2023 White Paper on Medical Big Data: From 'Factor of Production' to 'Asset' – How Far Is Data Circulation?
In the second decade after the millennium, the development of cutting-edge technologies such as mobile health and artificial intelligence spurred demand for medical data. As the most common yet hardest-to-obtain element among the three key factors—algorithms, computing power, and data—medical data at that time remained fragmented and non-standardized, scattered across various hospital systems. To secure the essential fuel for intelligent models, numerous health-tech startups partnered with tertiary hospitals, assisting them in data governance while developing smart clinical applications.
The participation of hospital departments, combined with mandatory policy requirements for informatization, has jointly driven hospitals to initiate large-scale construction focused on interoperability and smart hospital initiatives. Many hospitals have begun establishing hospital big data centers and research-grade big data platforms, completing the infrastructure for medical big data, and collaborating with enterprises to develop numerous intelligent applications.
However, after the onset of the China-U.S. trade dispute in 2019, medical data containing personal private information became a key focus of attention. Due to the potential risk of leakage associated with the governance, integration, and application of such data, the objectives of collaboration between hospitals and enterprises began to shift.
To mitigate the uncertainties associated with policy risks, many hospitals expect big data and its research outcomes to be confined within institutional boundaries, thereby shifting the focus of medical big data research toward meeting hospital-specific scientific needs. Under this trend, the commercial translation of medical big data has declined to some extent, leading to an overall slowdown in the development of the medical big data industry.
However, political factors are not the only constraints on the development of medical big data; greater attention should be paid to issues concerning return on investment and participation levels in such construction initiatives.
For the vast majority of hospitals, standardized IT infrastructure development both within and outside the institution represents an investment with difficult-to-quantify returns. In the absence of appropriate tools to estimate the output of big data initiatives, hospitals remain conservative in their approach to related investments.
Furthermore, for such initiatives to deliver value, financial support from the hospital is only part of the equation. More importantly, hospitals must gain a deep understanding of the components of medical big data infrastructure and effectively integrate systems with clinical operations, thereby establishing an effective big data framework.
Currently, various standards within hospitals are promoting the interoperability and mutual recognition of medical data, as well as its governance and application. However, it is still necessary to comprehensively execute a series of steps—including data collection, cleaning, aggregation, and storage—across the entire workflow for each type of scenario. This will enable the creation of multimodal, cross-process big data that can support practical applications, thereby truly consolidating medical data assets. Nevertheless, at present, hospitals lack the motivation to implement comprehensive, high-engagement data governance practices.
Applying the “factor of production” attribute to data may be the solution to the aforementioned problems. After all, only by shifting from passive application to proactive management of medical big data can we truly leverage its value and enable near-seamless data “circulation.”
Since April 2020, when the Central Committee of the Communist Party of China and the State Council issued the “Opinions on Building a More Complete System and Mechanism for Market-Based Allocation of Production Factors,” designating “data” as the fifth major factor of production alongside labor, land, and capital, favorable policies supporting big data have been introduced at regular intervals to drive the development of this industry.
Specifically, in November 2021, the “14th Five-Year Plan” for the Development of the Big Data Industry set a precise overall objective, requiring that “by 2025, the estimated scale of China’s big data industry will exceed RMB 3 trillion, with an average annual compound growth rate of approximately 25%, and a modern big data industrial system characterized by strong innovation capabilities, high value-added, and independent controllability will be basically established.”
In December 2022, the “Opinions of the Central Committee of the Communist Party of China and the State Council on Building a Basic Data System to Better Leverage the Role of Data as a Factor of Production” (hereinafter referred to as the “Twenty Measures on Data”) was publicly released. With the goal of establishing a foundational institutional framework, it comprehensively deployed measures for formulating basic data systems across four key areas: data property rights, circulation and trading, income distribution, and security governance. The ultimate objective is to establish a system wherein data factors participate in distribution according to their contributions, achieving a balance between fairness and efficiency.
