PacBio's Next Leap: Driving Clinical and Multi-Omics Innovation Beyond 25,000-Base HiFi Reads with 99.9% Accuracy

PacBio
Provider of High-Quality, High-Precision Sequencing Platforms
Deciphering the Essence of Life's Operations Has Always Been the Goal of Scientists Worldwide.
The complexity of biological research requires researchers to consider not only individual genes or genetic patterns but also the organism’s entire genetic information (genome) and its broader functional implications, thereby placing increasingly stringent demands on gene sequencing technologies.
Although first-generation sequencing technology, which emerged in the 1970s, offers high accuracy and has been widely used in experiments such as vector construction and gene knockout, it suffers from disadvantages in throughput, cost, read length, and speed. The subsequently developed next-generation sequencing (NGS) technology enables the simultaneous sequencing of millions to billions of DNA molecules, achieving large-scale, high-throughput sequencing; however, it still shows no significant improvement in read length and speed.
Driven by the interdisciplinary convergence of computer science, biology, and chemistry, third-generation sequencing technology (SMRT) has emerged. This technology achieves read lengths in the tens of kilobases (kb), thereby addressing the short-read limitations inherent in first- and second-generation sequencing technologies.
Long-read sequencing, with its ultra-long read lengths, enables the sequencing of regions that are intractable to short-read sequencing technologies—such as telomeres, highly repetitive regions, and complex structural variants—thereby illuminating previously dark areas of the genome. Long-read sequencing can detect DNA (or RNA) fragments ranging from 1,000 to 20,000 bases or more in length. These fragments are typically derived from “native” molecules, which are extracted directly from biological samples for analysis. In contrast, most short-read sequencing technologies are limited to detecting fragments only 50–300 bases in length.
In 2022,Long-read sequencingNamed “Method of the Year” by *Nature Methods*, it is increasingly being applied in various important research projects, particularly demonstrating great potential in handling complex and challenging regions of the genome.
In March 2022, Science published the first complete sequence of the human genome. In this study, the T2T Consortium completed sequencing of the remaining 8% of the human genome using long-read sequencing technologies, including PacBio HiFi and Oxford Nanopore Technologies (ONT). This region had remained unresolved by short-read sequencing methods for the previous two decades.
In May 2023, the first draft of the human pangenome was published in Nature. Long-read sequencing data from PacBio HiFi and Oxford Nanopore Technologies (ONT) enabled the new genomic reference map to reveal structural variations with greater clarity.
Currently, long-read sequencing is primarily represented by PacBio’s HiFi sequencing and Oxford Nanopore Technologies (ONT).
HiFi Sequencing Offers Significant Advantages Based on Read Length and Accuracy Requirements
Third-generation sequencing was initiallyEarly 2000sProposed by PacBio。
At the time, Dr. Stephen Turner and Dr. Jonas Korlach were conducting research at Cornell University. Recognizing the limitations of existing gene sequencing technologies, they resolved to develop a novel sequencing approach. This vision led them to co-found Pacific Biosciences in 2004.
In 2005, PacBio developed SMRT sequencing technology based on zero-mode waveguide (ZMW) arrays, enabling real-time sequencing of DNA molecules tens of thousands of bases in length.Compared with traditional short-read sequencing technologies, SMRT technology can read the complete sequence of a single DNA molecule in one go, thereby providing longer read lengths and higher accuracy.The key to this technology lies in its unique nanofluidic chip, which enables real-time observation of DNA polymerase activity at the single-molecule level, thereby achieving direct reading of DNA sequences.
In 2010, PacBio completed its initial public offering and was successfully listed on the NASDAQ under the ticker symbol PACB. This marked the company’s formal entry into the public sphere and secured broader financial support.
After years of research and development and technological innovation, PacBio launched its first commercial sequencing system—the PacBio RS—in 2011.The launch of this system marks the official market entry of long-read sequencing technology, opening up new possibilities for genomics research and applications.The launch of the PacBio RS not only consolidated the company’s leadership in the field of gene sequencing but also attracted significant attention from investors.
With continuous technological advancements, PacBio has continued to expand its product portfolio. In 2016, PacBio launched the Sequel system, a significant upgrade over the previous-generation RS system, offering substantial improvements in read length, throughput, and efficiency.
