AI in Drug Discovery: Separating Reality from Hype
Over the past year, VBInsight has closely monitored developments in the field of AI-driven new drug discovery. We have interviewed numerous entrepreneurs and scientists passionate about AI-enabled drug development, most of whom believe that with sufficient confidence, patience, and a robust, collaborative ecosystem, a “ChatGPT for the pharmaceutical industry” is just around the corner. Of course, differing perspectives have also emerged at various industry conferences and smaller discussion forums. Some entrepreneurs have pointed out that many informatization efforts are currently mistaken for digitalization. Meanwhile, certain CADD (Computer-Aided Drug Design) experts have questioned whether AI’s current role is overhyped, citing excessive investment and insufficient returns.
Although AI’s practical applications in text generation and image recognition have been widely acknowledged, its progress in drug discovery remains difficult to quantify and validate. What can AI-driven drug discovery (AIDD) achieve that computer-aided drug design (CADD) cannot? How effective are molecules designed using AI technologies, and do they exhibit higher druggability rates? These questions have sparked ongoing debate within the industry.
A consensus holds that the prospects for AI-driven new drug development are promising, yet the field remains shrouded in uncertainty. In such times, both insiders and observers urgently need candid and distinct perspectives to distinguish reality from illusion.
In 2021, several researchers from the University of Cambridge, AstraZeneca, and the European Bioinformatics Institute published a two-part article in *Drug Discovery Today*, highlighting several genuine challenges currently facing AI-driven drug discovery (AIDD).
The article’s title highlights a persistent challenge plaguing the industry: in AI-driven drug development, what is reality and what are merely illusory expectations? How does AI function in this context, and why has it still fallen far short of our expectations?
VBInsight has compiled several key points from this article, hoping to provide cognitive inspiration for practitioners in the AI-driven new drug development sector.
Q1: From the perspective of CADD, how high should expectations be set for AIDD and emerging technologies?
CADD has a history of at least 40 years. In 1981, Fortune magazine declared it the beginning of “the next industrial revolution,” in which drugs would be designed on computers. The New England Journal of Medicine made the boldest prediction regarding the prospects of computational science, claiming in 1970 that its application in physician decision-support systems might even replace the role of doctors.
However, it was not until the few years leading up to the collapse of the “biotech bubble” in 2000 that increasing attention was paid to the use of computational methods in drug discovery.
Today, after more than two decades of development, the replacement of physicians has certainly not occurred, and not all expectations for CADD have been realized; however, we can now say that CADD has become a fundamental approach in drug development.
The story of CADD demonstrates that predicting the potential of current technological development from a specific point in time is not necessarily realistic or reliable.
In 2007, John Van Drie, who was involved in the early development of CADD, predicted that drug development technologies would achieve seven major advancements over the next two decades:
1. Computational thermodynamics will mature;
2. High-affinity ligands will be druggable;
3. Entirely new drug targets will emerge;
4. New molecular mechanisms of drug action will emerge (e.g., self-assembling drugs);
5. Unlike single-target inhibitors, they tend to simulate the overall signal transduction pathway, thereby enabling the selection of more optimal targets;
6. In the future, CADD will become a fundamental tool widely adopted by every medicinal chemist;
7. Virtual screening will be widely applied.
Most of the aforementioned predictions have come true. However, we found thatComputational chemistry has advanced much more rapidly than computational biology.. The fundamental thermodynamic principles governing ligand-receptor affinity are well established, although handling the flexibility of chemical structures remains challenging in practice. However, biological systems are significantly more complex; phenomena such as receptor conformational changes, equilibrium dynamics, and biased signaling are already difficult to elucidate. Downstream effects, such as alterations in gene expression or protein modification, pose even greater challenges, particularly when simulating spatiotemporal variations.
This remains a critical weakness in the current field of computational drug discovery, posing challenges for AI applications as well. While we can characterize chemistry effectively and have abundant alternative analytical data available for modeling—data that has been a key focus in the AI domain—it is far more difficult to define the range of model parameters when drugs act on biological systems. Consequently, we face greater uncertainty regarding which experimental data truly embody the key information related to efficacy or safety.