In March 2023, the National Data Bureau was fully established, jointly administered by the Office of the Central Cyberspace Affairs Commission and the National Development and Reform Commission. These two agencies will coordinate to advance the development of foundational data systems, integrate and promote the sharing, development, and utilization of data resources, and spearhead the planning and construction of Digital China, the digital economy, and digital society.
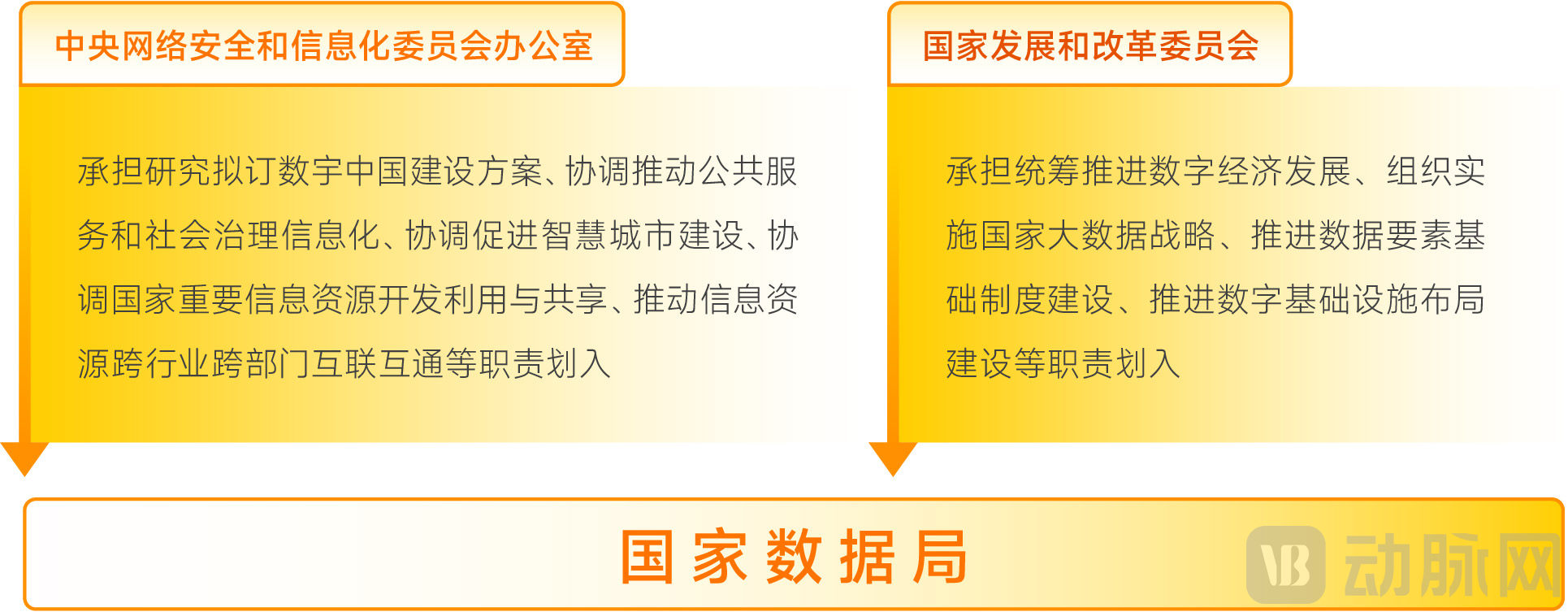 Image source: VCBeat.
Image source: VCBeat.
Technological iterations have also prompted a reevaluation of the value of data as a factor of production. In late 2022, the surge in popularity of the large language model (LLM) ChatGPT spurred a renewed assessment of the value of artificial intelligence, with a focus on generative AI, the underlying technology powering these applications. Starting in 2023, numerous medical IT companies, medical AI firms, and internet healthcare providers have developed their own large language models and begun exploring the development of novel AI applications within hospital settings.
