Yiming Tech Tops CBLUE 2.0 Benchmark in Chinese Medical NLP with 1M-MedBert Model
Recently, 1M-MedBert, a large-scale medical language model independently developed by Beijing Yiming Technology Co., Ltd., participated in the Chinese Medical Named Entity Recognition (CMeEE) task of the CBLUE 2.0 benchmark for Chinese medical information processing and ranked first! It outperformed teams from many well-known domestic artificial intelligence enterprises and research institutions. This fully demonstrates that Beijing Yiming’s self-developed 1M-MedBert model holds a leading position in the field of Chinese medical information processing. Beijing Yiming Technology Co., Ltd. will leverage the 1M-MedBert model to undertake more natural language processing tasks in the medical domain and plans to open-source the 1M-MedBert model in the future, thereby promoting the development of Chinese medical information processing.
CBLUE (Chinese Biomedical Language Understanding Evaluation), a benchmark for Chinese medical information processing, was initiated by the Professional Committee on Medical Health and Bioinformatics Processing of the Chinese Information Processing Society of China under the principle of lawful open sharing, and organized by the Alibaba Cloud Tianchi Platform, with the aim of promoting the development of Chinese medical NLP technology and community. Participating institutions in the challenge leaderboard include well-known domestic organizations such as Unisound, AISpeech, Xi’an Jiaotong University, and the Institute of Automation of the Chinese Academy of Sciences.
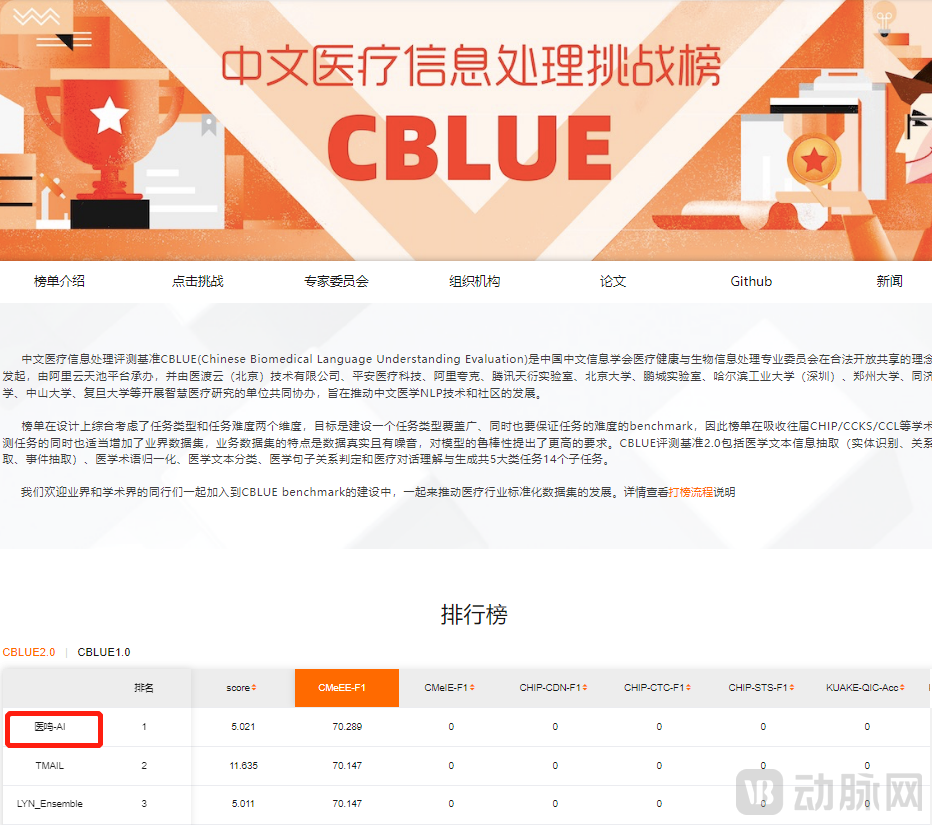
Figure 1. Yiming Technology’s Ranking in the CBLUE2.0-CMeEE Task
The greatest challenge in medical data processing lies in the accurate handling of unstructured data, such as medical records. Leveraging its advantages in data accumulation and medical expertise, combined with artificial intelligence technologies, Beijing Yiming has developed its own large-scale medical language model, 1M-MedBert. This model supports various downstream natural language processing tasks in the medical field, including medical named entity recognition and medical text classification.
For instance, in the task of adverse event recognition from medical texts conducted in collaboration with hospitals, Beijing Yiming Technology Co., Ltd. employed 1M-MedBert as the medical language model, combined with named entity recognition algorithms, to extract named entities from medical texts. Subsequently, a medical rule base was utilized to determine whether these named entities constituted adverse events. This approach has been endorsed by the National Medical Center, underscoring the significant practical value of the 1M-MedBert medical language model.