From Trillion-Gene to Billion-Cell Atlas: AI-Powered Paradigm Shift in Cell and Gene Therapy Development

Profluent
Protein Designer

Basecamp Research
Protein Product Developer
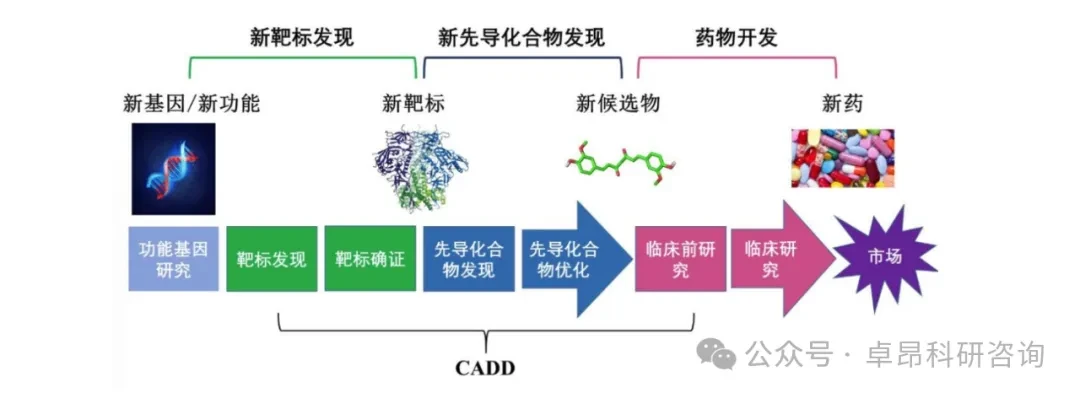
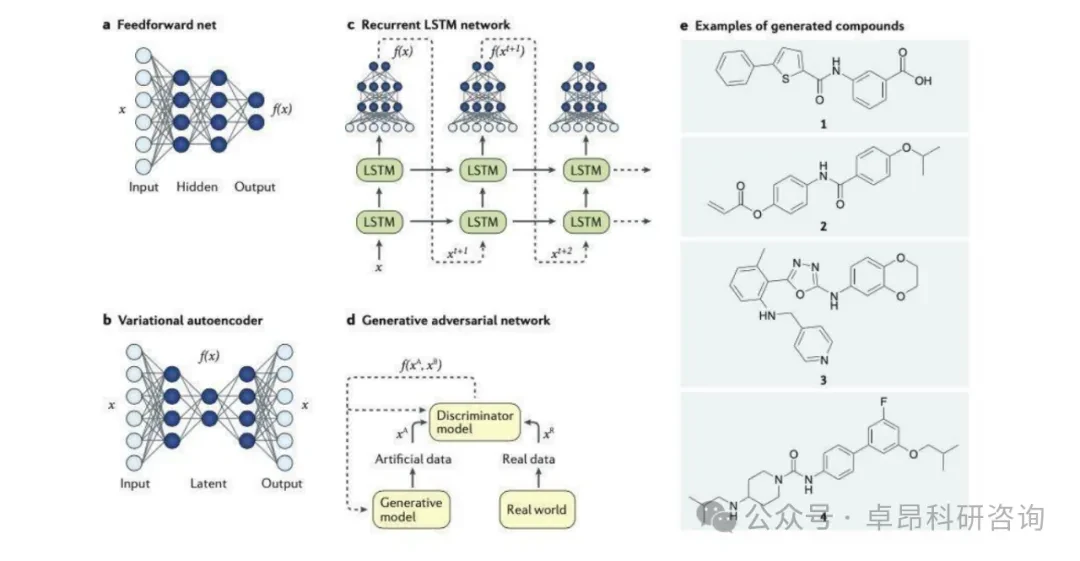
As artificial intelligence and big data technologies are deeply integrated, the cell and gene therapy field is accelerating towards a revolution driven by foundational technologies. Traditional new drug development and gene editing often face challenges such as long cycles, high costs, and difficult-to-overcome technical bottlenecks, but the intervention of AI is rapidly changing this situation.
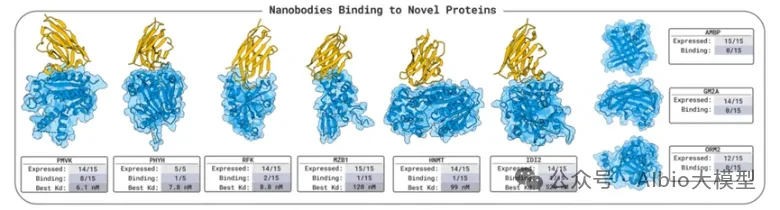
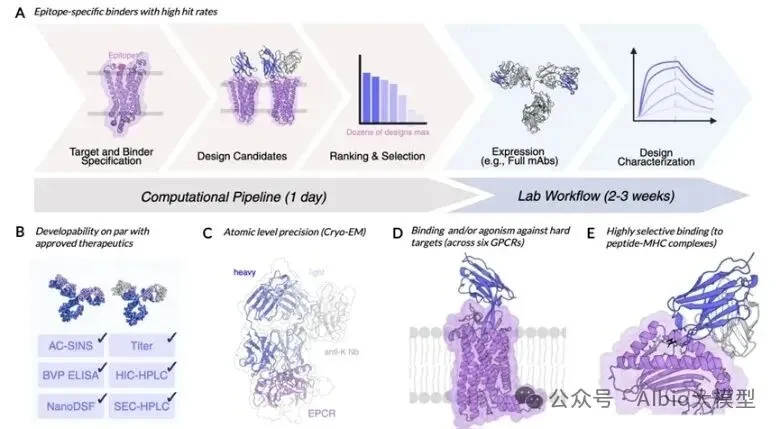
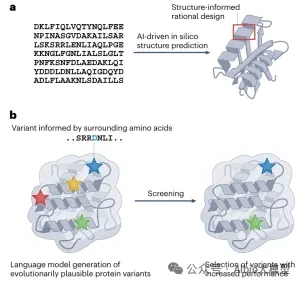
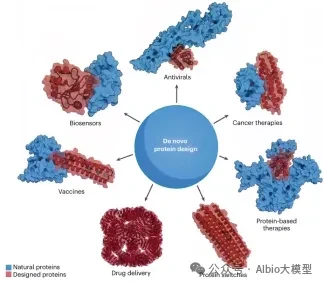
Recently,Eli LillyAnnounced a collaboration of up to $2.25 billion with Profluent, an AI-driven protein design company, to jointly develop gene therapies for genetic diseases. Profluent will leverage its proprietary AI platform to design customized recombinases targeting specific genomic sites, enabling large-scale, high-precision DNA editing that traditional technologies struggle to achieve. This partnership aims to address the challenge of developing universal therapies due to the high heterogeneity of patient mutations. By abandoning conventional biological discovery approaches, Profluent relies on vast amounts of natural recombinase data to train AI models, directly designing human genome-compatible customized recombinases on demand, effectively overcoming the high barrier of manually engineering complex recombinases. Not long ago, at NVIDIA GTC 2026, Basecamp Research partnered...PacBioMultiple