Qitan Tech's Ambition in Nanopore Protein Sequencing Is No Longer Hidden!

QitanTech
Gene Sequencing Technology R&D Provider
Over the past month or so, the technological development and commercialization of domestically produced nanopore sequencing have clearly begun to accelerate. Whether it isWhether it is the Q20 accuracy rate of DNA sequencing, the direct reading of DNA methylation, or the launch of ultra-high-throughput sequencing chips,Domestic Nanopore Sequencing Has Achieved a Threshold-Leaping Breakthrough. It is just a matter of time before domestically produced nanopore sequencing enters every laboratory.
As an industry pioneer, Oxford Nanopore Technologies (ONT), along with a growing body of scientific research, has conducted extensive exploration into nanopore nucleic acid sequencing, which will continue to guide the improvement and development of DNA/RNA nanopore sequencing.
Following DNA and RNA, the next target is proteins.Proteins are more closely linked to physiological activities, and changes at the protein level can provide greater insights into underlying biology; therefore, protein research naturally attracts more attention. Recently, Illumina, a leader in sequencing, entered the field of proteomics through mergers and acquisitions, while Oxford Nanopore Technologies (ONT) achieved proof-of-concept for nanopore-based peptide sequencing.The leadership of industry frontrunners has further propelled proteomics technology into the new spotlight.
The concept of using nanopores for protein sequencing was formally proposed more than a decade ago. Although this came over 20 years after the development of nanopore-based nucleic acid sequencing, it is no longer a novel technological approach. However,Protein Sequencing via Nanopores: Challenges and Difficulties Far Exceed Those of DNA or RNA
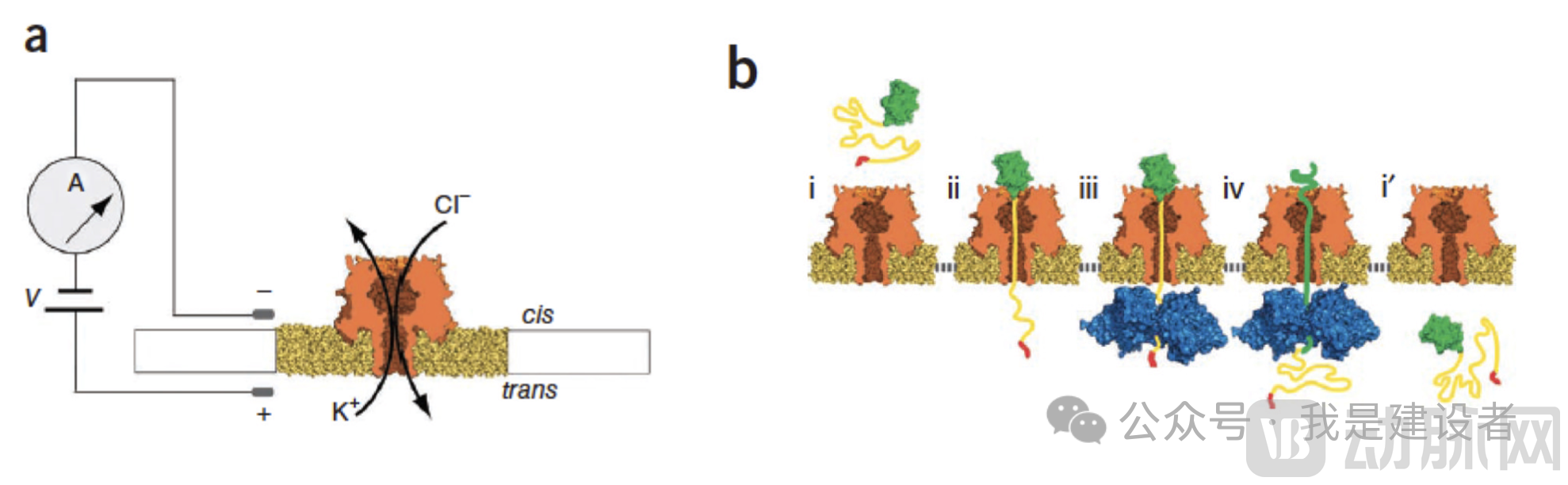
Source: Nivala, J., Marks, D. & Akeson, M.Nat Biotechnol 31, 247–250 (2013).