Deconstructing this emerging artificial intelligence still reveals the four core elements: algorithms, computing power, data, and knowledge. However, for Chinese enterprises, the algorithmic component relies on open-source models; computing power can be secured by purchasing GPUs as needed; and knowledge can be acquired through purchases from authoritative knowledge bases or via strategic partnerships. The sole exception is data, which requires companies to collaborate with hospitals to train models under conditions that ensure data de-identification and remain within the hospital premises.
Dual Drivers of Policy and Technology Reignite the Medical Big Data Industry. Nowadays, more hospitals are beginning to participate in the development of big data infrastructure and applications, while large enterprises have also sensed the trend and are extensively engaging in the sector, injecting new vitality into the industry.
To leverage data effectively, the first step is always data collection. With the leapfrog development of information technology and network technology, the operational characteristics of modern hospitals are manifested in the intelligentization of medical services and the agile deployment of applications. This has driven the information generated by hospital operations toward greater complexity, specialization, and massive volume, thereby imposing higher-level requirements for interoperability among various systems.
Under this trend, the traditional approach to building data center facilities—centered on equipment operational characteristics such as network bandwidth, server performance, and switch processing capacity—fails to meet emerging demands for data security assurance, online business support, and data asset management under new data structures. There is an urgent need to introduce new IT architectures to address the novel requirements for computing, storage, and network resources driven by evolving business needs.
Consequently, some hospitals have begun to shift their approach to information technology development by leveraging cloud technologies to build next-generation hospital data centers. These centers integrate various data services to support clinical care, decision-making, and research processes, thereby enhancing the scientific rigor, standardization, and precision of hospital management.
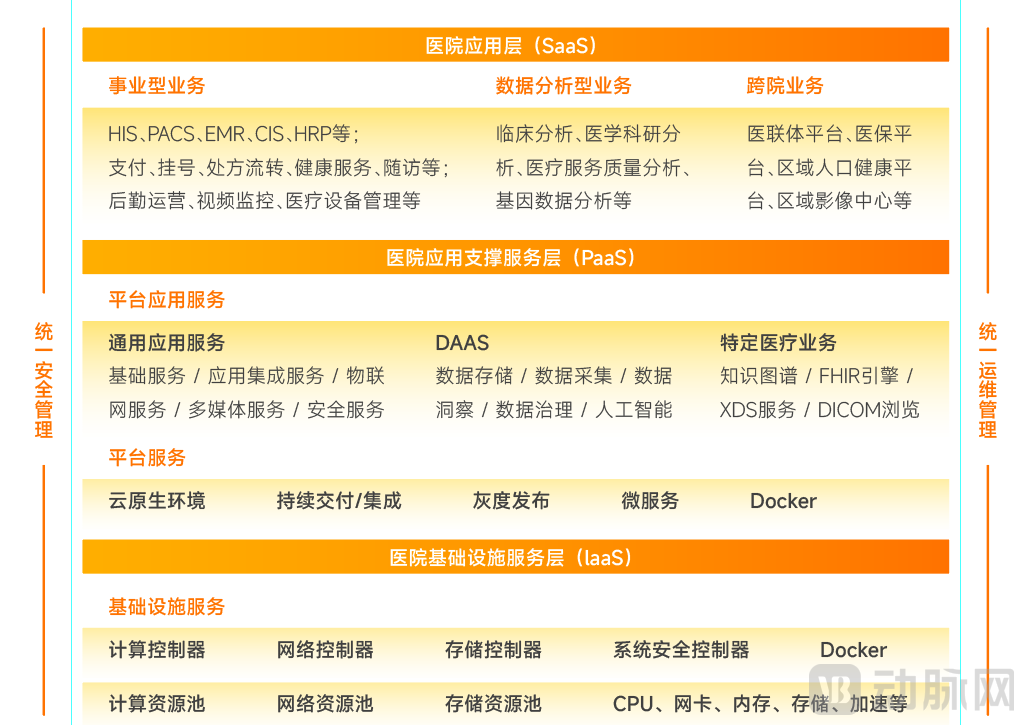 Next-Generation Hospital Data Center Architecture
Next-Generation Hospital Data Center Architecture
(Data source: VCBeat, Guidelines for the Construction of New-Generation Hospital Data Centers)
Traditional big data centers are categorized into two types. One is the Clinical Data Repository (CDR), which primarily supports business operations by integrating electronic medical records. Its role is to facilitate daily medical activities, collect and present data generated during medical processes, and generate routine statistical reports. The other type is a big data center focused on management and scientific research, designed to support clinical research, hospital administration, and intelligent product development, thereby meeting the needs for batch processing, mining, and analysis of data in research and managerial activities.
