Is Medical Data Assetization Feasible After the Establishment of China's National Data Administration?
It has been three years since the State Council designated “data” as the fifth major factor of production. Subsequently,“14th Five-Year Plan” for the Development of the Big Data Industryrelease,“Twenty Data Measures”the issuance of,National Data Bureauthe establishment of which are driving data toward marketization, even transforming it into an asset.
However, the role of data in value creation and wealth generation remains marginal to date, with particularly sluggish progress in the healthcare sector. Despite years of efforts to promote interoperability, a national health platform has been established at the macro level, and silos between departments have been broken down at the micro level; yet hospitals remain isolated from one another, confining both scientific research and patient care within the boundaries of individual institutions.
Before commercialization can be realized, the hurdle of “data sharing” must first be overcome. At the Two Sessions held a few days ago, Zhao Hong, a member of the National Committee of the Chinese People’s Political Consultative Conference and Deputy Director of the Department of Hepatobiliary Surgery at the Cancer Hospital of the Chinese Academy of Medical Sciences, summarized the various challenges facing health data within medical data into eight Chinese characters:
“Reluctant to Share, Unwilling to Share”。
Overcoming the “reluctance” and “unwillingness” is no simple task. Standing between institutions—including pharmaceutical companies, commercial insurers, and other non-medical entities—are formidable barriers such as top-level design, infrastructure development, value assessment, and distribution mechanisms. Every link involved in this process represents a significant hurdle that makes sharing medical data exceptionally challenging.
Medical data within hospitals can be broadly categorized into four areas: operational, clinical, health, and biological. The implementation of Diagnosis-Related Groups (DRG) and the establishment of the National Gene Bank have effectively promoted the application, sharing, and even commercialization of operational and biological data, partially achieving a degree of “assetization.” However, health data and clinical data remain in the exploratory stage of the “sharing” model.
At its core, clinical data and health data pertain to individual patients, and the inherent structural complexity of these data makes standardization difficult. Consequently, although the National Health Medical Big Data Center (Northern Center) has been fully established, and regional population health information platforms have been set up in 100% of provinces, 85% of cities, and 69% of counties across China, with hospitals possessing vast amounts of continuously updated clinical data, the application and sharing of these two types of data remain limited due to factors such as inadequate standards for informatization construction and inconsistent data specifications.
The widely recognized “Health Code” and “Infectious Disease Surveillance” are relatively mature applications of health data today, but the logic of such applications remains at the level of “statistics,” without in-depth mining of health data.
Clinical data is more focused than general health data, making it more difficult to share. Cross-hospital sharing of clinical data can effectively accelerate the R&D processes of pharmaceutical and medical device companies; establish comprehensive, lifelong patient records; and reduce the waste of medical resources and health insurance funds caused by redundant examinations. However, to realize this value, the first step is to achieve data sharing within individual hospitals, followed by inter-hospital sharing.
Let’s begin with intra-hospital data sharing. Clinical medical data typically undergoes a complex transformation process from generation to reaching an initial state suitable for sharing. First, hospitals must organize data generated from various sources—such as terminal-generated data (e.g., CT, MRI, and pathology images) and manually entered data (e.g., past medical history and patient chief complaints)—into respective data management systems (such as PACS, HIS, and PIMS). The data is then centrally stored in on-premises server rooms or the cloud, and subsequently processed and governed by manual efforts or big data centers to produce standardized datasets.
During this process, data stored in server rooms often becomes highly heterogeneous due to inconsistent data structures across terminal systems, varied manual entries by physicians, and differing levels of granularity in data dimensions provided by various data management systems. While interoperability among systems may appear functional on the surface, practical usage reveals challenges such as missing data dimensions for certain records and inconsistent terminology for the same medical conditions, making precise categorization difficult. Currently, the introduction of integration platforms and big data centers has partially addressed data interoperability issues; however, unifying interfaces across management systems such as HIS and PACS would involve complex stakeholder interests, including numerous health IT vendors and clinical departments.
The same issue, when extended to the inter-hospital level, will be further amplified, requiring data sharing while also overcoming additional constraints.
First,Lack of Top-Level DesignOn the one hand, the construction of past information systems lacked unified guidelines, resulting in varying standards across hospitals, disparate database structures supporting business digitalization, and differences in data collection capabilities. Consequently, even within the same region, there are significant discrepancies in the quality of data submitted by tertiary, secondary, and primary care hospitals. As a result, when implementers attempt to collect specific data, they often find that the system construction standards and database table structures generating such data vary widely. Even if data are collected according to unified standards, interpretation and cleaning remain highly challenging.