As we enhance our understanding of chemical systems, there is a growing tendency to prioritize data quantity over data quality (and relevance).For instance, the development of combinatorial chemistry in the 1980s and the emergence of high-throughput screening in the 1990s were both highly acclaimed at the time. These technologies undoubtedly enabled the generation of “more” data and significantly improved screening efficiency when targets were well-defined. However, these advancements did not disrupt the status quo of new drug development, as evidenced by the absence of a surge in the number of approved drugs.
Question 2: In evaluating the role of AI in drug development, which metric is more important: success rate, speed, or cost?
Certainly, the most important step in evaluating the role of AI in new drug discovery is to first assess quantitative metrics.
First, it is necessary to simulate the actual effects of several variables. Three scenarios are assumed: a 20% increase in speed, a 20% reduction in cost, and a 20% improvement in success rates at each stage of drug development. In this simulation, the patent term is assumed to be 20 years, with the patent application filed at the start of Phase I clinical trials. This approach is used to calculate the impact of changes in decision-making speed, cost, and success rate on the overall project return.
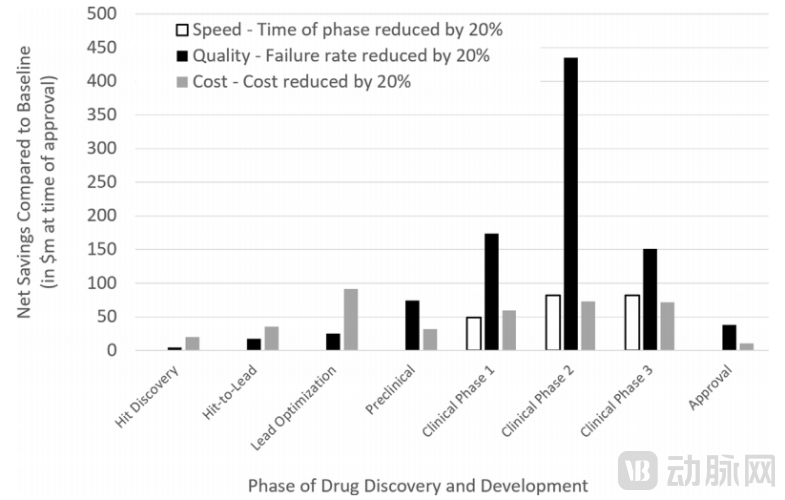
Figure 1. Impact of Drug Development Speed, Quality, and Cost on Return on Investment
The results showed that,Improving the success rate at each stage has the greatest impact on the overall value of a project, with this effect being most pronounced in Phase II clinical trials.. This is due to the relatively low success rate, long duration, and high costs associated with the clinical development phase. Improving the success rate in the clinical stage reduces the number of expensive clinical trials required to bring a drug to market; reducing the number of failures is more important than conducting faster or more numerous trial-and-error attempts.
In theory, AI can achieve all the aforementioned goals by enabling faster, cheaper, and higher-quality decision-making; in practice, however, “quality” is often overlooked.Based on the aforementioned quantitative results, it is evident that higher-quality molecules exert the greatest impact on the success of drug discovery programs, outweighing the benefits of increased speed and reduced costs. However, current AI applications in drug discovery appear to prioritize faster turnaround and lower expenses over the quality of decision-making.
For this very reason, there is an urgent desire to demonstrate that a new system can successfully achieve its objectives, but this often leads the industry to rush to validate trivial metrics rather than the quality of decision-making itself.This has led people to focus on trivial advances rather than demonstrating whether they truly expand the boundaries of traditional R&D methods.
While the industry largely remains fixated on improving the efficiency of molecular design and optimization, it is only through a deep understanding of the mechanism of action (MOA) and disease mechanisms that AI can truly fulfill its potential: 1. selecting higher-quality clinical candidate compounds; 2. enhancing target validation to reduce clinical failures due to lack of efficacy, particularly in Phase II/III trials; 3. improving patient selection; and 4. optimizing clinical trial execution.
For the AI-driven new drug industry, how we define R&D success and which metrics we should focus on are just as important as how we build our models.
Q3: Is AI Used for Drug Discovery or Ligand Discovery?
