NVIDIA, Tencent, SenseTime and Others: Advancing Medical AI through Privacy-Preserving Computation

Tencent Healthcare
Developer of Digital Healthcare Products

NVIDIA
Artificial Intelligence Computing Service Provider
Globally, the movement to protect data privacy and security has been gaining significant momentum for some time. As early as 2018, the European Union’s General Data Protection Regulation (GDPR), hailed as the “strictest in history” and representing the “most significant change in data security in three decades,” sparked widespread global attention and spurred countries and regions worldwide to place greater emphasis on data privacy and security.
On June 10, 2021, the 29th Session of the Standing Committee of the 13th National People’s Congress of the People’s Republic of China formally adopted and promulgated the Data Security Law, which came into effect on September 1, 2021. Together with the already enacted Cybersecurity Law and the Personal Information Protection Law under deliberation at the time, it underscores China’s emphasis on data privacy and security, jointly establishing the legal framework for information in the nation’s digital era.
In this context, data privacy and security have received unprecedented attention and will undoubtedly become stricter in the future. Acquiring the medical data necessary for the development and iteration of medical AI models has become increasingly difficult. Privacy-preserving computation, represented by federated learning, has provided a novel approach to this problem and has garnered widespread attention over the past two years. Two years on, what progress has been made in privacy-preserving computation, particularly federated learning? VCBeat (WeChat ID: Vcbeat) has compiled an overview of these developments.
In simple terms, federated learning is an encrypted distributed machine learning framework aimed at training AI models while ensuring data privacy, security, and legal compliance. This technology was first proposed by Google and its first practical application scenarios were showcased at the Google I/O 2019 conference.
The Gboard keyboard demonstrated by Google at the time employed this novel model training approach, distributing the entire model learning process to users’ mobile devices. Each device completed its assigned local model training tasks and then uploaded the resulting updates for aggregation to aid in overall model training. Since the training process was performed locally and only the data essential for model training was uploaded, this method effectively prevented data leakage.
The refinement of medical AI models likewise requires training on vast amounts of data. Radiologists typically need 15 years of practice, handling at least 15,000 cases per year on average, to achieve a modest level of proficiency. This implies that artificial intelligence must learn from an equivalent volume of cases (225,000) to reach the expertise level of a radiologist. Unfortunately, the largest currently available open-access database contains only 100,000 cases, falling short of meeting the requirements for AI training.
In fact, healthcare institutions may possess archives containing hundreds of thousands of records and images, but due to privacy concerns and regulatory constraints, these data remain completely isolated and unusable. Both AI companies and healthcare institutions utilizing AI are forced to rely solely on their limited internal data sources. The severe scarcity of high-quality training data has significantly hindered the further advancement of medical AI.
Furthermore, models trained exclusively on open-access databases are highly likely to lack genuine clinical value. In 2021, the University of Cambridge screened 2,212 publicly published papers on medical AI and selected 62 that met the researchers’ stringent inclusion criteria. However, the researchers ultimately found that none of these 62 studies possessed potential clinical application value.
The severe inadequacy in dataset quality and scale is a significant contributor to this issue; furthermore, the sole reliance on public datasets sourced from open-access databases is also a contributing factor. As public datasets evolve and incorporate new data over time, it is highly likely that initial results will become irreproducible.
Researchers at the University of Cambridge have put forward three key points: First, public datasets may pose significant risks of bias and should be used with caution. Second, to ensure that models are applicable to diverse populations and independent external datasets, training data should maintain diversity and an appropriate scale. Third, in addition to higher-quality datasets, evidence of reproducibility and external validation is required to increase the likelihood that models will be advanced and integrated into future clinical trials.
However, medical data contains a vast amount of patient privacy. Healthcare institutions and patients are absolutely unwilling to bear the risk of privacy breaches for the sake of model training. Federated learning enables multiple institutions to iteratively train models using their own data and subsequently upload and share the trained models. This process does not involve sensitive clinical data or patient privacy, thereby addressing public concerns.