Currently, most hospital-wide Clinical Data Repositories (CDRs) in China have achieved physical aggregation of data from various hospital operational systems. However, the data quality remains at a raw level, and the underlying data architecture and logical relationships have yet to be structured. Consequently, conducting clinical data analysis and mining on existing CDRs remains highly challenging.
Furthermore, since different scientific research databases generally adopt customized data models, establishing multi-center data pools, data sharing, or data merging requires substantial time and resources for data mapping and recoding. Errors in this process can easily lead to confusion in computerized data retrieval, analysis procedures, and results.
To address the issues inherent in traditional big data centers, next-generation big data centers should possess the following capabilities.
1. Meet the hospital's innovative business needs.Provides a variety of big data application development tools and supports the deployment of big data applications, such as leveraging NLP to extract knowledge from massive electronic medical record (EMR) data to assist clinical research, and utilizing deep learning to train artificial intelligence models from vast amounts of medical imaging data to aid physicians in clinical diagnosis.
2. Meet the needs of hospital management development.Empower AI applications to provide deeper insights and more agile responses for hospital operational management; support real-time stream computing, enabling the application of big data analytics technologies with real-time feedback of analytical results to clinical operations; and leverage edge computing and IoT technologies to realize smart logistics.
3. Meet the configuration requirements for smart hospital applications.Supports the establishment of secure, resilient, and scalable external service platforms; leverages innovative technologies such as blockchain to address challenges in data sharing, circulation, aggregation, and security.
4. Meet the needs of cross-departmental business collaboration.Support cloud-network convergence technology to enable seamless integration of in-hospital systems, external systems, and cloud-based systems, while ensuring the security of data exchange between internal and external networks, thereby achieving business continuity for hospitals.
5. Meet data governance requirements.The available global data services must encompass full-lifecycle data governance, including data standard management, master data management, data acquisition, data aggregation, advanced data processing, data asset management, data quality management, and data security management.
6. Meet data service requirements.To support the need for internal system interoperability and data integration/sharing within hospitals; to meet the need for improving the quality of massive data resources; to address the need for data-driven scientific decision-making in hospitals; and to respond to the need for managing data security risks.
Certainly, in addition to building next-generation hospital data centers, hospitals must also complete the construction of infrastructure such as imaging data centers and clinical research databases, further improving data governance and organization to better realize their value in subsequent applications.
Although the development of NLP has strongly promoted the construction of smart hospitals, in specific scenarios such as automated medical record writing, intelligent consultation, and intelligent follow-up, this technology still relies on the logic of keyword mapping to databases and has not yet achieved true intelligence.
The emergence of Large Language Models (LLMs) can, to a certain extent, address the issue of insufficient intelligence levels in existing technologies. When analyzing text-based information, LLMs are not only capable of identifying key items required for tasks from vast amounts of given data but also making presuppositions about unknown information and performing reasoning based on context.
Compared with general-purpose large models featuring hundreds of billions of parameters, medical text-based large language models can be constrained to fewer than 1 million parameters, while multimodal models incorporating both text and imaging data can be kept within 5 million parameters. Consequently, even non-leading internet companies can participate in the development of medical LLMs.
 Medical Large Model Enterprise Industry Map (as of September 20, 2023; Data source: VCBeat)
Medical Large Model Enterprise Industry Map (as of September 20, 2023; Data source: VCBeat)
However, from concept to implementation, medical LLMs at the current stage still need to address two issues.
