Medical AI Deployment Exploration: Will 'Inference Efficiency' Become the Next Battleground?

NVIDIA
Artificial Intelligence Computing Service Provider
When discussing AI in medical imaging, the first things that come to mind are often model accuracy, sensitivity, the scope of product applications, or the status of regulatory approval and review. However, as medical AI solutions successively gain approval from the Center for Medical Device Evaluation (CMDE) and are deployed in hospitals as commercial products, physicians’ actual user experience has gradually become a key focus for medical AI vendors.
Numerous obstacles hinder the normal deployment of AI in hospitals. Factors such as PACS system interfaces, hardware and software compatibility (including hospital computers), and data transmission limitations between workstations and electronic medical records can reduce the inference speed of AI in practical applications, and may even lead to incompatibility issues among multiple AI systems.
Recently, NVIDIA has applied its TensorRT and Triton tools to the deployment phase of medical AI. As a leader in AI computing, NVIDIA has previously assisted numerous medical AI companies in training and building their AI models. It is now extending its reach further downstream into AI implementation, aiming to resolve the deployment complexities between hospital departments and AI enterprises.
On one hand, new tools will help medical AI companies fully leverage GPU hardware resources and maximize GPU computing power for AI inference; efficiently deploy and optimize the practical use of computational resources; and securely and efficiently schedule GPUs, thereby accelerating the AI inference process at hospitals and improving the real-world user experience of medical AI.
On the other hand, in the current era where single-disease AI is mainstream, many departments typically purchase multiple AI solutions from a given AI company and switch between different AI systems during diagnosis. In this context, NVIDIA can provide AI companies with a universal support framework to help them deploy multiple artificial intelligence models across various environments.
As medical artificial intelligence enters an era of refined competition, NVIDIA’s new tools may help medical AI companies reshape their competitiveness.
Inference refers to the application of diagnostic capabilities learned from medical imaging AI training in deep learning to real-world practice, and is key to medical artificial intelligence simulating physicians for assisted diagnosis.
For a serious discipline like medicine, the speed and accuracy of AI diagnostics must meet stringent requirements. This means that medical AI models and their inference processes are always highly complex, making it difficult to gain insight into how AI arrives at its conclusions.
To make medical AI reasoning more controllable, NVIDIA has expanded the applicability of TensorRT to medical scenarios. As a high-performance optimizer and runtime engine for deep learning inference, TensorRT takes models trained with the TensorFlow framework as input, generates optimized model runtimes for CUDA GPUs, reduces inference time to lower application latency, minimizes computation and memory access, and leverages sparse tensor cores to provide additional performance improvements.

Furthermore, TensorRT can decompose and then fuse models trained by R&D personnel, resulting in highly integrated fused models. For instance, fusing convolutional layers with activation layers can significantly accelerate computation speed.
In July 2021, the latest-generation TensorRT 8.0 further maximized the aforementioned advantages.
TensorRT 8.0 leverages quantization-aware training to achieve accuracy comparable to FP32 while maintaining INT8 precision, doubling both inference speed and accuracy compared to version 7.0. Furthermore, TensorRT 8.0 accelerates a wide range of inference models, with BERT-based model inference speeds improved by 2x.
By leveraging sparsity techniques, TensorRT 8.0 significantly enhances Ampere GPU performance, boosting throughput by up to 50% and accelerating 2:4 fine-grained structured sparsity. Data shows that users can achieve performance gains of over 30% by eliminating unnecessary computations in neural networks.
More efficient inference can resolve many of the challenges currently faced in deployment. For instance, due to constraints imposed by hospital computer systems on healthcare information technology infrastructure, many hospitals operate with outdated software versions that struggle to meet the hardware and software requirements of medical AI. The integration of TensorRT 8.0 enables more effective utilization of limited computational resources, thereby significantly reducing the cost of AI deployment.
Furthermore, high-efficiency inference and low latency can optimize the smoothness of online workflows. In the paperless era, TensorRT 8.0 will significantly enhance physicians’ AI user experience.
TensorRT 8.0 has optimized medical AI inference, but in practice, NVIDIA still needs to address the critical challenge of deploying multiple types of AI models within the same environment.
NVIDIA Triton Inference Server is an open-source software that provides a single, standardized inference platform, enabling inference across multi-framework models, CPUs and GPUs, and diverse deployment environments such as data centers, cloud, embedded devices, and virtualized environments.
For all inference modes, Triton simplifies how models run across any framework and on any GPU or CPU, facilitating the deployment of AI in production environments. Integrated with NVIDIA TensorRT 8, the latest version of NVIDIA’s AI deployment framework, Triton further enhances neural network inference efficiency, reducing computational and storage costs without compromising accuracy to achieve high-performance inference.