institutions have launched the "Trillion Gene Atlas," leveraging AI infrastructure to enhance the understanding of genetic diversity a hundredfold. The EDEN model, trained on large-scale genomic data, has successfully achieved AI-programmable gene insertion (aiPGI) and validated CAR-T cell therapy in primary human T cells. The CAR-T cells designed through this method demonstrated powerful cancer cell killing ability, with a tumor cell clearance rate exceeding 90%. Additionally, earlier this year,,Global Genomics Sequencing GiantIlluminaLaunched the world's largest whole-genome genetic perturbation dataset, the "Billion Cell Atlas," with founding participants includingAstraZeneca, Merck and Eli LillySuch as global leading pharmaceutical R&D enterprises. This atlas records the responses of one billion individual cells to genetic changes through CRISPR, and is directly used for AI model training, target validation, and precision medicine R&D such as cell/gene therapy in these pharmaceutical companies.
AI Big Data is Reshaping the R&D Paradigm of Cell and Gene Therapy. As AI models continuously enhance their ability to analyze massive amounts of biological data, and cross-institutional collaboration deepens, AI-empowered cell and gene therapy will accelerate bridging the gap from laboratory to clinic, bringing tangible hope of a cure to more patients with difficult-to-treat diseases.
01 AI Builds Virtual CellsOnline Live Streaming Course
02 AI Protein Design Online Live Course
03 AI Antibody Design Online Live Course
04 Synthetic Biology and Gene Circuit Design
05 AI Gene Editing Online Live Course
06 Application of Deep Learning in Multi-Omics Integration
07 Advanced AIDD Artificial Intelligence Drug Design (Recorded)