On the other hand, data collection methods vary across hospitals. For instance, tertiary hospitals and most secondary hospitals obtain data through direct database connectivity, which helps ensure relatively high data quality. However, many primary healthcare institutions, constrained by inadequate information technology capabilities, often rely on manual data entry. Given the existing shortage of physicians in these primary care settings, data reporting tasks are frequently delegated to nurses or non-medical personnel. Consequently, the data submitted by these groups is inconsistent, leading to significant variations in data quality from the same source. According to the "bucket effect," the inclusion of poor-quality data into the database drags down overall data quality, rendering it difficult to utilize effectively.
Therefore, despite the strong public demand for open access to residents’ health record data, a key reason for the slow pace of progress at this stage is the poor quality of medical data. Without substantial investment in data governance and processing, the health record data returned to residents is prone to significant biases.
Secondly,Issues of Property Rights and DistributionCurrent legal frameworks are still inadequate in explaining and defining the ownership of health and medical data, particularly with regard to the ownership of medical data. Wang Bing, General Manager of the National Health and Medical Big Data (East) Center, told VCBeat that the primary reason for the suboptimal utilization of medical data is its fragmented distribution across various entities. Government agencies, healthcare institutions, academic and research institutions, and certain health and medical enterprises have accumulated corresponding health and medical data resources through their long-term operations, making them the de facto owners and controllers of various types of health and medical data. This directly makes it difficult to define data ownership. As raw data undergoes continuous processing, the ownership of medical data becomes even more ambiguous. For example, when a patient undergoes a CT scan at a hospital, the original imaging data constitutes one dataset; once physicians’ diagnostic information is added to this imaging dataset, a new dataset is generated.
Currently, there is a view that medical big data reflects an individual's health status and should therefore belong to the patient. Another perspective holds that since medical big data is generated through collection and entry by hospitals, and is stored and maintained within medical institutions, it should rightfully belong to these institutions. A third viewpoint suggests that while ownership of medical data lies with the individual patient, control rests with the hospital, and management authority resides with the government; thus, third-party entities require government support and hospital cooperation to commercially develop and utilize such data. Despite ongoing debates, in practice, the rights to medical big data largely reside with hospitals. The ambiguity surrounding the ownership of medical data not only hinders the authorized use of health and medical data but also poses challenges and creates hidden risks for the protection of patients' personal information rights.
In terms of allocation, the difference between data and traditional factors of production lies in the method of calculating its economic value. Wang Bing believes that it is difficult to design a pathway for confirming data value based on economic principles. Given the aforementioned challenges in data collection and significant variations in data quality, managers are unable to accurately measure or finely control the costs associated with the front-end processes (collection, storage, and governance) when calculating the economic value of medical data. Consequently, the substantial investments made by market entities in processing semi-finished data products often fail to yield marketable products capable of attracting a sufficient user base. “It is like panning for gold dust in the desert. Everyone knows that gold dust is valuable, but when the costs of panning and processing, product quality, and market expectations are all difficult to estimate, enterprises lack the incentive to invest, leaving the gold dust dormant in the desert.”
Finally, it should be noted thatData Privacy and Security. Data security, being relevant to all industries, has relatively mature solutions. Moreover, driven by the requirements of Classified Protection 2.0 for hospital data security infrastructure, many hospitals have already implemented a certain level of security measures. However, when it comes to data sharing, hospitals need to adopt new strategies for secure data exchange.
Revisiting Data Privacy. In specific patient medical records, basic information such as the patient’s name and ID number is often used as a unique identifier; however, such information also falls within the scope of protected data. Therefore, the appropriate approach is to anonymize the data without compromising its accuracy.
It is important to note that different types of information hold varying values in privacy protection. Therefore, applying high-level protective measures uniformly to all medical information would impair the efficiency of practical applications and result in resource waste. Consequently, hospitals should establish a comprehensive data classification system and adopt differentiated protective measures for different categories of personal information and data.
Despite the numerous barriers to sharing clinical and health data, there is ample experience available to draw upon when designing solutions.