Unlike the four-base composition of DNA/RNA, there are 20 naturally occurring amino acids that constitute proteins.Due to differences in their side-chain groups, these 20 amino acids vary in properties such as charge, polarity, and hydrophilicity.. Of course, these atomic-level differences may give rise to unique electrical signal signatures, enabling nanopore sequencing to resolve and identify detailed sequence information.
But overall,This presents several major obstacles that must be overcome.。
First, due to the interactions among the side-chain groups of different amino acids,Polypeptide chains naturally tend to fold into complex 3D structures., for reading amino acid sequences,It is essential to first unravel this spatial conformation into a single strand to enable nanopore translocation and electrical signal readout., this not only requires unfolding before passing through the nanopore but also prevents its spontaneous folding within the porin channel.
Secondly,Positively charged amino acids need to be considered., unlike DNA/RNA, which possess negatively charged phosphate backbones that naturally facilitate consistent and stable translocation under the influence of an electric field.
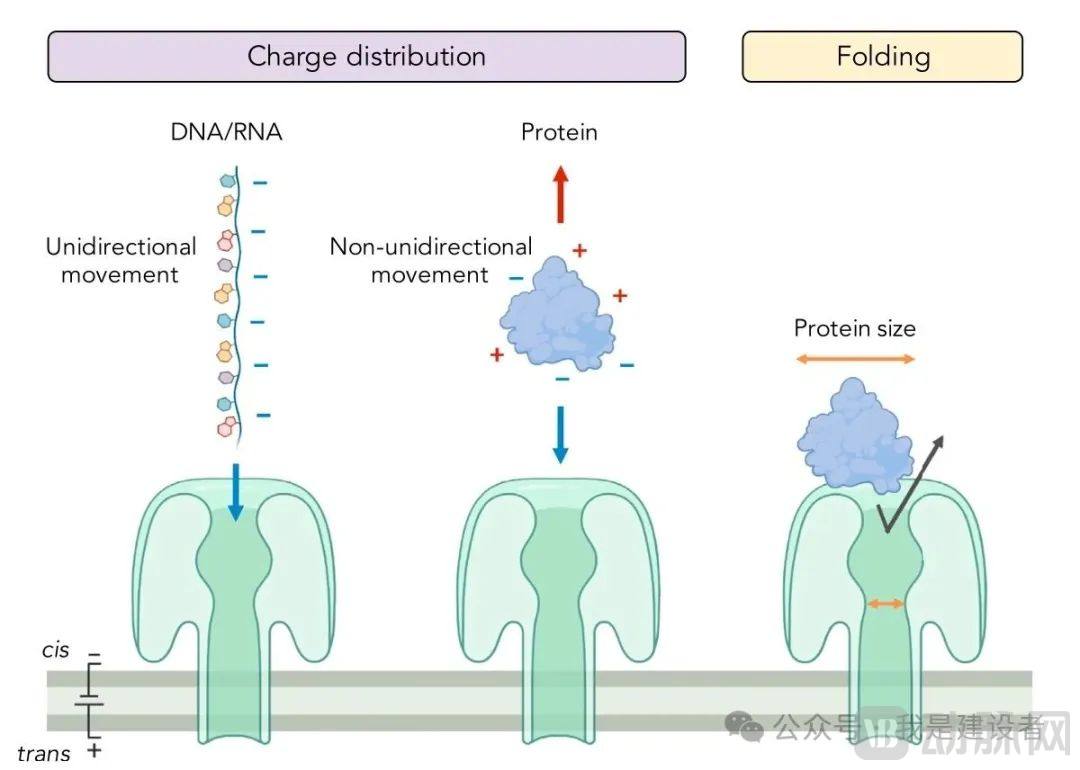
Source: https://doi.org/10.1016/j.isci.2021.103032
Even so, it is stillIt is necessary to consider slowing down the translocation speed of polypeptide chains through nanopores., similar to DNA/RNA, a system needs to be established to control its translocation speed, enabling effective reading of the amino acid sequence within the chain.