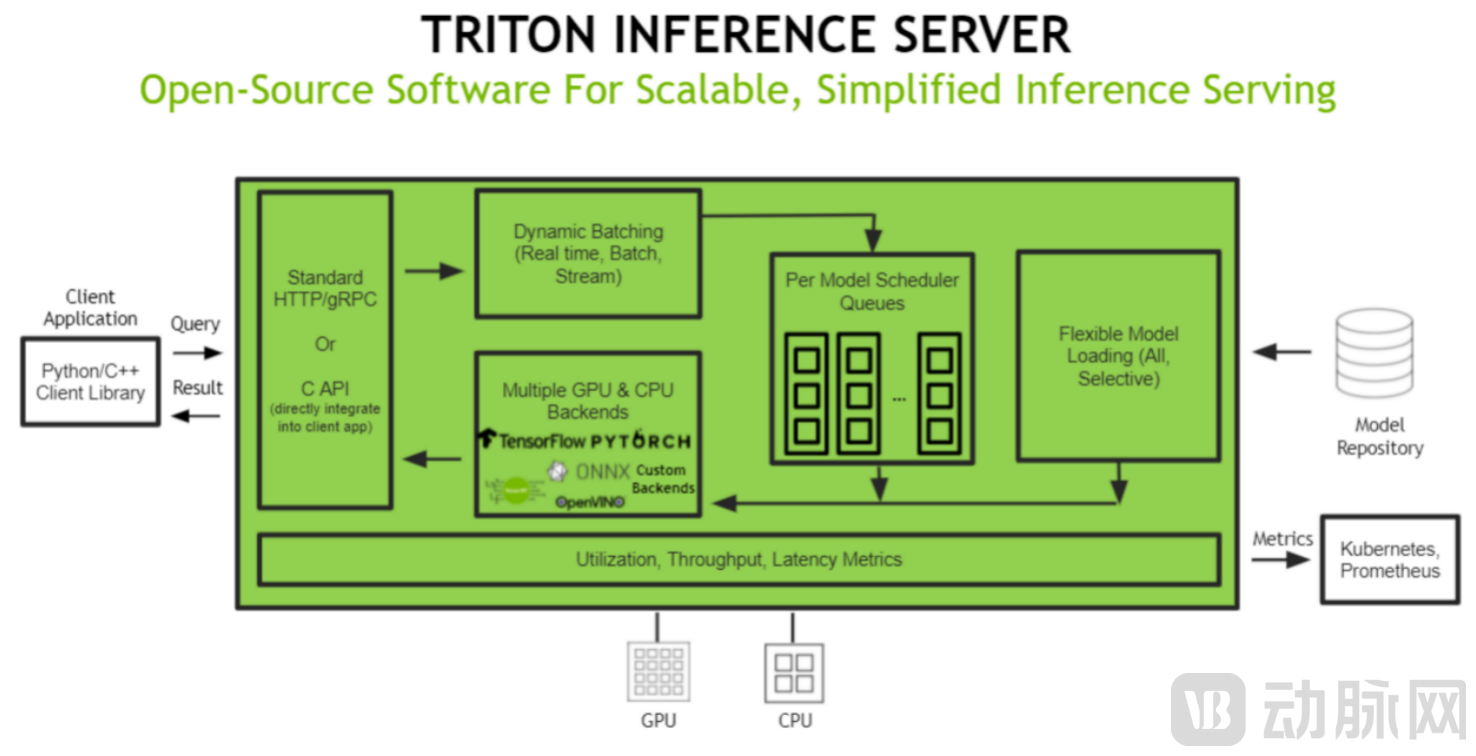
Currently, Triton supports multi-model ensembles and various deep learning frameworks such as TensorFlow, PyTorch, and ONNX. It effectively facilitates scenarios involving joint inference across multiple models, enabling the construction of end-to-end inference services for video, image, speech, and text, thereby significantly reducing the development and maintenance costs associated with multi-model services.
In the financial industry, Ant Group has leveraged NVIDIA Triton Inference Server, in conjunction with T4 GPUs and DALI’s image preprocessing capabilities, to boost overall multi-model inference performance by 2.4x while reducing latency by 20%. This approach not only meets the business requirement for low latency but also cuts costs by 50%. This means that in multimodal business scenarios, Ant Group has built high-performance inference services at a lower cost, reduced response times across the entire system pipeline through lower latency, and enhanced user experience.
Similar success can also be replicated in the healthcare sector. On one hand, with Triton’s support, researchers at medical AI companies are free to select the most suitable frameworks for their projects, maximizing GPU utilization and accelerating inference capabilities. On the other hand, Triton’s multi-environment support and robust security features ensure seamless deployment of medical AI solutions in any hospital, enabling deployment teams to more easily accommodate the diverse environmental preferences of different healthcare institutions.
To further help everyone understand the application of TensorRT and Triton in medical imaging diagnosis, NVIDIA will host a webinar titled “Unlocking the Application of TensorRT and Triton in Medical Imaging Diagnosis” on October 13 from 14:00 to 15:20, providing a detailed explanation of TensorRT and Triton in healthcare.
This webinar features Dr. Fan Zhao, Senior Architect at NVIDIA, and Dr. Pan Liu, Algorithm Director at Ande Medical Intelligence. The two speakers will share the following insights during the session:
l Latest features of TensorRT 8;
l Application features of Triton and how to use it efficiently;
l Common Issues and Best Practices for Deploying AI in Medical Imaging;
l Introduce the advantages of Triton's multi-backend architecture and the inference workflow based on PyTorch/TensorFlow backends;
l Explain practical cases of converting large-scale 3D models from GraphDef to TensorRT plan;
- Explain model deployment and scheduling in real-world application environments.
If you are interested in participating in this seminar, please scan the QR code below to register.