Subsequently, PacBio launched the Sequel II and Sequel IIe high-throughput sequencers in 2019 and 2020, respectively, further enhancing sequencing accuracy, and established collaborations with multiple projects and companies, such as the Solve-RD project and the All of Us Research Program.
HiFi sequencing is the core chemistry technology running on all PacBio long-read sequencing instruments,PacBio scientists based onDeveloped to meet the dual demands for length and accuracy in genomic analysis,Provides unprecedented depth and precision for genomics research。
Building on the success of this technology, PacBio secured a $900 million investment from SoftBank in 2021, injecting fresh capital into the company’s operational expansion and new product development in the coming years. As of 2023, PacBio’s financial reports revealed significant revenue growth, with annual revenue increasing by 56% year-over-year, indicating sustained rises in market recognition and product demand.
Sequencing read lengths of up to 25,000 bases with an accuracy of 99.9%
HiFi sequencing is a single-molecule, long-read sequencing technology capable of generating long and accurate reads.。
Currently, PacBio’s HiFi sequencing can achieve read lengths of up to 25,000 bases, whereas short-read sequencing technologies typically yield reads within 500 bases. In addition to delivering ultra-long reads, HiFi sequencing attains an accuracy rate of 99.9%. This combination of long read length and high accuracy enables HiFi sequencing to excel in some of the most technically challenging areas of genomics.
Similar to other high-throughput sequencing technologies,HiFi sequencing is also a form of sequencing by synthesis; however, it does not require PCR amplification. Instead, it directly sequences the DNA fragments from the extracted native molecules., hence the term “high-fidelity sequencing” (HiFi is an abbreviation for High-Fidelity).
As for why HiFi sequencing requires no PCR amplification while achieving both long read lengths and high accuracy, the explanation lies in its underlying technical principles.
First, HiFi sequencing libraries are unique in that hairpin adapters are ligated to both ends of linear DNA fragments to form a circular template. Second, primers and polymerase are added to this template to generate a DNA complex. The advantage of this library preparation method is that, because the DNA fragment forms a complete circle, it can undergo continuous rolling-circle replication and sequencing, thereby improving sequencing accuracy.
SMRT Cell chips are the core of HiFi sequencing, facilitating the chemical reactions required for HiFi sequencing on PacBio long-read sequencing instruments. The internal surface of an SMRT Cell chip contains millions of nanoscale wells known as ZMWs (Zero-Mode Waveguides). Following library preparation, the processed DNA molecules are randomly loaded into these ZMWs.
The glass substrate is pre-coated with streptavidin, and the polymerase on the DNA molecule is labeled with biotin. Leveraging the high affinity between biotin and streptavidin, the DNA molecule can be immobilized on the glass substrate at the bottom of the ZMW well via the polymerase attached to it.
The sequencing polymerization reactions occur within these nanowells, generating corresponding DNA sequence data; however, not all nanowells yield valid data.
This is because DNA molecules are randomly introduced into the nanopores, but only those pores capturing a single DNA molecule can yield valid data. Empty pores generate no signal, while pores containing multiple DNA molecules produce noisy signals that will be filtered out during subsequent data analysis.
Thus, it can be seen thatHiFi sequencing throughput is limited by ZMWs.The higher the density of zero-mode waveguides (ZMWs) on an SMRT Cell chip, the greater the number of molecules that can be sequenced simultaneously, resulting in higher sequencing throughput.
SMRT Cell Chip Upgrade: Sequencing Throughput Sees Leapfrog Improvement
In recent years,PacBio has upgraded its SMRT Cell chips, achieving a leap in sequencing throughput.Currently, the most powerful chip in the PacBio series is the Revio SMRT Cell, which integrates 25 million ZMWs. According to official data, a single Revio SMRT Cell can generate up to 90 GB of HiFi sequencing data within 24 hours under specific conditions.
Once DNA molecules are loaded into the SMRT Cell chip, fluorescently labeled dNTP substrates are added. These dNTP substrates are tagged with four different colored fluorophores on their phosphate groups, each representing one of the four nucleobases.