Suppose three hospitals decide to collaborate in establishing a central deep neural network to assist in the automated analysis of brain tumor images, opting for a client-server federated learning approach. Within this architecture, the central server will maintain the global deep neural network. Each participating hospital will receive a copy of this neural network model to train using its own data.
Once the model has undergone several rounds of iterative training locally, participants send the updated version back to the central server. This process transmits only the trained model and its parameters, rather than sending patient case data as in traditional approaches. Meanwhile, the transmitted data is specially encrypted, providing robust protection.
Upon receiving the updated models uploaded from various locations, the server aggregates these locally updated models and updates the global model. Subsequently, the server shares the updated model with participating institutions to enable them to continue local training.
It is evident that throughout the process, the shared model accesses a significantly broader range of data than any single organization holds internally, resulting in more effective training. Meanwhile, since only model parameters need to be transmitted, the requirements for network bandwidth are substantially reduced.
Furthermore, the training of the global model does not rely on specific data. Therefore, if one hospital withdraws from the model training consortium, the training process will not be halted. Similarly, a new hospital can opt to join the initiative at any time to accelerate model training.
Federated learning enables multiple organizations to collaborate on model development without the need to share sensitive clinical data or compromise patient privacy. The industry hopes that this novel approach will resolve the current data dilemmas facing AI. Compared with traditional models, federated learning can also encourage different institutions to cooperate in creating a model that benefits all parties.
Since its inception, federated learning has garnered significant attention from the industry, leading to the release of several open-source frameworks. These frameworks are spearheaded by companies such as Google (TensorFlow Federated), OpenMined (PySyft), Baidu (PaddleFL), and WeBank (FATE). Meanwhile, NVIDIA Clara and WeBank have also launched commercial products for federated learning. Currently, federated learning is yielding fruitful results across various industries, with healthcare applications being one of them.
Applications in Medical Imaging
In October 2019, NVIDIA introduced federated learning technology into its Clara platform, which is specifically designed for the medical imaging sector, and collaborated with King’s College London to release a federated learning system for medical image analysis with privacy-preserving capabilities.
By leveraging the Clara platform, which supports federated learning, researchers can significantly simplify the deployment of this system. They can securely and conveniently configure the central federated learning server and collaborative clients, providing everything needed to launch a federated learning project, including application containers and initial AI models.
Hospitals participating in this project use the Clara AI-assisted annotation tool, which integrates with hospital imaging equipment, to label their own patients' imaging data. By leveraging pre-trained models and transfer learning techniques, Clara assists radiologists in the labeling process, reducing the time required for complex 3D studies from hours to minutes.
Each hospital will leverage these data to train models on local EGX servers. The local training results are shared back to the federated learning central server via secure links, where the central server updates the global model. Subsequently, the updated model is synchronized with each hospital’s server to enable further training on the new model.
Leading global healthcare institutions—including the American College of Radiology (ACR), Massachusetts General Hospital, and UCLA Medical Center—are racing to adopt this technology. They are dedicated to developing personalized AI applications for their physicians, patients, and medical facilities, even as their volumes of medical data, applications, and devices continue to grow and patient privacy must be safeguarded.
ACR has introduced NVIDIA Clara Federated Learning into its national medical imaging platform, AI-LAB, thereby helping ACR’s 38,000 medical imaging members securely build, share, fine-tune, and validate AI models.
In September 2020, NVIDIA, the American College of Radiology (ACR), DASA (the largest third-party medical laboratory in Latin America) from Brazil, Massachusetts General Hospital, Mayo Clinic, Stanford University, and the Massachusetts Institute of Technology launched a collaborative project to train artificial intelligence models for medical imaging in real-world collaborative environments through federated learning, aimed at assisting in the diagnostic classification of breast BI-RADS.
When analyzing mammography results, radiologists simultaneously search for tumors and assess breast tissue density. Breast tissue density refers to the amount of fibrous and glandular tissue visible on a woman’s mammogram. Based on imaging characteristics, breast density is classified into four categories: fatty, scattered fibroglandular, heterogeneously dense, and extremely dense.
