Data Volume Surge and Emerging Commercialization: Is Gene Testing Entering the Intelligent Era?
In 2017, with the market launch of Illumina’s NovaSeq series of gene sequencers, the cost of whole-genome sequencing was further reduced to under $1,000. This triggered a surge in both the volume of global genomic data and the demand for its analysis. At that time, VCBeat predicted that as the second growth curve for the genomics technology industry, the key challenge would be how to analyze and interpret genomic data more rapidly and accurately.
Today, the entry of internet and tech giants is driving the convergence of information technology (IT) and biotechnology (BT), seemingly validating earlier speculations. To bioinformaticians, the human body is akin to a program—a series of chemical reactions and physical changes governed by the genomic code. Sequencing data generated in laboratories are compared against data accumulated in information systems to identify mutation sites, thereby enabling the interpretation of results actionable for end users. When the volume of gene sequencing data was still in its growth phase, IT’s role consisted primarily of specialized analytical tools tailored to specific problems. However, as current data scales increasingly exceed the capacity limits of these tools, cloud computing, ultra-high-performance chip acceleration, and artificial intelligence algorithms are beginning to define the underlying logic of “IT+BT.”
From research services to clinical applications, and from oncology diagnosis and treatment to the prevention and control of infectious diseases, commercialization scenarios for gene technology are emerging endlessly, with star products and companies constantly rotating. What exactly constitutes the core competitiveness that forms the foundation of gene technology companies? Why are we revisiting the topic of genetic data at this juncture? Has the vision imagined years ago—of iterating gene technology through information technology—now come to fruition? This report attempts to reveal the answers.
In this report, we summarize the following core insights on the intelligent transformation of genetic testing through industry and product analysis as well as expert interviews, for the benefit of our readers.
1. Significant shifts in the competitive landscape of the upstream gene sequencing sector, both domestically and internationally, will trigger a profound reshuffling among midstream service providers;
2. As the cognitive dividend wanes, genetic testing service providers are shifting their focus to strengthening internal capabilities, with data capability building at the core;
3. There is an explosive surge in demand for big data analysis of genes related to new drug development, scientific research, and clinical applications, with enormous potential for clinical data mining;
4. Accelerated development of regional and corporate platforms, challenging standardization and regulation, and gene databases entering uncharted territory;
5. Upstream sequencing and downstream applications are both maturing, yet databases remain a bottleneck hindering the intelligent transformation of gene technology;
6. Leading enterprises are frequently launching intelligent genetic products and services, but overall R&D and application remain in their infancy.
The Current State and Opportunities of Intelligent Genetic Testing
Genetic testing refers to the analysis of human DNA, RNA, proteins, and metabolites to diagnose, predict, or prevent the occurrence of genetic diseases, guide the selection of disease treatment regimens (including the choice of drug types and dosages), or predict disease recurrence. It can also serve as a basis for assessing an individual’s constitution or traits. Currently, the technologies used for genetic testing are mainly categorized into four types: PCR technology, gene sequencing technology, FISH technology, and gene chip technology. Driven by applications based on big genomic data, sequencing technology has become the most mainstream genetic testing method.
Taking next-generation sequencing (NGS) technology as an example, the gene sequencing workflow encompasses sample collection, data generation, data analysis, data interpretation, and translational applications. Currently, NGS technology still relies on manual operations, which inevitably introduces human-induced variability in data quality and imposes constraints on cost and turnaround time due to labor dependence. The volume of genetic data requiring processing is immense, reaching up to the petabyte (PB) or exabyte (EB) scale. Furthermore, the complexity of bioinformatics algorithms employed in data analysis renders this stage cumbersome, inefficient, and time-consuming.
Policy and Regulations: New Healthcare Reform and New Infrastructure for Life and Health Propel the Gene Testing Industry into Rapid Intelligentization
In 2017, the “Notice of the State Council on Issuing the Development Plan for New-Generation Artificial Intelligence” mentioned conducting large-scale genomic identification, proteomics, metabolomics, and other research as well as new drug development based on artificial intelligence, and promoting intelligent pharmaceutical regulation. Therefore, an intelligent production system for gene sequencing is an inevitable trend, helping to standardize gene data production processes, ensure full-process quality control of data, and control sequencing costs and time.