Swipe to view






Swipe to view
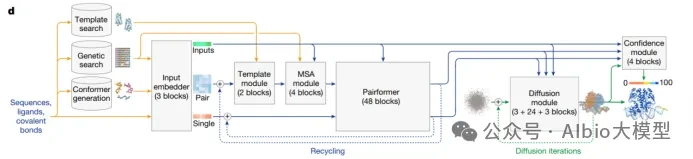
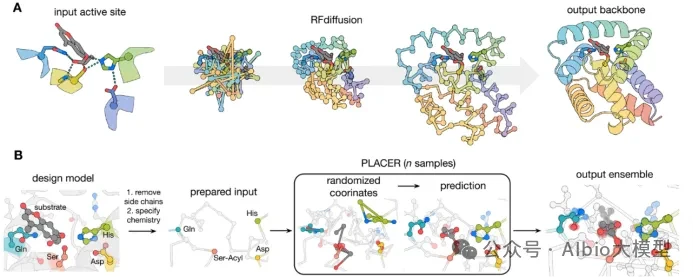
Case Practice Images:

Swipe to view

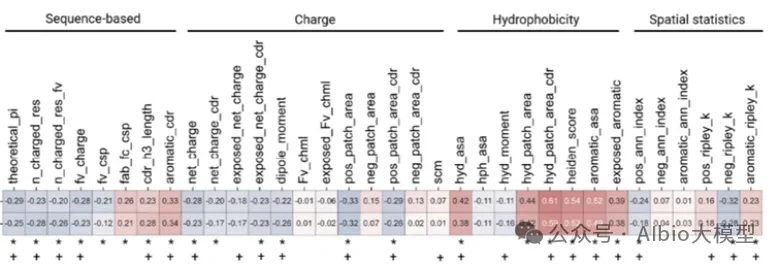
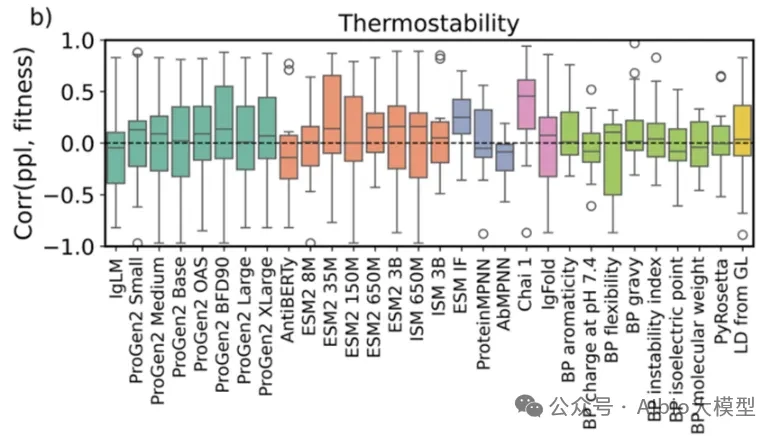
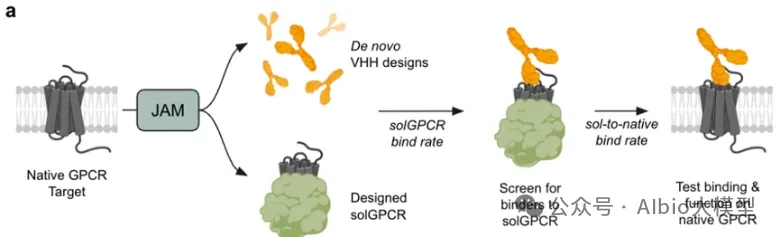
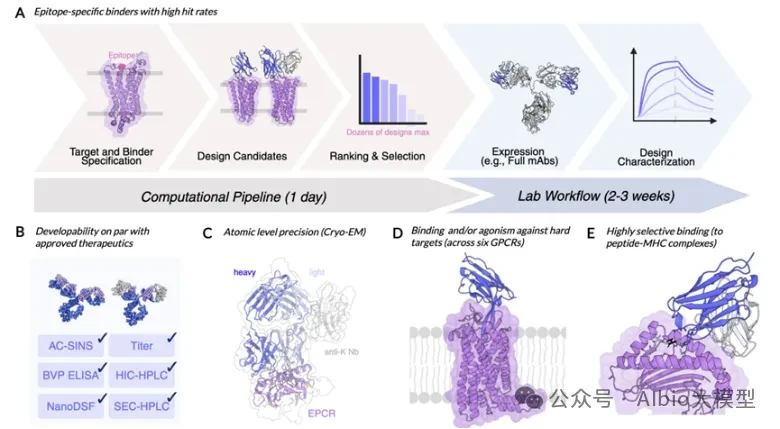