The rationale for physicians to classify breast tissue density is straightforward: women with high breast density have a 4–5 times higher risk of developing breast cancer. Statistics indicate that this population accounts for approximately half of women aged 40–74 in the United States. Therefore, providing physicians with high-quality computer-aided tools for breast density classification can facilitate more accurate assessment of patients’ cancer risk.
Despite significant variations in the datasets shared by all participating institutions (including mammography systems, class distributions, and dataset sizes), the AI model training was successfully conducted and demonstrated favorable performance. Comparatively, models trained using federated learning outperformed those trained solely on local institutional data by an average of 6.3%, with a relative improvement of 45.8% in model generalizability.
Prediction of Oxygen Consumption in Patients with COVID-19
Federated learning has also made its own contribution during the global outbreak of COVID-19—researchers from NVIDIA and Mass General Brigham (a healthcare system jointly established by Massachusetts General Hospital and Brigham and Women’s Hospital) developed an AI model. This model can predict whether COVID-19 patients in the emergency department will require oxygen therapy within hours or days after initial evaluation, based on chest X-rays, patient vital signs, and laboratory results. Furthermore, it forecasts the amount of oxygen needed in the emergency room and determines whether patients need to be transferred to the intensive care unit (ICU).
To develop a reliable AI model and deploy it across as many hospitals as possible, NVIDIA and Mass General Brigham have launched the EXAM (EMR CXR AI Model) initiative. Collaborating with 20 hospitals worldwide, this initiative represents one of the largest and most diverse federated learning efforts to date.
These hospitals are distributed across North America, South America, Asia, and Europe, with data encompassing datasets from patients of diverse ethnic backgrounds. Each hospital utilizes NVIDIA Clara to train its local models and participate in EXAM. Throughout this process, the participating institutions do not need to centrally aggregate patients’ chest X-rays and other confidential information; instead, they store their data on secure internal servers.
The global deep neural network model is hosted on independent Amazon AWS servers, with each participating hospital receiving a copy for training on its own dataset.
By training the model on various distributed data sources, the project team developed a model with an AUC of 0.94 (against a target of 1.0) in just two weeks, demonstrating excellent performance in predicting oxygen requirements for hospitalized patients. Given that oxygen therapy is critical for COVID-19 patients, this technology platform has been integrated into Clara NGC, saving numerous lives.
Wearable Medical Health Devices
Wearable devices, which play a significant role in the healthcare sector, are also incorporating federated learning. These devices can accurately record users’ daily activities and vital signs, offering substantial value for the prevention and early screening of certain diseases. Meanwhile, wearable devices demonstrate application value in mental health, fall detection for patients or the elderly, and fitness monitoring. In recent years, global wearable healthcare devices have achieved breakthroughs, with shipment volumes reaching record highs and accumulating massive amounts of data.
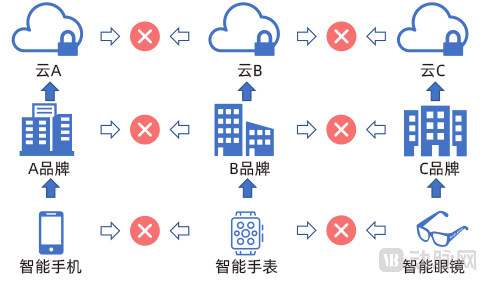
Traditional approaches pose a significant challenge for wearable devices (Image source: IEEE Intelligent Systems, Volume: 35 Issue: 4: FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare)
However, there are two major challenges in applying these data. First, the data exist in silos. For instance, if a user employs two wearable devices from different brands, the data generated remain isolated and non-shareable even when uploaded to the cloud. Furthermore, as countries and regions strengthen data security legislation, they also impose requirements on the geographic location of data storage. This makes it extremely difficult for device manufacturers of the same brand to access data stored across various global locations. Consequently, the data used for training models struggle to meet standards in terms of both quality and quantity.