The development of the genetic testing industry remains technology-driven, yet the relevant policy environment also provides ample nourishment for the advancement of intelligent genetic testing.
New Infrastructure for Life and Health.At the State Council executive meeting in April 2020, new-type infrastructure (hereinafter referred to as “New Infrastructure”) was defined as an infrastructure system guided by the new development philosophy, driven by technological innovation, based on information networks, and oriented toward the needs of high-quality development, providing services such as digital transformation, intelligent upgrading, and integrated innovation.
In April 2020, the Joint Prevention and Control Mechanism of the State Council for COVID-19 issued the "Notice on Further Improving Work Related to Novel Coronavirus Testing During the Epidemic," which stipulated that all tertiary general hospitals shall establish clinical laboratories meeting Biosafety Level II (BSL-2) or higher standards to independently conduct novel coronavirus testing. In regions with relatively scarce medical resources and weaker testing capabilities, one county-level medical institution with strong comprehensive strength shall be selected for priority support, thereby ensuring that medical institutions within the county have nucleic acid testing capacity.
In recent years, China has designated genetic testing as a national priority area, increasing support and introducing multiple policies and regulatory frameworks to foster industry development. These measures have created a favorable policy environment while progressively tightening regulatory oversight of genetic testing.
In March 2021, the Outline of the 14th Five-Year Plan for National Economic and Social Development of the People's Republic of China and the Long-Range Objectives Through the Year 2035 was officially released, clearly identifying “genetics and biotechnology” as one of the seven frontier areas for scientific and technological breakthroughs, and “biotechnology” as one of the nine strategic emerging industries, with “gene technology” designated as a future industry.
In 2016, China successively issued multiple key national policies related to this field. The genetic testing industry transitioned from a phase where industrial development drove policy reform to one where policy guided industrial growth. On April 15, 2016, the National Development and Reform Commission (NDRC) promulgated the “Reply of the General Office of the National Development and Reform Commission on the Construction Plan for the First Batch of Demonstration Centers for Genetic Testing Technology Applications,” officially approving the establishment of 27 demonstration centers for genetic testing technology applications across China, thereby encouraging the accelerated development of the genetic testing industry.
In 2017, China launched the 100,000 Genomes Project. The 13th Five-Year Plan designated the development of gene technology as a core task for innovation in the biopharmaceutical industry. Consequently, the bio-industry centered on gene technology has experienced rapid growth, propelling the gene sequencing sector into a period of explosive expansion.
In 2019, the "Healthy China Action (2019-2030)" explicitly called for accelerating the shift from a disease-treatment-centered approach to a people’s health-centered approach, stating that prevention is the most cost-effective and efficient health strategy. Genetic testing is recognized as the most effective preventive measure, especially as "Healthy China 2030" has been elevated to a national strategy.
Market Size: The Surge in Demand for Precision Medicine and the Super-Moore’s Law Decline in Genetic Testing Costs
The market potential for genetic testing expanded rapidly with the commercial launch of next-generation sequencing (NGS) technology in 2015. Leveraging advantages such as high throughput, high accuracy, and low cost, NGS has become the mainstream genetic testing technology, driving rapid industry growth. The future of healthcare undoubtedly lies in precision medicine, and the Chinese government encourages and supports the development of precision medicine based on gene sequencing. At the inaugural “National Precision Medicine Strategy Expert Meeting” convened by the Ministry of Science and Technology in March 2015, it was proposed that the government plans to invest RMB 60 billion in the development of precision medicine by 2030. According to forecasts, the global genetic testing market size will grow from USD 12.2 billion in 2019 to USD 28 billion in 2024, representing a compound annual growth rate (CAGR) of 18.08%. Meanwhile, China’s domestic genetic testing market is projected to increase from RMB 10.654 billion in 2019 to RMB 28.134 billion in 2026, indicating substantial future market potential.
