Top 100 Hospitals in China Are Developing Specialized AI Large Models: From Deployment to Vertical Innovation
No innovative technology has ever penetrated the healthcare system as rapidly as large language models, prompting hospitals to proactively, swiftly, and extensively adopt them within just a few months.
As of April 30, 2025, among the top 100 hospitals in China ranked by third-party lists, 98 have publicly announced the completion of large language model deployment.
Among them, 38 hospitals conducted further research and development based on general-purpose models, creating 55 vertical medical models tailored to their specific needs.
From “Buyer” to “R&D Developer,” Physicians Have Become a Vital Part of the “AI Manufacturing” Community。
 Publicly Released Vertical Large Models by Top 100 Hospitals
Publicly Released Vertical Large Models by Top 100 Hospitals
(As of April 30, 2025, hospital rankings are sourced from the “Spring 2022 China Hospital Competitiveness Ranking””)
By the end of 2022, after OpenAI ignited the large model race with GPT-3.5, China’s healthcare sector had already witnessed multiple rounds of the “Hundred Models War.”
However, due to the high deployment and invocation costs in the GPT era, only a few top-tier hospitals in China have completed the localized deployment of large language models. The vast majority of these models are developed by enterprises, with training data consisting primarily of medical text data, failing to access the core of hospitals’ multimodal clinical data.
Consequently, the large number of large language models (LLMs) that emerged during this era suffer from high homogeneity and weak clinical relevance. Few models have been able to deliver incremental value to hospitals, thus failing to create significant impact in the healthcare sector.
The Emergence of DeepSeek-R1: A Pivotal Turning Point in the Development of Large Medical Models
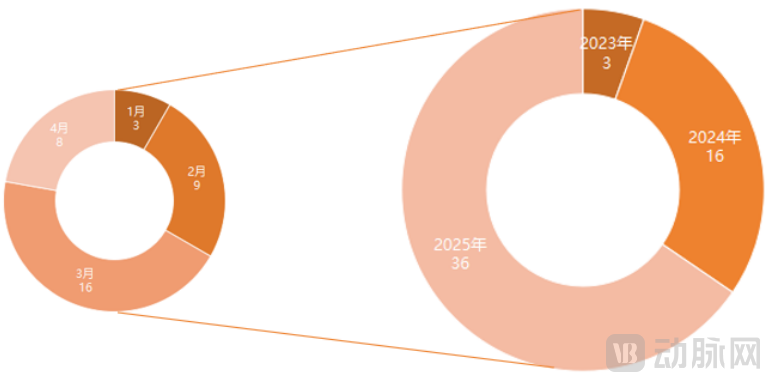 Distribution of Development Timelines for Hospital-Specific Vertical Models (Unit: Count; As of April 30, 2025)
Distribution of Development Timelines for Hospital-Specific Vertical Models (Unit: Count; As of April 30, 2025)
Compared to enterprises, hospitals can access a larger volume of medical data with more diverse modalities, enabling model functionalities to align more closely with actual clinical needs. Consequently, hospital-led large language models that have emerged in the wake of DeepSeek’s popularity (with deployed general-purpose models potentially being alternatives to DeepSeek) are increasingly evolving toward disease-specific and specialty-specific applications, capable of processing multimodal medical data and directly addressing clinical challenges.
For instance, “Xiehe·Taichu,” released by Peking Union Medical College Hospital in February this year, is the first large artificial intelligence model in the field of rare diseases. It can assist physicians in rapidly and accurately identifying and diagnosing rare diseases, thereby addressing the challenge of poor homogeneity in rare disease diagnosis and treatment across China.
Built upon years of accumulated data from China’s Rare Disease Knowledge Base and genetic testing data from the Chinese population, this large language model enables rapid clinical decision support. When a physician inputs symptoms such as “significant delays in development, language, and motor skills since age two, along with an inability to communicate,” the AI provides a judgment within seconds, suggesting the need to rule out rare genetic disorders (such as Rett syndrome or Angelman syndrome) or complex neurodevelopmental disorders. It also offers medical recommendations, including appropriate specialist referrals and supplementary diagnostic tests.
The world’s first large language model for peritoneal dialysis, jointly developed by The First Affiliated Hospital of Sun Yat-sen University and Shenzhou Medical, focuses on the specialized scenario of peritoneal dialysis. Adopting a dual-engine architecture combining DHC and DeepSeek, the model performs deep understanding and integrated analysis of clinical text, imaging, pathology, genomics, and time-series data to capture information relevant to peritoneal dialysis. It provides physicians with functionalities such as diagnostic analysis, treatment regimen recommendations, follow-up advice, and risk prediction, thereby helping to address challenges faced by patients with uremia, including low treatment rates and low rates of social reintegration.
