Evo 2 and OxTium’s GeneLLM™ Usher in the Era of Large Models in Biological Science

OXTIUM
AI+Life Science Technology Developer
On February 19, 2025, the foundational biology model Evo 2 was officially released, sparking a strong reaction in the biological sciences community and becomingThe Largest-Scale Biological AI Model Currently. Trained on over 128,000 genomic datasets and 9.3 trillion nucleotide sequences, this model was collaboratively developed on NVIDIA supercomputing clusters under the leadership of the non-profit Arc Institute and Stanford University, in partnership with UC Berkeley, UCSF, Liquid AI, and Goodfire, jointly driving a paradigm shift in the foundational research of biological sciences.
 Evo 2 Concept Diagram, Image Source: GitHub/Evo 2
Evo 2 Concept Diagram, Image Source: GitHub/Evo 2
The open-sourcing and application of Evo 2 mark the entry of generative biology into a new, scientifically revolutionary phase, achieving “Reading, Writing, and Thinking in the Language of Nucleotides” goal, enabling researchers to achieve cutting-edge analytical capabilities comparable to DeepSeek through “zero-shot prediction” alone, without the need for task-specific fine-tuning. Meanwhile, as China’s first enterprise dedicated to foundational large models for AI in biological sciences, OXTIUM stands at the eye of this scientific revolution, holding the innovative key to unlocking a trillion-dollar market.
Although both Evo 2 and GeneLLM™ are large biological science models, they differ significantly in essence.Evo 2 is trained on genome data categorized by species, whereas GeneLLM™ focuses on the direct training and analysis of individual raw data (such as sequencing data, mass spectrometry data, etc.).From the perspective of data characteristics, there is only one human reference genome, and the genome of each species is relatively fixed, whereas sequencing data exhibits high diversity and individual specificity. For instance, sequencing data from each individual can generate a vast amount of information on individual differences, enabling GeneLLM™ to deeply analyze variations between individuals, such as disease susceptibility and phenotypic traits, and to accurately identify “disease-related biomarkers.” We are also able to mine trait-specific features within the same species, such as the identification of lodging-resistance genes in rice. This distinction determines the independence of GeneLLM™ and Evo 2 in their respective application scenarios.
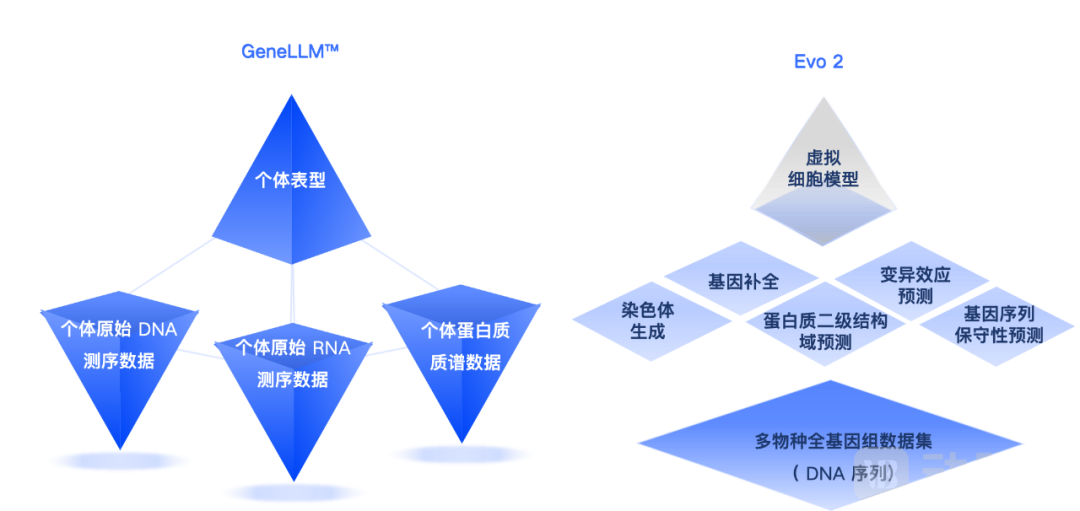 GeneLLM™ vs. Evo 2 Comparison Chart
GeneLLM™ vs. Evo 2 Comparison Chart
To date, no models similar to GeneLLM™ that are trained directly on raw data have emerged in the market, as the sheer scale and complexity of raw data present significantly greater training challenges. This technical approach grants OXTIUM unique advantages over Evo 2 in foundational biomedical research applications, such as disease risk assessment and the analysis of plant and animal traits.