Advances in gene sequencing technology have driven a dramatic reduction in sequencing costs, far exceeding the pace predicted by Moore’s Law. According to data published by the National Human Genome Research Institute, the average cost per megabase of sequencing was $5,292.40 in 2001, with the cost of sequencing a single human genome at $95.263 million. In 2006, the second-generation gene sequencing company 454 Life Sciences launched an ultra-high-throughput genome sequencing system. The emergence of next-generation sequencing (NGS) technology reduced the average cost per megabase to $581.90 and lowered the cost of sequencing a single human genome to $10.475 million. With the introduction of new technologies and sequencing instruments, sequencing costs have continued to decline at a rate surpassing “Moore’s Law,” reaching as low as $0.01 per megabase and $689 per single human genome by 2020.
Growth Stage: Disease relationships and algorithm validation are relatively complex, and the intelligence of genetic testing is still in its early stages.
Amid the wave of digitalization, intelligence is empowering genetic testing technologies. By integrating the equipment required for data analysis workflows, bioinformatics software, databases, and artificial intelligence technologies, automated data analysis and intelligent decision-making systems are realized, thereby promoting high-quality development in the genetic testing industry. However, due to the complexity of data analysis algorithms and the relationships between genomes and diseases, the intelligentization of genetic testing remains in its early stages of development.
However, while the concept is easy to grasp, implementation remains challenging; the intelligentization of genetic testing still faces numerous technical barriers.
Big Data Database.Nowadays, genetic testing technology has become highly mature, and many companies are capable of generating genetic data. However, the interpretation of such data remains challenging due to the complex relationship between genes and diseases. It relies on large databases used to interpret uncertain genetic test results, thereby enabling the translation of genetic data into clinical decision-making.
Data Analysis Algorithms.As genomic data rapidly expands and the types of mutations requiring analysis and interpretation become increasingly complex, phenotypic and clinical data are also becoming more comprehensive, thereby imposing higher demands on data analysis algorithms.
The business modules are complex.The construction of intelligent capabilities in genetic testing is centered on the full lifecycle process of data production, transmission, analysis, and application. Due to the complexity of business modules and heightened sensitivity to data security, it remains challenging to seamlessly integrate genetic testing technologies with digital technologies. There is still a long road ahead for the advancement of intelligence in genetic testing.
Although the intelligence of genetic testing is still in its early stages, it is developing rapidly. Products have already been launched in China, such as BGI’s HALOS bioinformatics analysis all-in-one machine and Novogene’s one-stop solution, the Falcon flexible intelligent production system.
Capital Enthusiasm: Giants in Computing, the Internet, and Gene Sequencing Platforms Are Entering the Fray to Drive Industry Transformation
As of the report’s release, China’s genetic testing industry recorded 106 financing transactions in 2021, with a total disclosed amount of RMB 21.3 billion, representing a 10% increase from 2020 (approximately RMB 19.3 billion). Although the number of financing transactions in 2021 increased by 32 compared to 2020, the total financing amount remained relatively similar, primarily due to the absence of mega-financing rounds akin to MGI Tech’s over-USD-1-billion raise completed in April 2020.
Based on the financing amounts and deal counts from 2015 to 2021, 2020 marked a peak in financing transactions within the genetic testing industry, with an annual growth rate as high as 153%. In 2021, the financing boom in the genetic testing sector continued, attracting sustained capital interest.
Currently, financing in China’s genetic testing industry is concentrated among manufacturers of sequencers and reagent consumables, whereas overseas investment during the same period has focused primarily on genetic data analysis, with most companies having reached later stages. Furthermore, the industrial structure and capital markets abroad are more mature than those in China; unicorn companies (including both private and publicly listed enterprises) span the upstream, midstream, and downstream segments of the genetics industry, with core businesses covering instrument and reagent R&D, scientific research and clinical genetic testing services, and data analysis. Due to the high technical barriers associated with sequencing technologies, only a few domestic companies possess the capability to independently develop genetic sequencers and other equipment, while the majority of enterprises are concentrated in data analysis, reagent and consumable production, and midstream testing services. Most Chinese companies that secured financing in 2021 were at Series B or earlier stages, indicating that domestic genetic data generation and analysis remain in the early stages of product commercialization.