A comparison of operational and biological data reveals that their rapid sharing within the sensitive realm of medical data is attributable to the dominant role played by policies in data standardization. These policies have established definitive data structures, delegated deadlines for data submission, and provided substantial rewards to institutions that fulfill these tasks.
Therefore, to achieve unification of clinical and health data on a broader scale, it is essential to implement sophisticated designs for data structures, transmission mechanisms, and incentive schemes at the upper level. As Director Zhao Hong stated during the Two Sessions, detailed implementation rules should be issued as soon as possible, principles for the distribution of benefits from health and medical data sharing should be established, and policies should be enacted to encourage the participation of diverse stakeholders in the sharing and application of health and medical data.
I. Based on the “Twenty Measures for Data,” it is recommended that the National Health Commission clarify investment models and assessment criteria for local data governance, standardize data formats and terminologies, and link patients’ diagnosis and treatment records to facilitate analysis, thereby ensuring that data quality meets the needs of researchers.
II. Establish comprehensive management protocols for the entire lifecycle of data sharing and application to provide a basis for local implementation; develop classification and grading standards for health and medical data, and formulate open and objective evaluation criteria by integrating factors such as data levels and intended uses.
3. In terms of usage, it is essential to promptly evaluate and rationally apply data security technologies, explore remote data sharing models that ensure “data availability without visibility,” and enhance researchers’ work efficiency. As laws and regulations concerning cross-border data transfer continue to be refined, timely issuance of guidance is also required to support activities such as the cross-border exchange of scientific research outcomes.
IV. It is recommended that the National Health Commission, in conjunction with the National Development and Reform Commission, clarify the principles for distributing benefits derived from the translation of research outcomes in the health and medical data sector. This should guide multiple stakeholders—including data platform regulators, operators, and users—to explore, within prescribed boundaries, the establishment of fee standards for data sharing and mechanisms for distributing revenues generated from the commercialization of applied research outcomes.
The standardization and sharing of clinical data can also be implemented following the aforementioned approach. The difference lies in the need to incorporate pharmaceutical and medical device companies—key users of clinical data—into the framework. On one hand, real-world studies require encouraging more patients to share their data; on the other hand, in response to the lack of transparency in clinical trials, patients can leverage the sharing system to provide unofficial oversight of pharmaceutical and medical device enterprises.
Overall, medical data sharing under a well-developed mechanism can effectively enhance the operational efficiency of the healthcare system and accelerate innovation in pharmaceutical and medical device R&D. However, there is still a long and arduous road ahead before we achieve the ideal foundational infrastructure.
Across China’s big data exchanges, many have included “medical and health” data in their tradable categories; however, only the Guizhou Big Data Exchange has listed a product titled “Speech Data for Early Screening of Childhood Dysarthria,” priced at RMB 250,000, with two transactions completed to date.
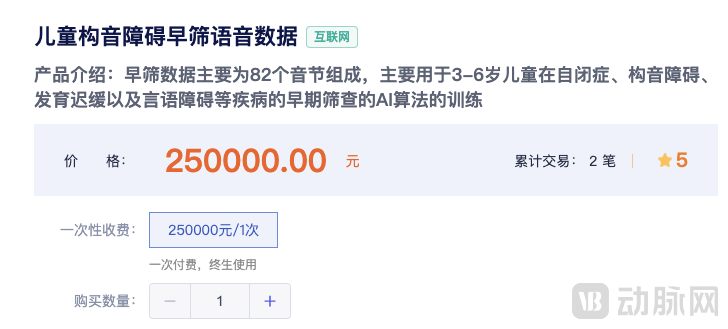 "Early Screening Speech Data for Childhood Dysarthria" Product Listed on the Guizhou Big Data Exchange
"Early Screening Speech Data for Childhood Dysarthria" Product Listed on the Guizhou Big Data Exchange
Therefore, to facilitate broader data trading, the assetization of medical data requires cautious exploration. It is advisable to wait for other sectors to take the lead in data assetization, thereby allowing the healthcare industry to refine its approach by learning from their prior practices.
Nevertheless, there is no need for excessive concern. The state’s policy support for data as a key factor of production has already driven rapid growth in the data industry in recent years. The establishment of the National Data Administration will also promote the development of data-related regulatory mechanisms, ensuring greater transparency and fairness in data transactions. In time, as we enter an era of more robust and comprehensive medical data sharing, the assetization of healthcare data may become more widely realized, accelerating the advancement of digital health.