In addition, the greater diversity space of amino acid combinations allows forDecoding signal states of this magnitude from dozens of picoampere signals becomes exponentially more difficult.。
Consequently, diverse technological approaches have been successively developed to address the aforementioned challenges, thereby achieving proof-of-concept for corresponding peptide sequencing to a certain extent. These different technologies vary in their conceptual frameworks and implementation strategies regarding the protein nanopores employed, protein unfolding, translocation guidance, and control of molecular translocation.
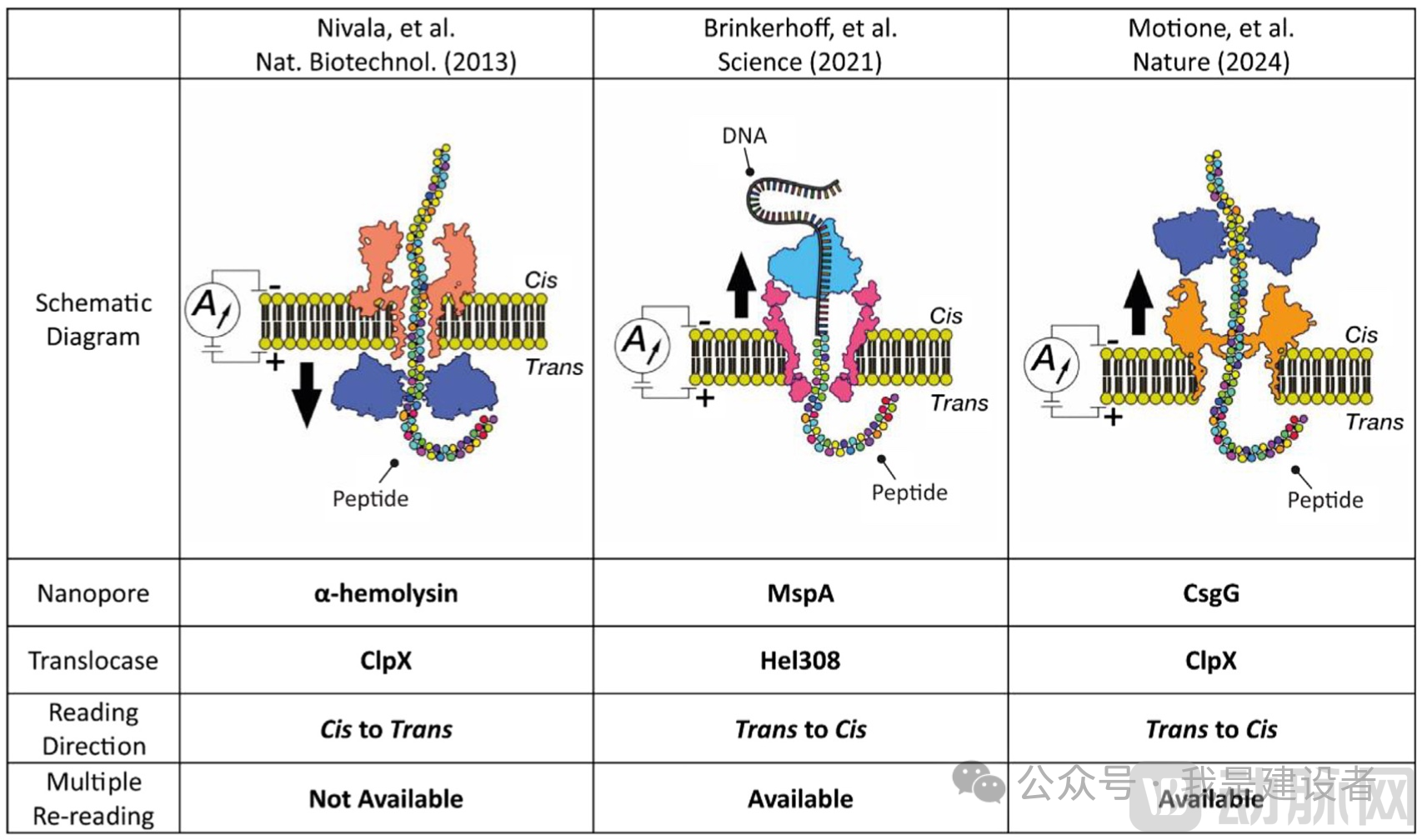
Source: https://doi.org/10.1016/j.molcel.2024.10.038
Leveraging the relatively mature technological foundation of nanopore nucleic acid sequencing, technical approaches involving oligonucleotide-conjugated polypeptide chains and the use of DNA polymerases or helicases as speed-control mechanisms have been frequently reported in recent years.(In fact, several months ago, ONT also demonstrated its achievements in using this technical approach to detect specific protein markers or protein expression tags.)However, these efforts remain largely in the stages of technical validation or early exploration, and sustained development is still required before they can be commercialized or adapted for large-scale deployment.