During the reaction, when a dNTP matching the base to be incorporated passes by, it is held by the enzyme for an extended period. Excitation light enters from the bottom of the well and strikes the captured dNTP, causing it to emit fluorescence. The instrument then identifies the specific base based on the color of the detected fluorescence.
Due to the small diameter of the sequencing wells, the penetration depth of the excitation light gradually attenuates, allowing it to travel only a short distance within the well. Consequently, fluorescence is emitted only when dNTPs are sufficiently close to the bottom and illuminated by the excitation light. Meanwhile, noise from other free-floating dNTPs is suppressed to a very low level due to their brief residence time.
Upon completion of a polymerization reaction, the pyrophosphate group, along with its attached fluorophore, is cleaved from the original dNTP and washed away by the solution, thereby initiating the next polymerization cycle.
HiFi sequencing does not achieve extremely high accuracy in single-base calling; however, its errors are random and unbiased. Therefore, data accuracy can be improved by increasing the number of repetitive detections of the same sequence.
Furthermore, as previously mentioned, the DNA molecular complexes in HiFi sequencing libraries adopt a circular configuration. During sequencing, DNA polymerase traverses the circular structure of the sample DNA molecule multiple times, akin to a race car repeatedly circling a racetrack. Since the polymerase generates multiple copies of each DNA molecule within the ZMW wells, the PacBio long-read sequencing system can determine the accurate sequence of the sample DNA by cross-referencing these subreads, thereby enhancing accuracy. This optimization strategy is known as Circular Consensus Sequencing (CCS).
Combining Long Reads with Accuracy, Yet Facing Cost Challenges
In summary, the advantages of HiFi sequencing can be summarized in five aspects. First, HiFi is based on single-molecule sequencing, where the sequencing template consists of individual DNA strands, thereby enabling the differentiation between similar sequences.
Second, long read lengths: HiFi sequencing can provide read lengths of 15,000–20,000 base pairs or longer, enabling more accurate and efficient genome assembly. Furthermore, the ultra-long read lengths allow direct de novo sequencing of full-length mRNA molecules, yielding complete transcript sequences.
Meanwhile, HiFi sequencing offers high accuracy; through circular consensus sequencing, it generates reads with >99.9% accuracy.
Furthermore, HiFi sequencing eliminates the need for PCR amplification. By removing biases introduced by PCR, HiFi sequencing enables the analysis of genomic regions that are typically difficult to access with other technologies, such as AT- and GC-rich regions, highly repetitive regions, long homopolymers, and palindromic sequences.
Finally, HiFi sequencing can directly detect the modification status of bases. During sequencing, when methylated bases are encountered, the polymerization reaction rate significantly slows down, and spectral characteristics also change, thereby enabling direct detection of the methylation status of the bases.
The technical characteristics of HiFi sequencing confer unique advantages in complex genome research, offering novel solutions to problems that are intractable with other technologies.
Currently, the application scenarios in which PacBio HiFi sequencing offers significant advantages are as follows:Haplotype phasing, genome assembly, variant detection, and epigenetic research。
Specifically, in the realm of haplotyping, the long read lengths and high accuracy of HiFi sequencing enable researchers to distinguish differences between copies or haplotypes of each chromosome (e.g., maternally or paternally inherited), thereby generating fully phased diploid genome assemblies (as opposed to collapsed genome assemblies that ignore differences between homologous chromosomes).
In the field of genome assembly, HiFi sequencing enables researchers to perform high-quality genome assembly efficiently and accurately, offering significant advantages over other sequencing technologies. It yields genomes with higher quality and continuity in the assembly of highly repetitive genomes, large and complex genomes, allopolyploid genomes, and even autopolyploid genomes.
In the field of variant detection, HiFi sequencing can detect all types of variants, ranging from single nucleotide variants to structural variants, including some regions in the genome that are particularly challenging to detect, such as tandem repeats and highly repetitive sequence regions.
In the field of epigenetics research, HiFi sequencing enables the direct acquisition of base modification information (such as methylation) alongside traditional base-calling data during sequencing, offering researchers new possibilities for investigating heritable changes in gene expression in humans and other organisms.
Furthermore, since methylation data are generated concurrently with other HiFi applications, researchers can accurately localize and investigate epigenetic effects on genomes that have undergone haplotype phasing and variant calling.