There are many other similar vertical models. According to VCBeat’s statistics based on publicly available data, China currently has 22 vertical models dedicated to specific diseases and specialties, covering conditions such as cardiovascular disease, kidney disease, chest pain, laryngopharyngeal disorders, dermatological conditions, and liver cancer; spanning departments including orthopedics, radiology, pathology, ophthalmology, and anesthesiology; and even featuring large language models specifically trained for equipment such as digestive endoscopes and echocardiography, as well as for processes like surgical risk assessment and infection control.
 Summary of Domestic Vertical Models for Specialized Diseases and Specialties (as of April 30, 2025)
Summary of Domestic Vertical Models for Specialized Diseases and Specialties (as of April 30, 2025)
Meanwhile, the capabilities of vertical large language models (LLMs) continue to expand with the involvement of physicians. Initial LLM applications primarily focused on patient services, leveraging the multi-turn conversational abilities of generative AI to enhance pre-consultation and post-consultation care. These are commonly seen in intelligent pre-consultation triage, smart patient guidance, and automated follow-up systems, representing an upgrade over previous AI technologies.
Today, as hospitals adopt large language models (LLMs) to optimize the patient care experience, they also seek to leverage these models to better serve physicians by enabling functions such as clinical decision support and diagnostic assistance, thereby delivering higher-quality and more efficient medical services. A small number of hospitals are also exploring the potential applications of LLMs in medical education, hospital management, and scientific research, with the aim of transitioning from digital to intelligent hospitals and addressing fundamental challenges such as shortages of medical resources and limited research output.
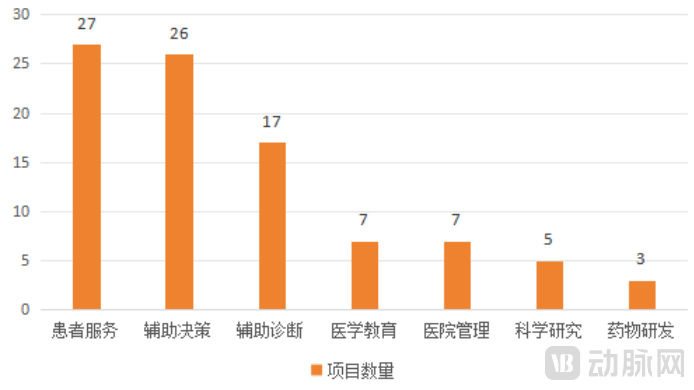
Functional Distribution of Hospital Vertical Models (as of April 30, 2025)
It is worth noting that while all top 100 hospitals have completed the deployment of general-purpose models, the vertical models showcased above were primarily developed by those ranked within the top 50. In other words, the research and development (R&D) of vertical large language models severely tests a hospital’s overall strength. It not only requires ensuring deep integration of medicine and engineering during the R&D process but also demands the capacity to bear the substantial energy and financial costs involved, which are considerable.
The most costly components of large medical models are computing power and data. Similar to the training logic of AI-assisted diagnostic tools in the deep learning era, developing high-quality large medical models requires robust management of medical data, including the effective integration of electronic health records (EHR), imaging data (DICOM), and laboratory reports to ensure data diversity.
Furthermore, data cleaning and annotation are equally critical. To ensure that large language models generate objectively high-quality outputs in subsequent applications, developers must conduct rigorous data governance during the preliminary phase, eliminating duplicate, missing, or erroneous data such as anomalous laboratory values and incorrect electronic medical records.
Taking large imaging models as an example, training a large imaging model for a specific vertical domain theoretically requires at least several thousand classified and annotated images. The image sources need to be diverse, with patient imaging data from different stages and age groups collected as comprehensively as possible to ensure the robustness of the large model.
If too few images are used to train the model, large models are prone to hallucinations in practical applications, fabricating non-existent information to answer questions. In clinical practice, such models cannot be deployed at scale.
In addition to changes in the functional capabilities and value-generation pathways of large medical models, hospitals’ development models are also continuously expanding.
Among the 55 large language models mentioned above, joint development by hospitals and their corporate partners remains the mainstream approach, with more than half of the projects adopting this model.
However, the data indicate that starting in February 2025, the number of projects involving collaborations between hospitals and schools or research institutions began to surge. In particular, the model of independent development by hospitals (including inter-hospital collaborations) has accounted for nearly 25%, becoming the second most significant model after collaborative development with enterprises.
This means: Hospitals are playing an increasingly important role in the capability leap of large medical models.