The central dogma and the theory of evolution constitute a unified biological framework spanning from genes to populations, elucidating the functional effects of natural selection through the fundamental information transmitted by DNA. The Evo series of models was developed within this theoretical framework,Aims to integrate biodiversity through a unified multiscale representation, establishing a robust foundation for modeling and design from the molecular to the systemic level.
Evo 2, deployed on the NVIDIA BioNeMo platform, adopts a StripedHyena hybrid architecture, achieving nearly a 3-fold speedup over traditional Transformer architectures when processing million-base-pair sequences. Meanwhile, Evo 2 performs adaptive learning based on DNA sequences, enabling accurate prediction of the functional effects of DNA, RNA, and proteins, and covering the molecular levels of the central dogma (DNA → RNA → protein).
This model can efficiently evaluate variant effects using zero-shot prediction without task-specific fine-tuning.For example, accurately inferring the clinical significance of genetic variants inBRCA1Assessing pathogenicity from non-coding regions in light of genetic influences. Furthermore, Evo 2 can autonomously identify exon–intron boundaries, transcription factor binding sites, protein structures, and prophage genomic regions, and possesses the capability to generate mitochondrial genomes, minimal bacterial genomes, and complete yeast chromosomes that adhere to biological logic. Its generated outputs demonstrate superior naturalness and coherence compared to previous methods.
The Evo 2 model coversVarious Biological Domains, Including Plants, Animals, and Bacteriaperformed exceptionally well in pre-training, with the capability toHealthcare, Agricultural Biotechnology, and Materials Sciencebroad application prospects in multiple scientific research fields.
In the fields of healthcare and drug development, Evo 2 can assist researchers in identifying gene variants associated with specific diseases, thereby supporting drug design for novel targets. For example, in breast cancer-relatedBRCA1 In genetic variant testing, the model achieved an AUROC of over 0.90 under zero-shot prediction and reached 0.95 in supervised mode, demonstrating excellent performance in distinguishing between benign and pathogenic mutations. Such highly efficient and precise capabilities are driving disruptive innovation in biomedical research.