Of course,This sequencing technology also has certain limitations.For instance, when the initial error rate is high, repeated testing is required to improve accuracy;High price, high sequencing cost; furthermore, sequencing read length and accuracy are influenced by DNA polymerase activity, which in turn is affected by the detection laser, among other factors.
$800 Million Acquisition: Long-Read Platforms Coexist with Short-Read Market
In February 2024, PacBio announced its 2023 financial report.In 2023, PacBio’s revenue was $200.6 million, representing a 56% increase from $128.3 million in 2022.。
In 2023, the company’s product revenue surged by 69% from $108.7 million in the previous year to $183.9 million, while service and other revenue declined by 15% from $19.6 million to $16.6 million. Instrument revenue reached $120.5 million, more than doubling from $48.7 million in 2022; consumables revenue amounted to $63.4 million, representing a 6% increase from $60.0 million in the prior year.
Of this, product revenue in the fourth quarter of 2023 totaled $54.0 million, a 137% increase from $22.8 million in the fourth quarter of 2022; service and other revenue decreased by 4% from $4.6 million to $4.4 million; instrument revenue totaled $35.1 million, more than five times the $6.1 million recorded in the second quarter of 2022, primarily driven by continued adoption of the Revio platform; consumables revenue reached $18.9 million, a 13% increase from $16.7 million, setting a company record.
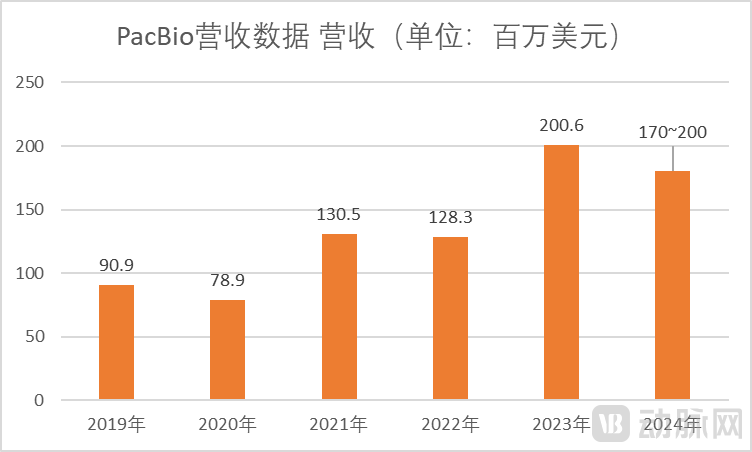
PacBio’s revenue grew by 56% in 2023, with a cumulative increase of 154% over the previous three years—an impressive performance that has led the industry to maintain high growth expectations for the company over the next three years. Previously, PacBio had projected its full-year 2024 revenue to range between $230 million and $250 million, representing a 15% to 25% increase from its 2023 revenue of slightly over $200 million.
However, according to the company’s latest forecast, revenue for 2024 is expected to range between $170 million and $200 million. Following the release of the company’s financial report, its share price fell by 13.94% on the same day.Despite growth in the reagents and consumables business, the gross profit margin halved to 16%, leaving the issue of revenue growth without corresponding profit growth unresolved. Investors remain skeptical about PacBio’s success.
This is also based on PacBio’s new strategic choices. Previously, PacBio performed well in the field of long-read sequencing and had clear development goals: to reduce the cost of long reads by continuously improving sequencing throughput. With the launch of Revio, PacBio HiFi long reads have begun to play a significant role in large-scale population studies.
Beyond the long-read sequencing market, PacBio has also entered the short-read market. In July 2021, PacBio acquired Omniome for $800 million.。However, as the short-read market has become highly saturated, accuracy exceeding Q50 does not appear to genuinely drive commercial success.PacBio has not yet disclosed the actual sales figures for its Onso short-read sequencing platform, and for a considerable period, its focus appears to have been on building production capacity.
Simultaneously supporting the continuous development and commercialization of multiple platforms across two technological pathways may slow its progress.To date, all of the Company’s revenue has been derived from its long-read sequencing platform.
PacBio stated that it would “continue to develop our desktop long-read and high-throughput short-read platforms,” seemingly no longer mentioning the ultra-high-throughput long-read platform previously outlined in its roadmap. Many are questioning why the company is doubling down on high-throughput short-read sequencing rather than pursuing ultra-high-throughput long-read sequencing. Although the short-read market is significantly larger, will high-throughput short-read technologies remain competitive when they come to market?