Case Practice Images:

Swipe to view
'%20fill='%23FFFFFF'%3E%3Crect%20x='249'%20y='126'%20width='1'%20height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
Case Study Images:

Swipe to view




Swipe to view

Swipe to view
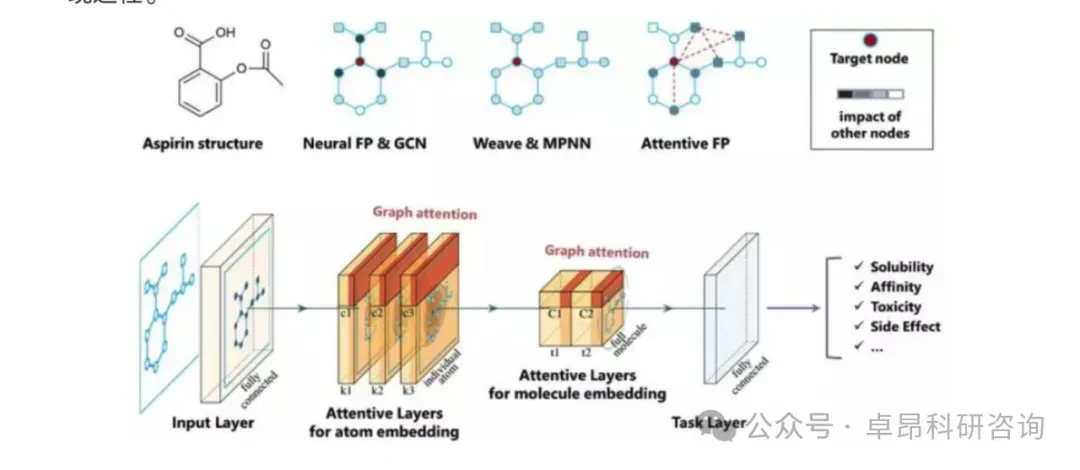
Introduction of the Lecturer


AI Protein Design and AI Antibody Design
The lecturer has extensive experience in algorithm development and application in both academia and industry. He earned his Ph.D. from a top research group in China, where he conducted research on protein structure prediction and protein design. His work has been published in internationally renowned journals such as Cell Systems, Angew. Chem. Int. Ed., and JCIM. He currently serves as a senior researcher at a well-known pharmaceutical company, leading the development of an AI-driven macromolecule drug design platform and managing the team.

Deep Learning Multi-Omics Integration
The main speaker, Dr. Liu, holds a Ph.D. in Bioinformatics and has been engaged in medical bioinformatics and artificial intelligence research for 15 years. He has conducted research on the application of multi-omics data in the diagnosis and treatment of complex diseases at the Genome Institute of Singapore and the University of California, Los Angeles. His research areas include artificial intelligence, natural language processing, functional genomics, metagenomics, transcriptomics, miRNA and target gene network analysis, single-cell sequencing data analysis, time-series analysis of gene regulatory networks, protein-protein interaction network analysis, and multi-omics integrated analysis. He has led four projects funded by provincial natural science foundations, developed several bioinformatics tools, published over 20 SCI papers, including more than 10 articles on artificial intelligence algorithms, and authored a practical textbook on medical data analysis.