Evo 2’s capabilities extend far beyond these. Its most significant strength lies in its exceptional flexibility and versatility; rather than being confined to a specific task, it can perform extensive predictions and generate novel content across scales ranging from individual molecules to entire genomes, and even more complex biological systems.
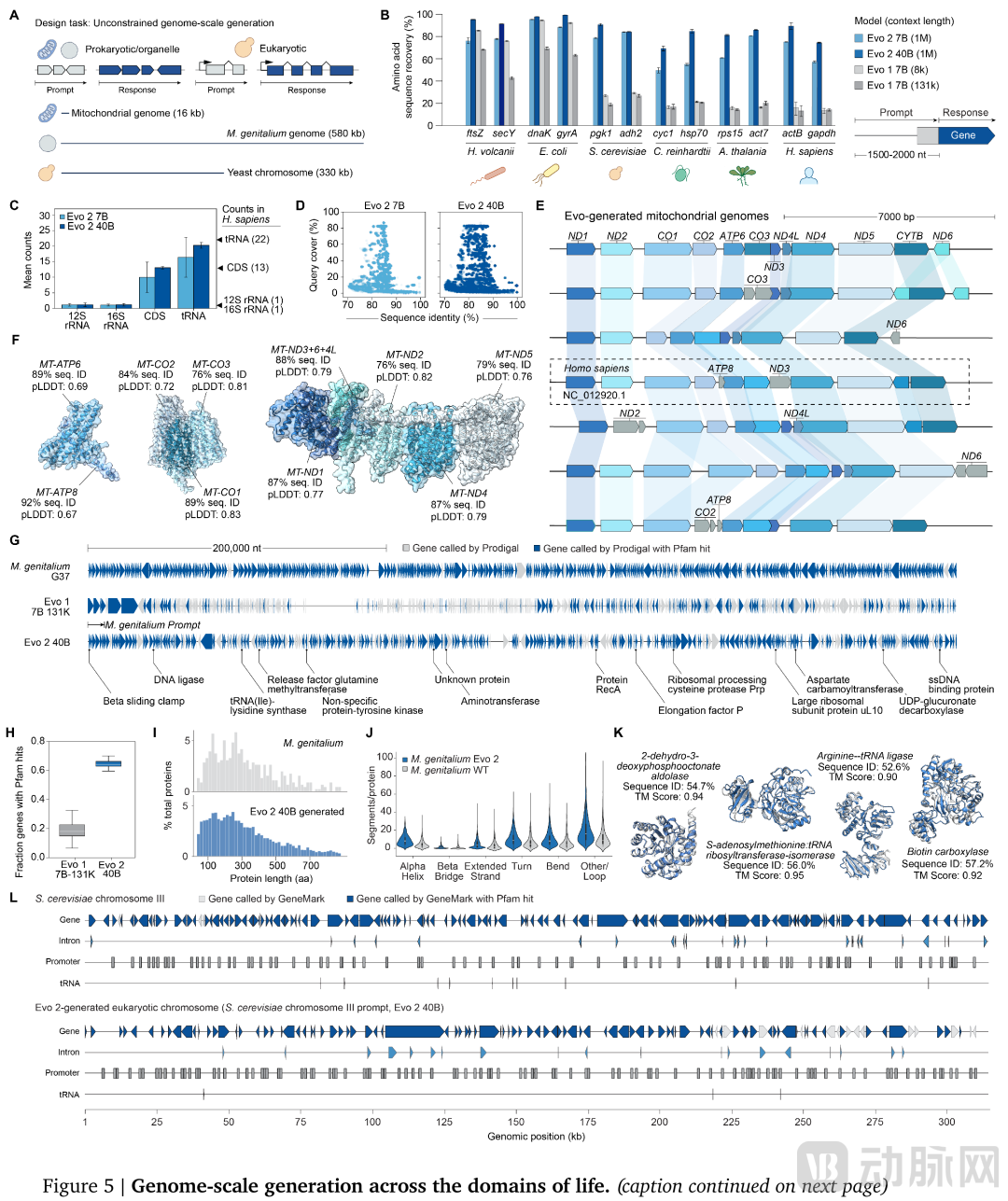 Scale of genome generation across domains of life. Image source: Evo 2 preprint
Scale of genome generation across domains of life. Image source: Evo 2 preprint
Its training dataset, OpenGenome 2, is built upon 128,000 genomes spanning 4 billion years of evolutionary history. Functioning as a digital museum of biology, this super-corpus contains 9.3 trillion nucleotides, enabling the model to capture a wide array of evolutionary codes, ranging from archaeal methane metabolism to the human immune system.
The team’s next step is to integrate this unified representation with multimodal data, such as epigenomics and transcriptomics, to construct virtual cell models capable of simulating complex cellular phenotypes in both health and disease states, thereby providing more comprehensive analytical tools for biological research.
It is undeniable that biological systems are composed of carbon atoms, amino acids, nucleotides, proteins, macromolecules, cells, tissues, and organs. Each hierarchical level contains “dark matter” that has not yet been fully elucidated, causing traditional bottom-up modeling approaches to deviate from the true complexity of biological systems due to the accumulation of errors across layers. Meanwhile, the emergent properties of biological systems make their overall behavior difficult to explain using models based on a single hierarchical level.
To address this limitation, the founding team of OXTIUM has taken a different approach from the very beginning of the project, pioneering strategic deployment.Artificial Intelligence in Biological SciencesTrack. GeneLLM™ throughDirectly parsing raw sequencing data and outputting end-to-end disease phenotype correlation analysis avoids the problem of error accumulation in hierarchical modeling., providing a novel and practical technical pathway for the field of biological science research.