But this strategic choice,In fact, PacBio faces two major challenges in long-read sequencing: first, the high costs, particularly the upfront instrument costs; and second, the limited application and market potential.
In addition, when setting its 2024 targets, the company also considered several macroeconomic factors affecting equipment procurement, including China’s financing environment, which has also impacted the company’s ability to further expand its Revio installed base in China.
Sequencing Costs Drop Below $1/Gb as China Builds Ultra-Low-Cost Sequencing Platform
As is well known, when technology and performance reach a certain level, “cost” always remains the decisive factor for widespread adoption. According to statistics by Albert Vilella, the consumer segment characterized by an instrument deployment cost of under $100,000 and a per-unit data output cost of under $1 represents the current “no-man’s land” in the sequencing field.
Currently, both second- and third-generation sequencing technologies are based on optical signals, requiring expensive optical monitoring systems and relying on DNA polymerase to read base sequences, which significantly increases sequencing costs. Therefore, developing “low-cost, long-read sequencing” products while ensuring high throughput and high accuracy is an urgent development direction for the industry.
Gene sequencing technology is one of the few innovative technologies in China that can currently compete on the global stage. In June 2023, the Chinese Pan-genome Consortium (CPC) leveraged PacBio HiFi sequencing to assemble and construct the first high-precision pan-genome reference map for the Chinese population.
Chinese Companies Focus on Cost Challenges, Developing Sequencers with a Cost Advantage. For instance, leveraging the inherent advantages of its advanced multi-disciplinary technical approach, Anxuyuan has established a comprehensive product portfolio that includes nanopore sequencers and supporting solutions, microarray chip analyzers and assay kits, and POCT testing products. The company has set up R&D centers in multiple locations across China and the United States, actively recruits talent from diverse professional fields worldwide, and continuously integrates global industrial resources to advance its R&D initiatives.
High instrument deployment costs hinder the expansion of equipment at primary healthcare facilities, making large-scale adoption difficult. Consequently, usage is restricted to "centralized testing," which inadvertently incurs hidden costs such as sample transportation and patients seeking medical care in different locations. Furthermore, high per-unit data production costs lead to elevated consumer prices in end-use scenarios, limiting affordability to a smaller population. This also results in slower and limited data accumulation, which impedes technological upgrades and product iteration. Meanwhile, for sequencing companies, high startup costs per run necessitate batch pooling to amortize expenses. The uncertainty associated with sample pooling timelines keeps these companies in a passive position regarding efforts to reduce testing turnaround times.
Anxuyuan has launched the AXP100-RS gene sequencer, integrating core advantages of low cost, long read lengths, high accuracy, compact size, and rapid detection, which holds significant industry value for the healthy development of China’s gene sequencing instrument sector.
It is understood that this sequencing system is powered by a fourth-generation nanopore gene sequencing platform, featuring a comprehensive product suite covering the entire sequencing workflow. This includes sample processing and nucleic acid extraction; library preparation reagents (Xprep Kit 100); long-read sequencing instruments (AXP100-RS), sequencing chips (XPU100), and sequencing reagents (Xseq Kit 100); as well as the Xconsole 100 operational and data analysis system. Anxu Yuan provides complete hardware and software support for its leading gene sequencing technology, ensuring stable sequencing performance and achieving low-cost sequencing.
The XPU100 sequencing chip, a core component of its sequencer, inherits the advantages of Bio-CMOS chips, including high sensitivity in AC impedance detection, rapid sequencing speed, and flexible throughput. Meanwhile, it enhances anti-interference capability and integrated throughput, ensuring a maximum data output of up to 100 Gb while maintaining a sequencing cost significantly below $1 per Gb.
In other words, Anxu Yuan has leveraged the world’s most advanced semiconductor technology to create the lowest-cost sequencing platform, making “on-demand sequencing” a reality for genetic testing.
Long-read sequencing has reached a critical juncture. If cost barriers can be overcome and supporting technologies and related fields can keep pace, numerous new application scenarios may emerge, accelerating the market adoption of this technological domain.