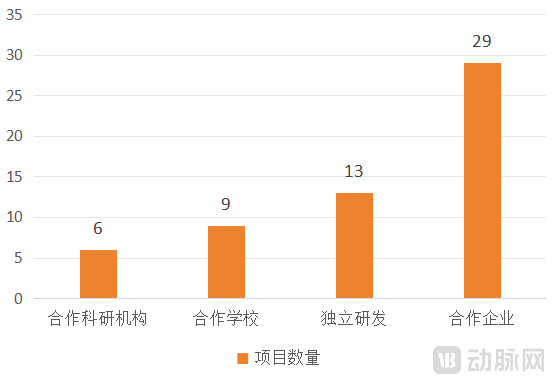
Distribution of Development Models for Medical Vertical Models (as of April 30, 2025)
Nevertheless, due to the scarcity of interdisciplinary professionals with expertise in both engineering and medicine at most hospitals, the collaborative development model between hospitals and enterprises will remain the mainstream approach in the future.
After all, training a model requires completing five steps: data preparation and processing, model selection and configuration, model training, model evaluation and tuning, and model deployment and integration. Compared with independent development, a collaborative approach—where physicians provide domain knowledge and annotated data while AI engineers handle technical implementation—may better align with the current needs of hospitals.
Furthermore, corporate involvement can help hospitals better plan the future iteration path of large language models from a commercial perspective, thereby facilitating the translation of related scientific research. After all, the value of these achievements can be maximized only when they are fully shared.
At present, companies such as Huawei, China Telecom, iFlytek Healthcare, Winning Health, Fuxin Kechuang, and Shenzhou Medical have extensively participated in the development of vertical large language models (LLMs) for healthcare, achieving notable results. As application scenarios for hospital-based LLMs continue to expand, more small and medium-sized enterprises (SMEs) can collaborate with hospitals to jointly develop specialized medical vertical LLMs tailored to specific niche scenarios.
While the involvement of hospitals has driven significant progress in large medical models, at least three major hurdles must be overcome to achieve a generational leap and enable deeper application of these models within the industry.
Limitations of Hospital Large Model Training Datasets
Currently, most large language models (LLMs) developed by hospitals rely on datasets accumulated internally over the long term. While LLMs trained on such data can effectively handle common patient cases, they are prone to hallucinations due to data gaps when confronted with complex or rare lesions. To address this issue, hospitals should strive to compile training sets from multiple geographic regions and various medical institutions when developing their LLMs.
Currently, many hospitals have begun to form disease-specific alliances to jointly develop vertical large language models for healthcare. This approach not only ensures the accuracy and robustness of these large models but also enhances the reusability of medical data, allowing such curated data to fully realize its value.
The Form of Large Language Models Remains Undetermined
To date, industry discussions surrounding large language models (LLMs) have primarily focused on their functionalities, with little attention paid to their form factor. As vertical LLMs emerge from hospitals as commercial products, it is imperative to determine their regulatory classification: whether they constitute standalone software applications or qualify as medical devices subject to regulatory review and approval.
On March 31 this year, the National Medical Products Administration (NMPA) released the “Measures on Optimizing Full-Lifecycle Regulation to Support the Innovative Development of High-End Medical Devices (Draft for Comment),” publicly soliciting opinions on market access pathways for emerging technologies such as multi-disease AI and large language models, thereby taking a pioneering step in establishing a regulatory roadmap for the development of large language models.
The document mentions the need to research and formulate technical guidance principles or review key points for multi-disease and large-model artificial intelligence fields; simplify the registration change requirements for AI medical device products where the core algorithm remains unchanged but its performance is optimized; and explore improvements in the requirements for evaluating the performance of AI medical devices using benchmark databases.
This may mean that the new wave of AI-assisted diagnostic and decision-support models emerging in hospitals will be classified as medical devices, subject to stringent market access reviews before they can be distributed commercially.
Potential Safety Concerns
To date, no data security issues related to large language models have been exposed in the healthcare industry, but risks have never been far from this field.
Medical data carries highly sensitive content, such as patients’ genetic information and medical history records. Once leaked, it poses a serious threat to personal privacy and may even trigger cascading risks such as genetic discrimination and insurance fraud.
Since most large language models (LLMs) currently deployed in hospitals are derived from open-source projects, modifications to the underlying code may introduce backdoors or security vulnerabilities. If hospital system architectures have inherent flaws or if data transmission encryption is inadequate, these data will be exposed to cyberattacks, facing risks of unauthorized access and misuse.
Therefore, when applying open-source AI systems in the healthcare sector, hospitals and enterprises should conduct comprehensive risk assessments and implement stringent security measures to ensure system safety and data confidentiality. Only by establishing robust safeguards for medical data security can large healthcare models achieve sustainable development.