First is deployment. When enterprises deploy large language models (LLMs) in hospitals, the hospitals need to purchase corresponding GPUs to support model operation. Generally, the GPU cost for serving an application in a single department is around several thousand yuan. However, to meet the needs of the entire hospital, the institution may need to allocate millions of yuan for chip procurement. Therefore, to promote the large-scale implementation of LLM applications, it is necessary on one hand to encourage hospitals to proactively deploy LLM runtime environments, and on the other hand, for enterprises to optimize their models to minimize the infrastructure costs borne by hospitals.
Second is application. Currently, intelligent applications built on large language models (LLMs) have not yet transcended the scope of traditional healthcare IT applications, such as medical record quality control and intelligent consultation. Enterprises need to develop “killer” applications centered around hospital needs to stimulate demand for LLM procurement by hospitals, thereby achieving large-scale deployment of LLMs.
Building large language models (LLMs) is costly and requires vast amounts of medical data, so competition remains concentrated among leading healthcare IT firms and internet companies. Since LLM applications must be integrated into healthcare information systems, non-healthcare IT companies can only access the IT environment through external plug-in methods, which limits operational smoothness. In contrast, healthcare IT companies that own healthcare information management systems hold a competitive advantage. Meanwhile, LLMs impose stringent requirements on hospital infrastructure; intelligent architectures capable of supporting AI applications will demonstrate the capabilities and limitations of LLMs more effectively than traditional enterprise architecture (EA).
Furthermore, nearly all existing vertical large language models (LLMs) in healthcare have been developed using non-clinical medical data. As industry competition intensifies, clinical data is poised to return to the forefront of LLM development, thereby further advancing data governance initiatives.
So, how far is medical data from becoming an “asset” rather than just a “factor of production”?
Similar to production factors such as labor and capital, the value of medical data is realized through its application and circulation. However, whether in the process of application and transfer across data platforms or in future changes of ownership via data exchanges, any flow of data inevitably gives rise to issues such as data breaches and misuse. Therefore, only by ensuring the security of medical data flows can we safeguard the healthy development of the big medical data industry.
Furthermore, a stable data trading market is the foundation for ensuring the efficiency of data circulation. Therefore, it is essential to establish an effective matchmaking mechanism between data demanders and data owners, foster stable upstream-downstream relationships, and provide legal protections for data owners, including patent rights, copyrights, and other safeguards under national intellectual property laws.
Although numerous big data exchanges have commenced operations in China, the overall landscape of the data factor circulation market remains relatively homogeneous. The volume of data listed on these exchanges is limited, failing to meet market demands in both quantity and quality. In contrast, while over-the-counter (OTC) data trading markets are highly active, they lack effective regulatory oversight and security safeguards.
In the healthcare sector, many data exchanges have established trading categories for “medical and health” data. However, the vast majority of these exchanges currently lack any supply products under this category. Only the Guizhou Big Data Exchange has listed one product, namely “Speech Data for Early Screening of Childhood Articulation Disorders,” priced at RMB 250,000, with just two transactions recorded.
To achieve the transition from “factors of production” to “assets,” the data trading market must establish a system comprising government-led, market-oriented data factor trading institutions and service platforms. Data suppliers conduct effective data aggregation and processing; external entities build platforms, assist in standard-setting, and provide security safeguards; trading centers offer supply-demand matching services to realize data value appreciation and monetization; and regulatory bodies ensure market supervision and quality control, fostering a favorable circulation environment.