The core design philosophy of Evo 2 lies in the fact that all biological coding sequences follow a unified structure, beginning with a start codon and ending with a stop codon. Based on this principle, Evo 2 can learn sequence features to generatively predict the next base pair, as well as predict and annotate the structure and function of unknown genes.
While adhering to the same central dogma and evolutionary theory, GeneLLM™ adopts a groundbreaking, higher-order technical approach by feeding raw sequencing data directly into the model. Leveraging deep learning algorithms, GeneLLM™ captures subtle variations in multi-omics data and constructs a direct associative mapping between disease phenotypes and raw data. Centered on high-dimensional data representation and nonlinear relationship modeling, this method significantly enhances the accuracy of disease prediction, offering an efficient and innovative research paradigm for biomedical studies.
By leveraging the ability to extract insights from massive raw datasets and directly apply them to downstream research, GeneLLM™ has pioneered a breakthrough in translating multi-omics diagnostic foundation models into precision medicine and basic scientific research.
Bioford™, a one-stop biological research platform built around GeneLLM™, now integrates hundreds of vertical models in the life sciences. It supports comprehensive intelligent analysis of multimodal data, including genomics, transcriptomics, proteomics, 3D RNA structures, biomedical images, and textual data, to meet the research needs of disciplines such as biomedicine, bioinformatics, molecular biology, immunology, and molecular dynamics. The platform focuses on six core scenarios: basic scientific research, medical diagnostics, biomanufacturing, environmental monitoring, biological breeding, and drug development, providing complete solutions ranging from laboratory data processing and small-sample training to model fine-tuning and inference services.
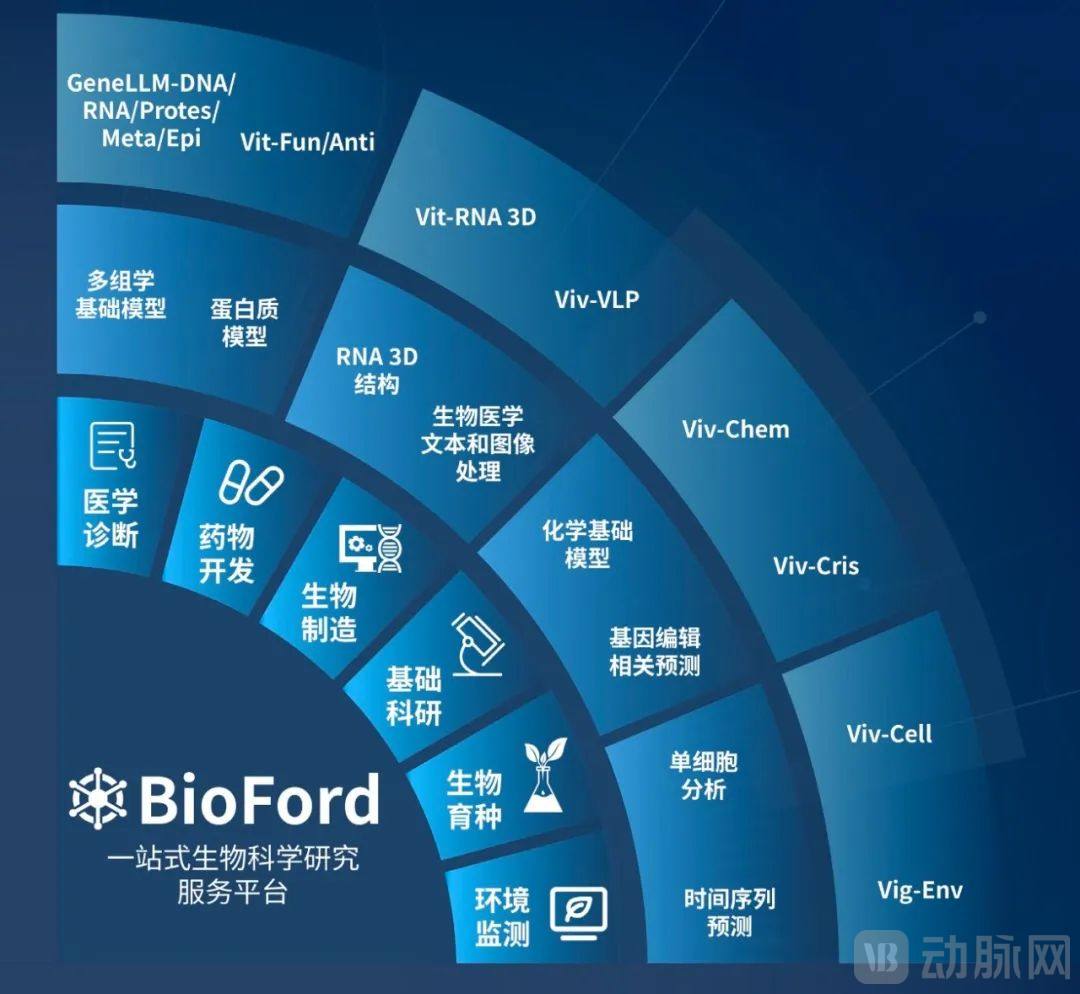
To meet the stringent requirements for data privacy and security in scientific research, Bioford™ supports both cloud-based and on-premises synchronous deployment, featuring a built-in project-level data confidentiality management system. This solution not only ensures data integrity and confidentiality but also establishes an efficient, collaborative, and secure research ecosystem, providing robust support for hospital clinical practices and academic research in driving frontier breakthroughs and clinical translation.
Biomedical Research Is Entering a New Era.The technological breakthroughs of GeneLLM™ have not only disrupted traditional multi-omics data analysis models, but more importantly, have ushered in a novel research paradigm directly based on raw data.