AI Builds Virtual Cells

AI Gene Editing
The lecturer has many years of research experience and practical application in the academic field, coming from top-tier research groups in China. Engaged in the research work of integrating genome editing technology with artificial intelligence, the related achievements have been published in internationally renowned journals such as Nature Biotechnology, Nature Plants, and Trends in Biotechnology.

AIDD Drug Design
The lecturer is from Tianjin University, with over a decade of experience in computer algorithm research and programming. Research areas include deep learning for drug discovery and drug synthesis pathway design. The lecturer has published 10 high-level SCI papers in well-known journals such as BMC Bioinformatics, Journal of Biomedical Informatics, and International Journal of Molecular Sciences! Consistently receives high praise from students.

Synthetic Biology and Gene Circuit Design

Lecture Time




01.AI Protein Design
02.AI Antibody Design
03. Synthetic Biology and Gene Circuit Design
04.AI Builds Virtual Cells
2026.6.13-2026.6.14(09:00-11:30--13:30-17:00)
2026.6.25-2026.6.26(19:00-22:00)
2026.6.27-2026.6.28(09:00-11:30--13:30-17:00)
05.AI Gene Editing
06. Application of Deep Learning in Multi-Omics Integration
Tencent Meeting Live Streaming Class Replay available after class
07.AIDD Drug DevelopmentCurrent Design + Advanced Reproduction Video Recording
Provide full recorded broadcasts and code Q&A in the group.

Training Fees


Course Registration Fee:
AI Builds Virtual Cells,AI Protein Design, AI Gene Editing, AI Antibody Design:
Public Funding Price: ¥6,880 per person per class (including registration fee, training fee, and materials fee)
Self-funded Price: ¥6080 per person per class (including registration fee, training fee, and material fee)
Application of Deep Learning in Multi-Omics Integration, Synthetic Biology and Gene Circuit Design
Public Price: ¥5,880 per person per class (including registration fee, training fee, and material fee)
Self-funded Price: ¥5,580 per person per class (including registration fee, training fee, and materials fee)
Heavyweight Discounts:
Offer 1:
Buy Two, Get One Free (Sign up for two classes and get one learning spot free, the free class can be chosen freely)
Two Classes Together: 10,880 RMB (Can attend three live courses)
Three Classes Together: 14,880 RMB (Can attend four live courses)
Four classes together: 18,880 yuan (Can attend six live courses)
Special Offer 2: 24,880 RMB (Free access to any courses hosted by our institution for two full years)
Discount 3: Early registration and payment can enjoy a 300 yuan discount (limited to fifteen participants).
Special Offer: Register for One and Get Two Free, Register for Three and Get All Recordings Free(Bonus Replay)(Including full course replays and lecture materials PPT)
(Click to jump to the detailed link):
Playback One:This course is a video course! Machine Learning Biomedical Training!
Playback Two:This course is a video course! Single-cell spatial transcriptomics training!
Replay Three:This course is a video course! Comparative Genomics Training!
Replay Four:This course is a video course! Machine Learning Proteomics Training
Playback Five:This course is a video course! CRISPR-Cas9 Gene Editing Training!
Replay Six:This course is a video course! Protein Crystal Structure Analysis Training!
Replay Seven:This course is a video course! In-depth learning genomics training!
Playback Eight:This course is a video course! Machine Learning for Multi-omics Joint Analysis of Microbiome!

1. Course Features -- Comprehensive course technology application, principle process, and instance connections throughout.
2. Learning Mode -- Combining theoretical knowledge with hands-on operation, enabling beginners to quickly master the skills.
3. Course Service Q&A -- The main instructor will provide professional answers to the questions you encounter in your actual work.
Teaching Method: Online live streaming via Tencent Meeting, theory+Hands-on teaching mode, where the teacher guides students step by step through the operations.Starting from scratch, electronicPPTAnd TutorialsOne week before the course starts, all training software will be sent to the students in advance. If there are any questions, we will resolve them by voice communication, screen sharing, and answering questions in WeChat groups. Students and teachers can communicate, and students can also communicate with each other. After the training is completed, the teacher will continue to answer questions for a long time, and the training group will not be disbanded. Previous trainees have consistently given very high evaluations of the training quality and teaching methods!

Trainees Give High Evaluation to the Training
Tencent Meeting Live Streaming Q&A | Step-by-Step Operation Guidance