Secondly, traditional model training methods are generic and lack personalization and specificity. However, different users have distinct physiological characteristics, and wearable devices based on generic models cannot optimally meet their needs.
In 2020, the Ubiquitous Computing Systems Research Center of the Chinese Academy of Sciences, the University of Chinese Academy of Sciences, Shenzhen Peng Cheng Laboratory, and Microsoft Research Asia jointly proposed the FedHealth architecture, which is also the first federated transfer learning framework designed for wearable medical health devices.
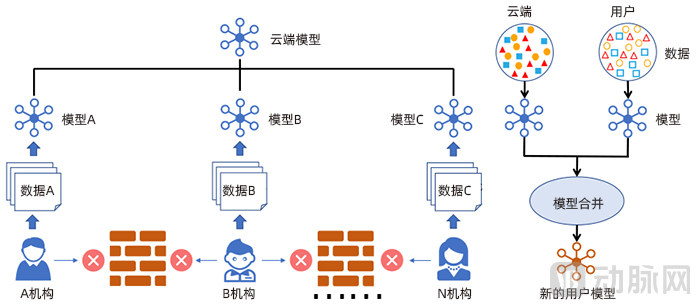
Federated learning can effectively leverage data from distributed wearable devices (Image source: IEEE Intelligent Systems, Volume: 35, Issue: 4: FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare)
By leveraging federated learning and homomorphic encryption, FedHealth ensures user data privacy and security while providing a continuous stream of data for training robust models. After the global model is trained, transfer learning is introduced to meet personalized needs. Furthermore, this incrementally upgradable framework can be further expanded and deployed across various healthcare applications to enhance learning capabilities in real-world settings.
Based on experiments conducted on a total of 10,299 data sets collected from 30 participants, FedHealth has improved the accuracy of behavior recognition for wearable devices. Compared with deep learning methods that do not adopt federated learning, the accuracy of the model trained by FedHealth has increased by 5.3%.
Stroke Prediction
As one of the internationally recognized AI pioneers who first researched “federated learning,” Professor Yang Qiang, Chief Artificial Intelligence Officer of WeBank, has propelled WeBank’s AI team to become a domestic leader in federated learning technology and facilitated its application in real-world business scenarios. Currently, WeBank has implemented federated learning solutions across industries such as finance and healthcare.
In December 2018, WeBank initiated the standardization project for “Federated Learning Architecture and Application Specifications,” which was approved by the IEEE Standards Association. Numerous renowned scholars and technical experts from China and abroad joined the standards working group to contribute to the development of the IEEE standard for federated learning.
In 2019, Tencent’s Tianyan Laboratory and WeBank collaborated in the fields of medical big data and computer-aided diagnosis of medical imaging, jointly developing a “Stroke Onset Risk Prediction Model” based on a medical federated learning framework. The model leverages natural language processing (NLP) techniques to process electronic health records, predicting patients’ risk of stroke by analyzing and identifying symptoms highly associated with the condition.
Five hospitals in a central Chinese city, including three of the city’s leading Grade 3A hospitals, participated in the study and trained the model using their respective electronic medical record data. The results showed that the model trained via federated learning achieved a prediction accuracy of up to 80%. Meanwhile, data resources from large Grade 3A hospitals helped small hospitals with limited medical services and few cases improve their model prediction metrics by 10–20%.
In August 2020, Tencent Healthcare and WeBank established a joint laboratory. Leveraging Tencent’s Tianyan Laboratory’s technical expertise in medical imaging, medical machine learning, and natural language processing, along with WeBank’s AI team’s leading capabilities in federated learning, the joint laboratory will further advance the application of federated learning in the healthcare sector.
Drug Discovery
Given the immense potential of AI in drug discovery, federated learning has also made progress in this scenario. In December 2020, the Department of Bioinformatics at Tongji University collaborated with WeBank to simulate collaborative drug development among multiple pharmaceutical institutions through federated learning, thereby assisting these institutions in conducting collaborative drug discovery while ensuring the privacy and security of their proprietary drug data.