By fully leveraging the advantages of artificial intelligence’s “black box,” this approach can capture disease characteristics and biological patterns that are difficult to detect through traditional methods. Buoyed by Evo 2’s extensive breakthroughs and positive market response, OXTIUM is confident in achieving a comprehensive technological breakthrough. As the first company in China to focus on large AI models for bioscience, OXTIUM not only aligns its technology with international standards but also continuously fills market gaps through localized innovation.
Compared with Evo 2, which represents the generative biology revolution,GeneLLM™ in the AI Track for Biological Sciences, providing global researchers with a highly competitive tool that drives bidirectional progress in scientific discovery and industrial applications. Looking ahead, the widespread adoption of GeneLLM™ will help build an AI-driven bioscience ecosystem spanning healthcare, agriculture, environmental protection, and other fields, contributing Chinese wisdom to human health and sustainable development.
About OXTIUM
OXTIUM is dedicated to providing one-stop AI-driven solutions for biological scientific research. Its self-developed multi-omics large language model, GeneLLM™, has completed pre-training on a version with 1.5 billion parameters and 3.5 trillion base pairs of sequence data. Building upon GeneLLM™, OXTIUM has created BioFord™, a one-stop scientific service platform that focuses on six core scenarios: medical diagnostics, drug development, bio-manufacturing, basic research, biological breeding, and environmental monitoring. The BioFord™ platform features nine specialized bioscience model libraries: a multi-omics foundation model, a protein model, an RNA 3D structure prediction model, a biomedical text processing model, a biomedical image processing model, a chemistry foundation model, a CRISPR-related prediction model, a single-cell analysis model, and a time-series prediction model. It provides advanced “AI for BioScience” bioinformatics computing services, cloud platform services, and integrated inference appliances to both academic researchers and industry users. OXTIUM has served leading domestic institutions such as BGI Group, Baidu PaddlePaddle, the Cancer Hospital of the Chinese Academy of Medical Sciences (CAMS), Shanghai Children’s Medical Center affiliated with Shanghai Jiao Tong University School of Medicine, and the Chinese Research Academy of Environmental Sciences. With R&D centers established in Shenzhen and Beijing, OXTIUM’s founding team is led by four alumni of the University of Oxford and comprises top scientists and engineers in the fields of artificial intelligence, bioinformatics, and bioengineering. The team has published more than 60 papers in prestigious journals such as Nature and Nature Communications. Guided by its mission to “explore the mysteries of life through AI technology,” OXTIUM will continue to push the technological boundaries of AI plus bioscience, providing innovative momentum for biological research and industrial applications, thereby supporting national technological innovation and industrial upgrading.