Genomic big data boasts extensive application scenarios and a vast market, making it the sector within healthcare and medicine poised for the most rapid large-scale translation and adoption. The analysis and utilization of petabyte-scale genomic big data rely heavily on digital technologies such as cloud computing, artificial intelligence, big data, 5G, and blockchain. IT enterprises leverage their expertise in these digital technologies—characterized by massive data volumes, powerful computational capabilities and algorithms, as well as security and reliability—to empower the genomics industry, thereby driving a productivity revolution in the traditional genetic testing sector.
Market Roles: Five Key Roles Build the Ecosystem, with First-Generation Products Already in the Market to Drive Improved Testing Efficiency
The genetic testing industry generally comprises five key stages: collection of digitized biological information, data generation, analysis, interpretation, and translational application, leveraging big data to enable precision medicine and full-lifecycle health management for large populations.
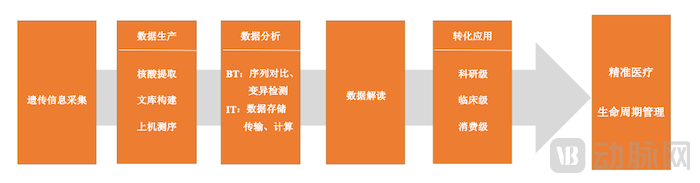
Value Chain of the Genetic Testing Industry
Data analysis involves the processing and interpretation of raw sequencing data through bioinformatics, encompassing infrastructure for data storage, computation, and management, as well as the software, algorithms, and emerging digital technologies required for analysis.
Companies engaged in data analytics primarily focus on three business areas: bioinformatics software development, gene big data platform solutions, and value-added services for gene big data. In the software segment, most domestic offerings are designed for detecting mutant genes in non-small cell lung cancer (NSCLC). Approved companies include BGI Genomics, Genetron Health, Burning Rock Biotech, and SeeGene Medical.
Data interpretation integrates genetic testing results with clinical phenotypes to explore gene-disease associations, thereby facilitating basic research and guiding clinical decision-making. In scientific research services, Novogene employs multi-omics integrated analysis to elucidate disease mechanisms and propose potential therapeutic strategies. In clinical practice, Zhiyin Oriental has pioneered a clinical analysis algorithm based on the “biology + genetics + clinical” triad principle, enhancing the efficiency of clinical diagnosis.
Genetic testing is currently widely used in research-grade, clinical-grade, and consumer-grade scenarios within the healthcare sector.
Genetic testing services in the scientific research sector are primarily targeted at research institutions, encompassing genomic sequencing, transcriptomic sequencing, epigenomic sequencing, metagenomic sequencing, and single-cell sequencing. The domestic market for genetic testing in scientific research is relatively saturated. Key companies providing basic research-oriented genetic testing services include Novogene, BGI Genomics, Berry Genomics, Joinn Medical, and Annoroad Gene Technology. Clinical-grade applications mainly involve clinical genetic diagnostics, covering areas such as birth defect prevention and control, tumor diagnosis, and infectious disease diagnosis.
Intelligent Industrial Chain and Applications of Genetic Testing
The genetics industry is entering the era of big data.
The human genome contains a vast amount of data. DNA (deoxyribonucleic acid) is a double-stranded polymer formed by the arrangement and combination of four types of deoxyribonucleotides carrying different bases (A, T, C, G). The number of bases or deoxyribonucleotides serves as the standard for measuring DNA length; DNA composed of 1,000 deoxyribonucleotides has a length of 1 Kb. The complete human genome contains approximately 3.2 billion base pairs, with a length of around 3 Gb. Meanwhile, genetic variations are highly diverse, including single nucleotide mutations, gene segment duplications and deletions, chromosomal abnormalities, and epigenetic modifications such as methylation that do not alter the DNA sequence. Consequently, genetic information is characterized by its enormous volume and complex structure.
As the genomics industry continues to expand, the volume of gene sequencing is steadily increasing, bringing to the fore the massive datasets generated and the growing need for their governance. Consequently, the integration of genomic technology with artificial intelligence has emerged from its traditional role as a supportive bioinformatics component in genetic testing to become a rapidly burgeoning industry in its own right.