The biggest pain point in AI-driven drug discovery lies in the complex intellectual property rights and associated economic interests within the field, which make direct data sharing and collaboration among pharmaceutical institutions nearly impossible. By introducing federated learning into the collaborative development of small-molecule drugs, it is possible to achieve model prediction performance comparable to that of QSAR modeling based on directly integrated multi-institutional small-molecule data, while safeguarding the privacy of small-molecule structures. This approach may help break the ice in industry collaboration.
This study represents the first attempt to explore the feasibility of applying the federated learning paradigm to collaborative drug development in the field of small-molecule drugs. By leveraging WeBank’s open-source federated learning platform, FATE, we developed FL-QSAR, a collaborative drug discovery platform based on federated learning.
The research team constructed deep learning models using a QSAR benchmark dataset encompassing 15 drug targets, conducting QSAR modeling and simulating collaborative drug development in a multi-pharmaceutical setting. The results demonstrated two key advantages of applying federated learning to drug discovery.
First, collaborative QSAR modeling via FL-QSAR across multiple pharmaceutical institutions significantly outperforms local QSAR modeling based solely on proprietary data within a single institution. Second, through specific model optimizations, FL-QSAR can achieve predictive performance comparable to that of QSAR modeling based on directly aggregated multi-institutional small-molecule data, while preserving the privacy of drug small-molecule structures.
This is an effective solution for collaborative drug discovery, breaking down the barriers that prevent direct data sharing among different pharmaceutical institutions during traditional QSAR modeling. It facilitates collaborative drug discovery under privacy-preserving conditions and has received funding from national special projects.
Despite its relatively recent emergence, the federated learning architecture itself has been continuously improved. For instance, in 2020, Sensetime, in collaboration with the Center for Computational Biomedical Imaging and Modeling within the Department of Computer Science at Rutgers University, published new research findings on implementing federated learning using a structure based on distributed Generative Adversarial Networks (GANs).
This study constructs an adversarial network by integrating distributed asynchronous discriminators located at multiple separate institutions with a central generator, enabling the central generator to undergo synthetic training without accessing raw private data. Consequently, it can generate synthetic data samples resembling the original data from each institution for use in downstream tasks.
Building on this foundation, the proposed framework incorporates two loss functions to endow the central generator with lifelong learning capabilities, enabling continuous model training in dynamic environments where new institutions may join or existing ones withdraw during the learning process.
Experimental simulations demonstrate that this learning method can progressively learn the approximate distributions of similar or even dissimilar data from different institutions, achieving desirable performance in medical image segmentation tasks.
Compared with traditional federated learning, Sensetime’s solution can effectively reduce the volume of communication data between the central server and participating institutions. It requires transmitting only synthetic image data and feedback errors, rather than all model parameters. Furthermore, no data or parameters need to be exchanged among the institutions themselves. This approach significantly lowers the cost for healthcare organizations to deploy federated learning, while accelerating research efficiency and the production speed of AI models.
In addition to improving federated learning, the industry is also developing new solutions. In May 2021, German researchers published a paper in Nature proposing a decentralized machine learning approach called Swarm Learning, which combines edge computing with blockchain-based peer-to-peer networks to integrate medical data across different healthcare institutions.
Although federated learning addresses data privacy concerns, the global model and parameter tuning are still processed by a central server of a specific institution, inevitably leading to centralized power. Furthermore, this star-shaped topology exhibits low fault tolerance. In contrast, swarm learning eliminates the need for a central server to exchange data or perform global modeling, allowing for parameter aggregation. This approach ensures equal rights for all members and effectively protects machine learning models from attacks through decentralization.
