first level, the most straightforward path of ITBT (IT-Biotech) is to identify suitable ligands for known targets. At the second level, ITBT leverages targets and pathways to design novel drugs, thereby enhancing the overall clinical success rate of drug development. At the third level, ITBT utilizes massive datasets to discover new indications and therapeutic approaches, moving beyond the reductionist paradigm of “one target, one molecule.”
Currently, the IT-BT industry remains largely at the first level, with traditional pharmaceutical companies and the IT sector in the process of integration, primarily focused on improving the efficiency of drug R&D. However, enhancing efficiency is only the initial step; progressing from improved efficiency to enhanced decision-making quality requires high-quality data and robust decision-making models. Only with future increases in both the volume and quality of biological data will the convergence of IT and BT accelerate further. Over the next decade, the biopharmaceutical industry is poised to enter a new golden age, driven by the rise of biological computing.