Although it is well established that AI requires high-quality decision-making, the surrogate data generated by high-throughput systems in recent decades has been insufficient to fully support AI applications. The generation of such large-scale high-throughput surrogate data is driven partly by its genuine practical relevance, but also, to some extent, by industry imperatives favoring low cost and high speed.
In practice,The numerous alternative data sets at our disposal offer extremely limited value for decision-making; current AI applications remain confined to ligand discovery rather than drug discovery.
Many notable advances have focused on the chemical aspects of AI-driven drug discovery, while overlooking the need for a deeper understanding of biology.For instance, the application of large-scale comparative analyses, deep learning methods, matrix factorization, and the incorporation of cellular morphology. Data in these fields have been extensively annotated for data mining; therefore, computational analysis can significantly impact the prediction of ligand-protein interactions.
However,We need to establish the link between a specific mechanism of action and the disease to enable the compound to demonstrate the desired therapeutic efficacy in vivo.The field of target identification has been active for many years, employing approaches such as whole-genome sequencing, functional genomics, and CRISPR editing. However, the relationship between identified targets and diseases is not as clear-cut as hoped, nor is it entirely feasible from a drug discovery perspective. Furthermore, even if specific genes or proteins causally linked to a disease are identified, this does not necessarily mean that the disease can be cured through small-molecule targeted therapy.
To validate AI systems in drug discovery, we need to shift toward more complex biological (and clinical) systems. At the computational level, this means incorporating more predictive endpoints related to efficacy and safety into the models. Of course, this may require generating new data, which can be far more complex and challenging to optimize than single-endpoint data.
Final Remarks
How Significant a Role Can AI Play in Drug Discovery? This Article Offers the Following Assessment:Given the current methods of data generation and utilization, it is unlikely that we can leverage AI to make better decisions that would improve the success rate of drug discovery.Although chemical data are abundant and have been successfully applied to ligand design and synthesis, AI has not yet been fully leveraged across the entire drug discovery process.
Meanwhile,Current AI applications lack a deep understanding of biology; AI models trained on chemical data have limited predictive power regarding the efficacy and safety of drugs in vivo.Therefore, it is necessary to generate and leverage more biological data to enable higher-quality candidate compounds to enter clinical trials, better validate targets, improve patient recruitment, and enhance the execution of clinical trials.
In light of the specific data-level challenges in drug discovery outlined in the following section, we find that AI requires data that is properly formatted and purpose-driven. To truly leverage chemical and biological data for drug discovery,Rather than allowing technology to drive data generation, we should place greater emphasis on a demand-driven approach, where data production is pulled by scientific needs at their source.
In fact, those working within the AI-driven new drug development industry are the first to perceive these limitations and the quickest to take action.
Published in February 2021, this paper invites a retrospective view two years later on its incisive questions, revealing that certain breakthroughs have already been achieved: CytoReason has established disease models at the cellular level, leveraging machine learning techniques to integrate genetics, genomics, proteomics, and medical literature, thereby mapping immune system interactions across hundreds of cell types. In China, Zheyuan Technology, incubated by the Institute of Computing Technology of the Chinese Academy of Sciences, has adopted a model similar to that of CytoReason. It focuses on discovering new targets and their mechanisms for specific diseases, matching indications with superior clinical efficacy and identifying optimal patient populations, thus expanding post-marketing indications for drugs.
It is foreseeable that technological development will continue to encounter a steady stream of new challenges. The industry will always need incisive questioners, as well as innovators who are courageous enough to tackle frontier issues.
References:
1.Bender A, Cortés-Ciriano I. Artificial intelligence in drug discovery: what is realistic, what are illusions? Part 1: Ways to make an impact, and why we are not there yet. Drug Discov Today. 2021 Feb;26(2):511-524. doi: 10.1016/j.drudis.2020.12.009. Epub 2020 Dec 17. PMID: 33346134.
2.Bender A, Cortes-Ciriano I. Artificial intelligence in drug discovery: what is realistic, what are illusions? Part 2: a discussion of chemical and biological data. Drug Discov Today. 2021 Apr;26(4):1040-1052. doi: 10.1016/j.drudis.2020.11.037. Epub 2021 Jan 27. PMID: 33508423; PMCID: PMC8132984.