At the beginning of last month,QitanTechThe research group of Professor Bai Jingwei, a co-founder at Tsinghua University, published a paper in the Journal of the American Chemical Society. While it may not have attracted much attention, it holds significant importance for the peptide sequencing technical route based on DNA-conjugated peptide translocation through nanopores.

This article is titled “Spike signals and MD simulations reveal the significance of peptide stretching in nanopore protein sequencing”, based on experimental evidence and molecular dynamics simulations, the article concludes:Stretching and fixing the conformation of peptides as they pass through nanopores is a prerequisite for achieving single-amino-acid recognition in nanopore-based protein sequencing.

As early as November 2021, Bai Jingwei’s team published their technical development achievements in DNA-conjugated peptide translocation sequencing in *Chemical Science*.. In the same year, Professor Huang Shuo’s team at Nanjing University in China and Professor Cees Dekker’s team at Delft University of Technology in the Netherlands also published preliminary validation results of similar technological frameworks.
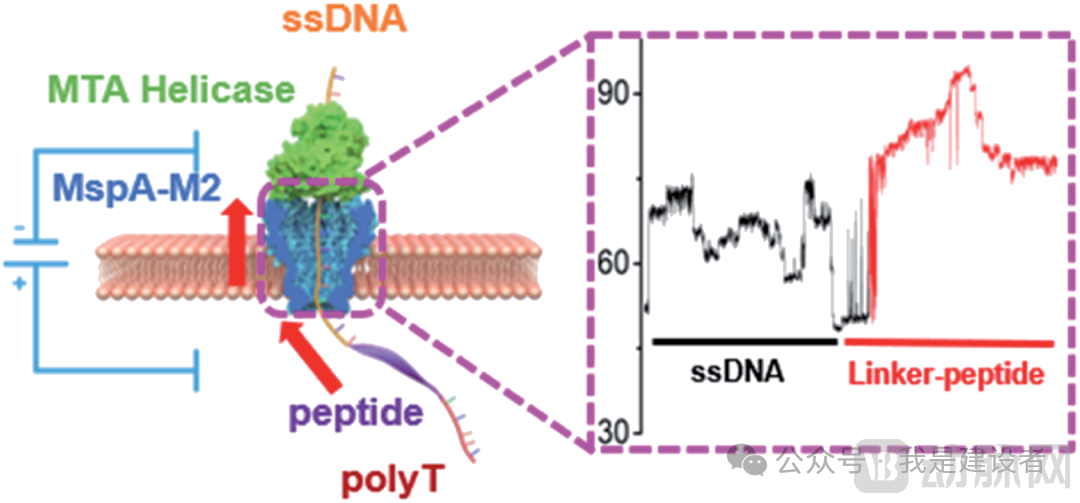
At that time, leveraging QitanTech’s existing nanopore sequencing platform, Bai Jingwei and colleagues conjugated the target peptide chains with single-stranded DNA (ssDNA) in the configuration 3’-ssDNA(89nt)-5’-N-peptide(23aa)-C-3’-polyT(30nt)-5’. They employed the high-salt-tolerant MTA-h helicase to regulate the translocation speed of the DNA, thereby controlling the passage of the target peptide chains through the nanopore, and selected MspA-M2, with its constriction site located at the bottom of the channel, as the nanopore reader.Achieved short peptide reading of 17 amino acids (aa).