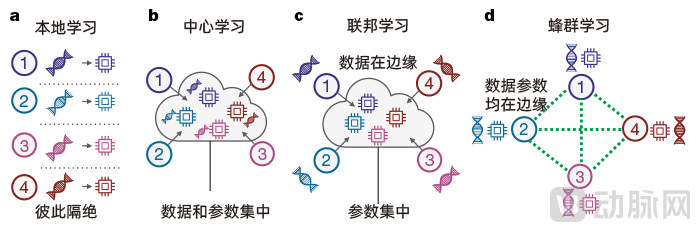
In local learning (a), data and computation are implemented at separate institutions in isolation from one another. In centralized learning (b), data and parameters from different institutions are aggregated on the cloud for model training. In federated learning (c), data and training remain localized, while global model parameter configuration and model sharing are handled centrally. In swarm learning (d), data and parameters are decentralized and interconnected, eliminating the need for a central node. (Image source: Nature: Swarm Learning for decentralized and confidential clinical machine learning)
This study on swarm learning selected four heterogeneous diseases—tuberculosis, COVID-19, leukemia, and pulmonary lesions—to demonstrate the feasibility of using swarm learning to develop disease classification systems based on distributed data.
The study attempted to use swarm learning to predict leukemia from peripheral blood mononuclear cell data, identify tuberculosis or pulmonary lesion patients from blood transcriptome data, and identify and detect COVID-19 patients. The datasets required for training included more than 16,400 blood transcriptomes from 127 clinical studies, as well as over 95,000 chest X-ray images. The distribution of cases and controls in these datasets was uneven, with significant bias.
The results indicate that the classification model trained via swarm learning outperforms models trained on local data. Furthermore, swarm learning incorporates blockchain technology and decentralized hardware infrastructure to prevent data tampering, while significantly enhancing member autonomy, enabling secure participation, dynamic leader election, and model parameter aggregation.
Overall, research suggests that swarm learning has the potential to reshape the current landscape more effectively than federated learning, with decentralized data models poised to become the preferred approach for processing, storing, managing, and analyzing large-scale medical datasets of any kind.
Global emphasis on data privacy and security is increasingly growing, particularly in the healthcare sector. Privacy-preserving computation, represented by federated learning and swarm learning, will determine whether medical AI can advance further in the future, owing to its ability to safeguard data privacy while delivering superior performance. Many research teams are actively exploring these technologies and applying them to specific healthcare scenarios.
Nevertheless, the number of specific healthcare scenarios where federated learning has been truly implemented remains limited. This advanced architecture still faces several concrete challenges, including generally poor data quality in medical institutions, lack of physician involvement in model training which hinders clinical adoption, insufficient incentives to attract data providers, significant difficulties in personalized model training, and inadequate model accuracy in complex scenarios.
The good news is that federated learning has made progress in standardization. In March 2021, the IEEE officially completed the development of its standards, resulting in the formal standard document IEEE P3652.1. Meanwhile, the highly anticipated draft of the Personal Information Protection Law was submitted to the Standing Committee of the National People's Congress for its second review this year and is poised for imminent implementation. This provides a foundation for future advancements in various specialized fields. It will not be long before we see privacy-preserving computation demonstrate its significant value in real-world application scenarios.
References
MICCAI Workshop on Domain Adaptation and Representation Transfer & MICCAI Workshop on Distributed and Collaborative Learning:Federated Learning for Breast Density Classification: A Real-World Implementation
Medical Image Analysis, Volume 70, May 2021, 101992:Federated semi-supervised learning for COVID region segmentation in chest CT using multi-national data from China, Italy, Japan
IEEE Intelligent Systems , Volume: 35 Issue: 4:FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare
Nature: Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans
arXiv.org:Privacy-Preserving Technology to Help Millions of People: Federated Prediction Model for Stroke Prevention
Nature:Swarm Learning for decentralized and confidential clinical machine learning
arXiv.org:Learn distributed GAN with Temporary Discriminators
Bioinformatics doi: 10.1093/bioinformatics/btaa1006:FL-QSAR: a federated learning based QSAR prototype for collaborative drug discovery
Leiphone: “First International Standard for Federated Learning Officially Released!”
Yicai: “Banks Flock to Federated Learning: How Far Is Large-Scale Implementation?”