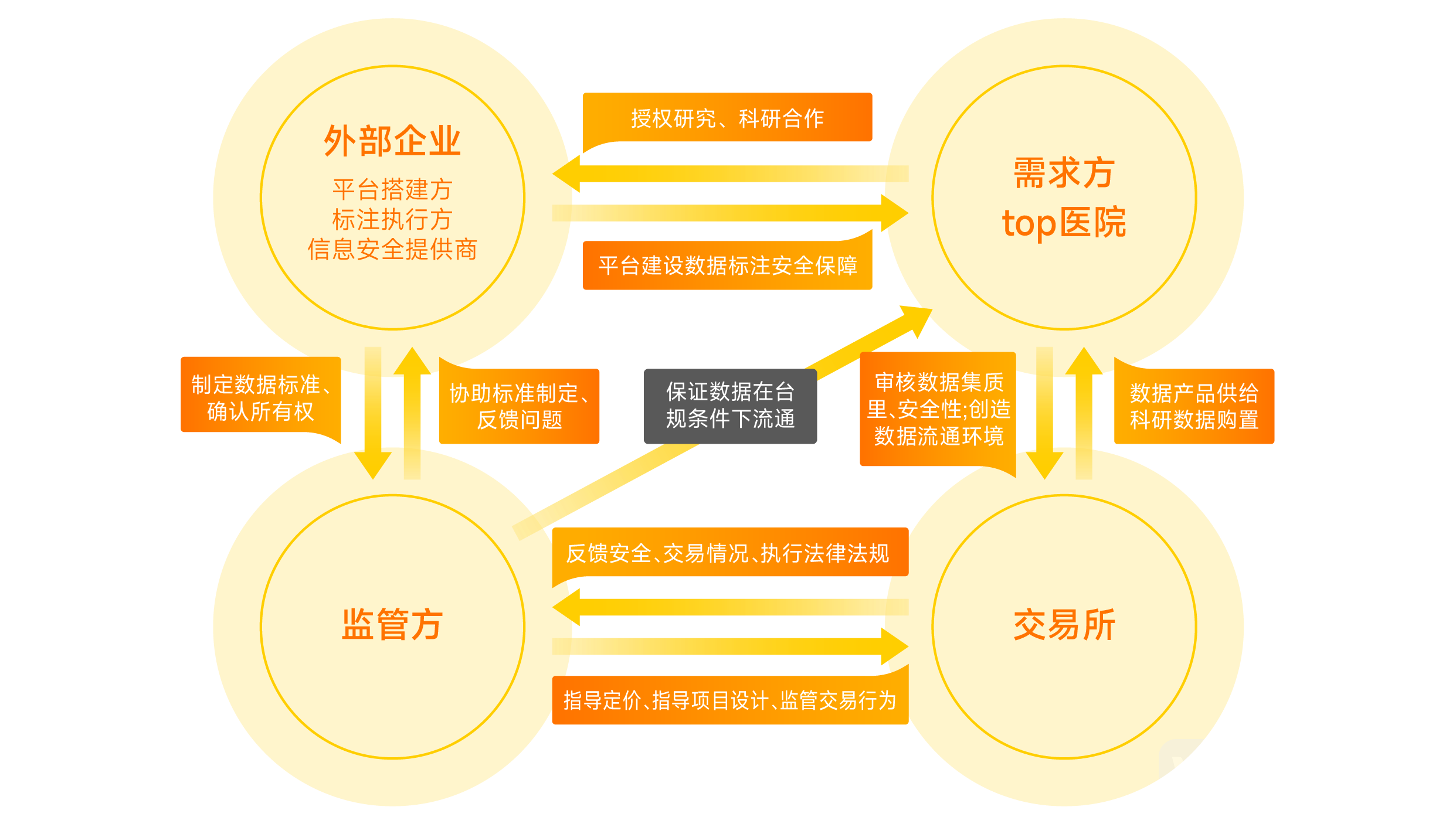 The Closed-Loop Data Element Platform in an Ideal State (Source: VCBeat)
The Closed-Loop Data Element Platform in an Ideal State (Source: VCBeat)
Overall, China’s data factor circulation market remains in its early stages of development. Amid the sustained surge in demand for data trading, it is essential to adopt a dual approach: on one hand, the state should lead efforts to improve institutional frameworks related to data factor services and guide the cultivation of the data factor trading market; on the other hand, more suppliers must be fostered to enrich the data supply system, while publicity for data exchanges should be intensified. The ultimate goal is to achieve effective matching of data supply and demand underpinned by a robust market mechanism, thereby enabling the efficient and secure circulation of various types of data factors.
The above is an excerpt from the main content of the report,Scan the QR code to download the full report for free.。