At the upstream end of the intelligent genomics industry, raw sequencing data are still generated through specialized instruments and reagents. This segment has reached a relatively mature stage of development, with a well-established supply-side structure for sequencers and their配套 reagents. In terms of sequencer models, Illumina’s HiSeq remains the most mainstream platform on the market.
However, constrained by the limited capabilities of bioinformatics technology, the accurate interpretation of massive sequencing data remains a critical challenge in genetic testing that urgently needs to be addressed. An increasing number of companies are beginning to establish their presence in upstream sequencing platforms. For instance, PacBio has acquired long-read sequencing technologies, and Fapon Biotech has acquired high-throughput sequencing platforms.
Raw genetic data consists of base sequences identified by the letters A, T, C, and G. The raw data extracted from gene sequencers resembles binary digital sequences in computers and cannot directly provide information about diseases. It must ultimately be transformed into biologically interpretable data to guide disease diagnosis and treatment, a process that requires analysis supported by specialized expertise.
Currently, the emergence and development of gene expression regulatory networks, signal transduction networks, protein-protein interaction networks, and metabolic networks have further propelled bioinformatics into the era of systems biology. In the early stages of bioinformatics, the primary focus was on sequence data. With improvements in both the quality and quantity of genomic research, particularly driven by second- and third-generation high-throughput sequencing technologies, the data encountered in bioinformatics has been greatly enriched in terms of type, nature, and volume. As an indispensable tool for genomic analysis, bioinformatics has rapidly developed and quickly expanded its reach into many fields, including human health.
The technical barriers to sequencing data processing and analysis are relatively high. Due to its critical importance, it has become a key bottleneck constraining the development of the midstream sector in the gene sequencing industry and represents the core competitiveness of major sequencing companies. Currently, while sequencing data processing workflows have largely been standardized, each company employs its own analytical methods for the core steps within the data processing pipeline. Even when using identical raw data, variations in algorithms and detail handling among different providers lead to divergent outputs, ultimately affecting the quality of sequencing data interpretation.
Genetic data is coalescing into massive databases. The ultimate vision is for every healthy individual or patient to upload their genetic data for analysis, enabling them to assess their health status and receive personalized health recommendations through comparative analysis. However, achieving ideal reliability and stability will require a prolonged period of data accumulation. The evolution of genetic testing into a routine clinical diagnostic modality, akin to complete blood count (CBC) and urinalysis, has, to some extent, accelerated this process.
Downstream applications of genetic testing can be categorized into two major groups: clinical and non-clinical applications. Each group can be further subdivided into vertical sectors such as reproductive health, pathogen infection detection, tumor genetic testing, basic medical research, and new drug development. Among these, basic medical research within non-clinical applications was the earliest field to achieve commercialization in gene sequencing and remains the most mature application scenario to date. This is followed by clinical applications, including tumor genetic testing, reproductive health, and pathogen infection monitoring.
In this process, bioinformatics is not only a discipline but also a crucial research and development tool. Bioinformatics tools are virtually indispensable for future biological research and biopharmaceutical development. As a powerful instrument for interpreting biological data, bioinformatics serves as the key link connecting gene sequences to personalized medicine. Currently, researchers in the field of bioinformatics primarily focus on genomics, proteomics, transcriptomics, RNA-omics, and other omics disciplines, as well as drug design closely related to these fields. The most common applications of bioinformatics include sequencing, database resources, sequence alignment, gene chip and expression profile analysis, molecular evolutionary analysis, protein structure analysis, and computer-aided drug design.
Clinical Applications of Intelligent Exploration in Genetic Testing
Tumor
The clinical application of genetic technology has truly ignited industry enthusiasm only when it reached the field of tumor diagnosis and treatment. Precisely because of this, the rich samples and data accumulated under intense “red ocean” competition have made tumor diagnosis and treatment the vanguard in the governance and development of genetic big data, and even in its analysis based on artificial intelligence technologies.
Following the initial period of unguided expansion, an increasing number of tumor gene databases based on Chinese populations have become available for clinical use. However, the broader field of genomic big data still lacks unified standards, with multiple data silos coexisting, preventing the full exploitation of big data value to meet clinical needs. In other words, China’s genomics industry urgently needs to establish standardized processes for sample collection, transportation, storage, testing, bioinformatic analysis, and genetic counseling interpretation. These standards would regulate multi-gene panel testing workflows and address projects related to clinical data support and sharing mechanisms.
As public awareness of genetic technology deepens in China and the supply-side ecosystem of the gene sequencing industry continues to improve, the pace of building large-scale population genomic databases has accelerated significantly. Most tumor next-generation sequencing (NGS) companies are establishing and developing large tumor genomic databases as their second growth curve. For instance, BGI Genomics, TrueQuest Medicine, GenePlus, RenDong Medical, and ZhiBen Medical have all deployed tumor genomic databases targeting different cancer types and encompassing populations of varying sizes.
At present, sporadic AI-based tumor genomics interpretation products have been introduced in certain specific vertical fields. For example, iGenome® Reporter, under ZhiNuoweiSi, is an NGS gene testing data analysis system. Based on the GVC gene variant detection algorithm and a medical interpretation knowledge base, it rapidly and accurately analyzes and interprets NGS data from tumor samples. With minimal operation, comprehensive clinical laboratory reports and/or research reports can be generated from raw sequencing data, assisting users in making clinical diagnosis and treatment decisions and facilitating research outputs.
As a result, the barrier to entry for tumor genomics research has been further lowered, while small gene companies engaged in downstream product development have seen their production and R&D capabilities strengthened.
Infectious Diseases and Genetic Disorders
In reality, most gene sequencing companies excel only at basic sequencing and fundamental molecular biology annotation. They lack a deep understanding of diseases and genetic mechanisms, creating a gap between their offerings and the needs of end users such as physicians and researchers. Furthermore, their inflexible output results increase user costs to some extent. For individuals without a background in bioinformatics, raw sequencing data holds virtually no practical value.
Most genetic diseases are complex disorders caused by multiple genes. Genome-wide association study (GWAS) is a high-throughput analytical method closely related to gene sequencing, which has become increasingly popular in research in recent years. Routine analyses in genetics and molecular biology laboratories typically involve aligning DNA or protein sequences of interest with reference databases; these sequences are generally much shorter than the entire genome, resulting in lower analytical throughput. However, in recent years, with the exponential growth of biological data and the limitations of single-gene studies, bioinformatics-based high-throughput analytical methods have become increasingly indispensable. Particularly, due to the rapid decline in sequencing costs and the swift advancement of bioinformatics, the threshold for applying high-throughput analytical methods has been further lowered. GWAS has thus emerged as one of the most common and increasingly routine bioinformatics high-throughput analytical approaches in research.
For human genome research, genome-wide association studies (GWAS) involve identifying single nucleotide polymorphism (SNP) data across the entire human genome and screening for SNPs associated with specific traits (such as body weight, height, particular diseases, drug sensitivity, etc.). In GWAS, researchers typically first collect sufficient genomic data from patients, compare the SNP loci with those of a control group, and perform association analysis on the relevant data to establish correlations between sequence data and target traits, thereby identifying potential genes closely related to the target traits. Often, after this in silico analysis is completed, experimental biological methods are required for validation and further investigation. By incorporating multidimensional, massive datasets into research, this approach has helped researchers discover many previously unknown genes and chromosomal regions, providing more clues to the pathogenesis of complex diseases.
Consumer-Grade Genetic Testing
Consumer-grade genetic testing refers to genetic testing products that are recognizable and directly purchasable by consumers through advertising, e-commerce platforms, and brick-and-mortar stores. These products primarily rely on low-throughput testing, utilizing technical methods such as PCR and gene chips. In the early stages of the development of consumer genomics in China, products were mainly focused on dimensions such as health management.
The consumer-grade genetic testing market in China was established approximately 20 years later than that in the United States and is currently in its early stages of development. Chinese consumers have not yet fully accepted or adopted consumer-grade genetic testing services as a means of health management. However, given China’s large population, aging demographics, and the growing trend toward personalized health management, the future outlook for China’s consumer-grade genetic testing market remains promising.
The academic community’s understanding of the relationship between genes and diseases remains largely at the stage of associative studies, rather than confirmatory research. Compared with genetic testing in the rigorous medical field, consumer-grade genetic testing companies generally face challenges such as insufficient testing depth, difficulties in achieving scalable profitability, and limited consumer awareness. In particular, the primary service offered by domestic consumer-grade genetic testing is health management, which requires the integration of clinical data, user health data, and genetic data. However, current clinical data and user health data are both relatively weak, and the results of consumer genetic testing products are not interpreted by professional medical personnel. Under these circumstances, even with large volumes of genetic data, effective guidance for health management cannot be provided.
Amid the generally unfavorable macro environment for the consumer-grade genetic testing industry, multiple companies have implemented strategic adjustments to promote the intelligentization of consumer genetic testing, thereby enhancing the stability and accuracy of genetic tests.
Automation is the foundation of intelligence. Meinian Gene has enhanced its genetic testing capabilities by implementing a highly automated production system, becoming the first and only genetic testing platform in China with a daily testing capacity exceeding 50,000 tests. Looking ahead, Meinian will further integrate genetic technology with information technology to achieve advanced levels of automation and intelligence in genetic testing. This will enable the company to bring more cost-effective products and services to market, thereby promoting the widespread adoption of consumer-grade genetic testing.
Non-Clinical Applications in the Intelligent Exploration of Genetic Testing
The intersection of genomics and drug development is becoming increasingly prominent, with many pharmaceutical companies establishing their own genomics departments to guide new drug discovery. Many of the CD-series targets we are familiar with today emerged from this wave. Given the massive volume of data generated by genomic sequencing, leveraging computational and big data technologies is indispensable for data cleaning and utilization in drug development.
For targeted therapies, biomarkers play a pivotal role, as they are correlated with drug sensitivity and response rates. Traditionally, drug developers have identified biomarkers based on existing knowledge, commonly using the drug target itself as the biomarker. While this approach is intuitive and has yielded numerous successful cases, its limitations are evident. Given the limited understanding of human biology and disease mechanisms, the majority of clinical trials actually fail to incorporate biomarkers, particularly those that fail in Phase III.
In fact, the initial Phase III clinical trial of Iressa, the blockbuster drug for lung cancer, also failed. The originator, AstraZeneca, did not identify a biomarker, and it was ultimately two laboratories at Harvard University that discovered EGFR mutations as the biomarker for Iressa.
Analyses suggest that the largest market for genetic information stems from pharmaceutical companies’ demand for clinical data in drug development. In 2014, total R&D expenditure by U.S. pharmaceutical companies amounted to approximately $140 billion, with only 3–4% allocated to purchasing clinical data, including genetic information, medication records, medical histories, and other related data. Although genetic information currently accounts for a relatively small proportion of drug development costs, its share is expected to rise gradually in the coming years.
Report Contents
Chapter 1: Current Status and Opportunities of Intelligent Genetic Testing
I. Policies and Regulations: New Healthcare Reform and New Infrastructure for Life and Health Propel the Gene Testing Industry into Rapid Intelligentization
II. Market Size: The Surge in Demand for Precision Medicine and the Super-Moore’s Law Decline in Genetic Testing Costs
III. Growth Stage: Disease relationships and algorithm validation are relatively complex, and the intelligence of genetic testing is still in its early stages
IV. Capital Enthusiasm: Giants in Computing, the Internet, and Gene Sequencing Platforms Enter the Fray, Driving Industry Transformation
V. Market Roles: Five Key Roles Build the Ecosystem, with First-Generation Products Already on the Market to Drive Improved Testing Efficiency
Article 2: An Ecological Analysis of the Intelligentization of Genetic Testing
I. Overview of the Industrial Chain
II. Upstream Analysis: Subtle Shifts in the Competitive Landscape
III. Midstream Analysis: Growing Importance
IV. Downstream Analysis: Applications and Products Make Frequent Appearances
Part III: Exploring the Application of Intelligent Genetic Testing
I. Clinical Applications
II. Non-clinical Applications
Part IV Typical Cases

Scan the mini-program QR code to download the report