The goal of peptide sequencing is naturally to achieve unambiguous identification of individual amino acids (and their modifications); more specifically, it aims to distinguish and read the side-chain groups of each amino acid.. However, in this Chemical Science article, Bai Jingwei et al. found that peptide translocation did not produce clear and reproducible stepwise ionic currents, thereby precluding the discrimination of the sequence of individual amino acid residues. Since sequencing was not feasible, they approached the problem from a different angle, aiming to determine whether this system could be used to distinguish variations in individual amino acid residues within short peptide chains. Interestingly,When some positively charged amino acids in the peptide sequence are mutated to neutral ones, the resulting changes are difficult to distinguish; however, substantial spiky oscillatory current signals can be observed at the junction where DNA is coupled to the peptide. In contrast, mutation to negatively charged amino acids or phosphorylation leads to more rapid spiky oscillations and a pronounced stepwise increase in current at the peptide region.
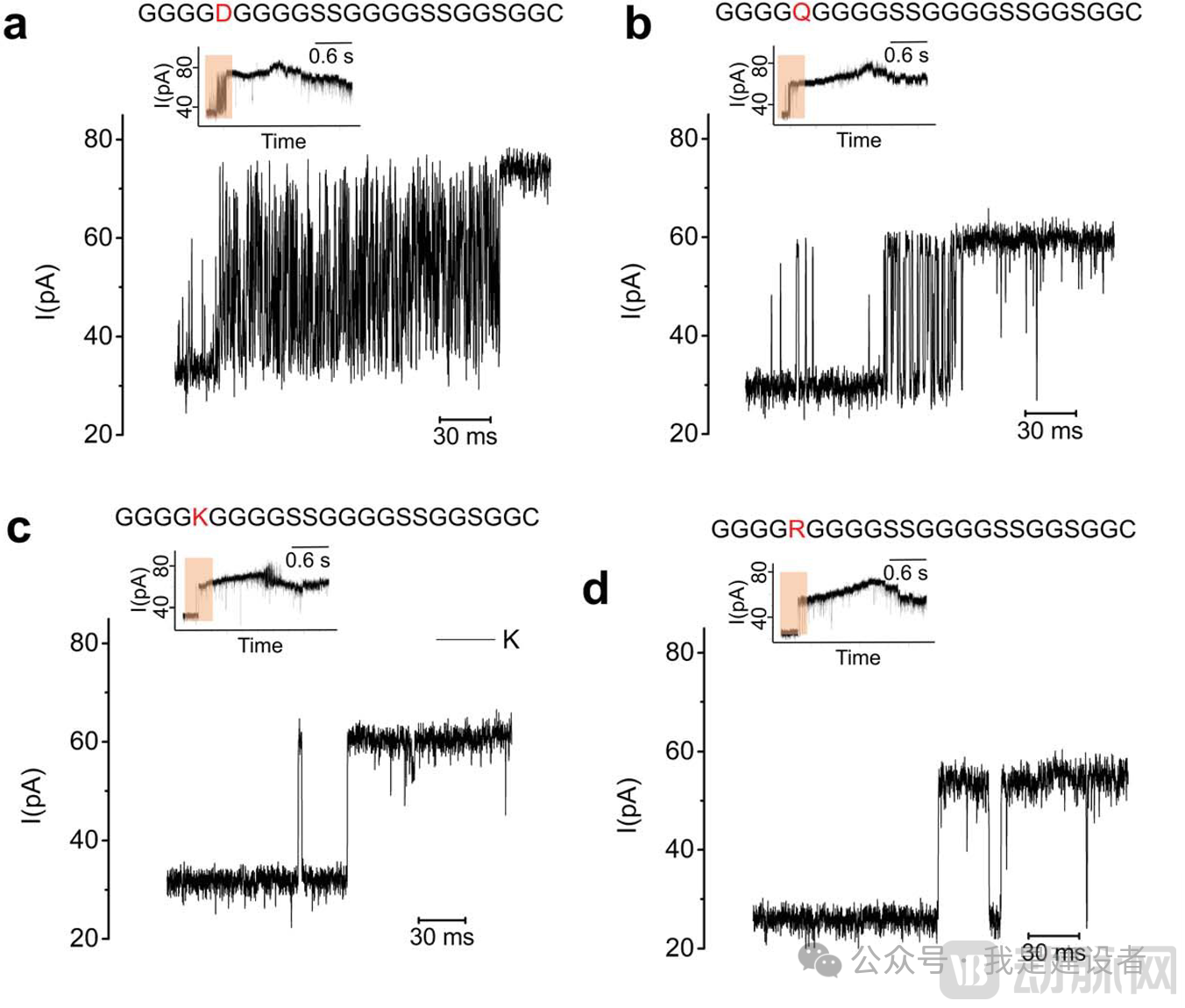
Signal conversion areas marked in brown indicate that: (a) S5D and (b) S5Q exhibit strong spike signals, whereas S5K (c) and S5R (d) show almost no spikes.
However, other articles published during the same period suggested that applying similar strategies to sequence highly negatively charged amino acid peptides achieved stepwise blockade currents. Thus, Bai Jingwei et al. hypothesized that,The charge state of amino acids in the peptide chain may be correlated with the stretching state of the peptide chain during nanopore translocation, potentially resulting in an oscillatory state akin to spring relaxation.
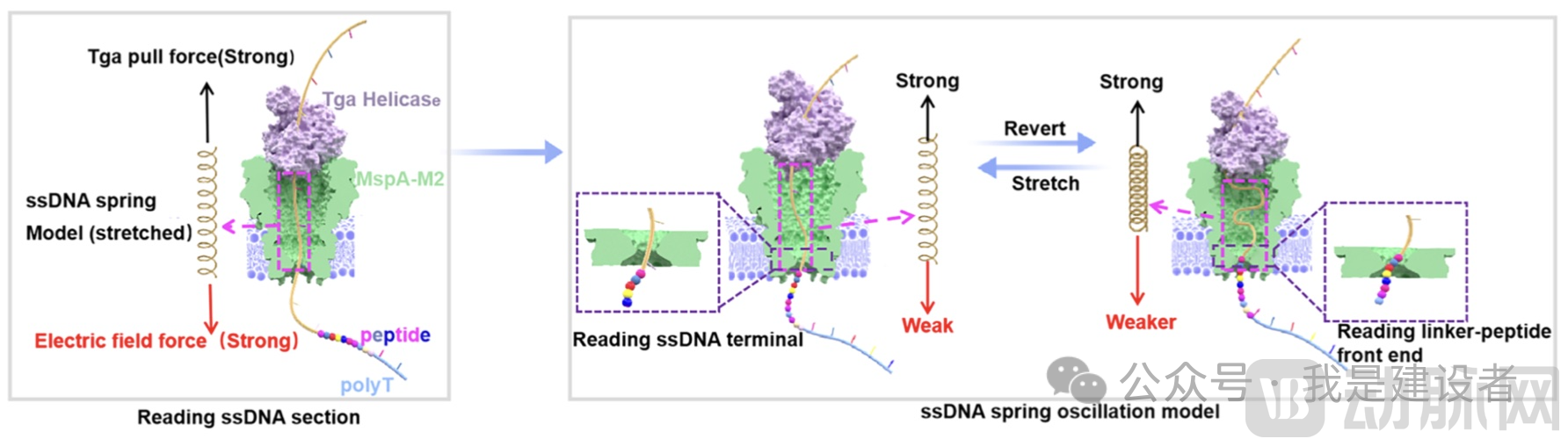
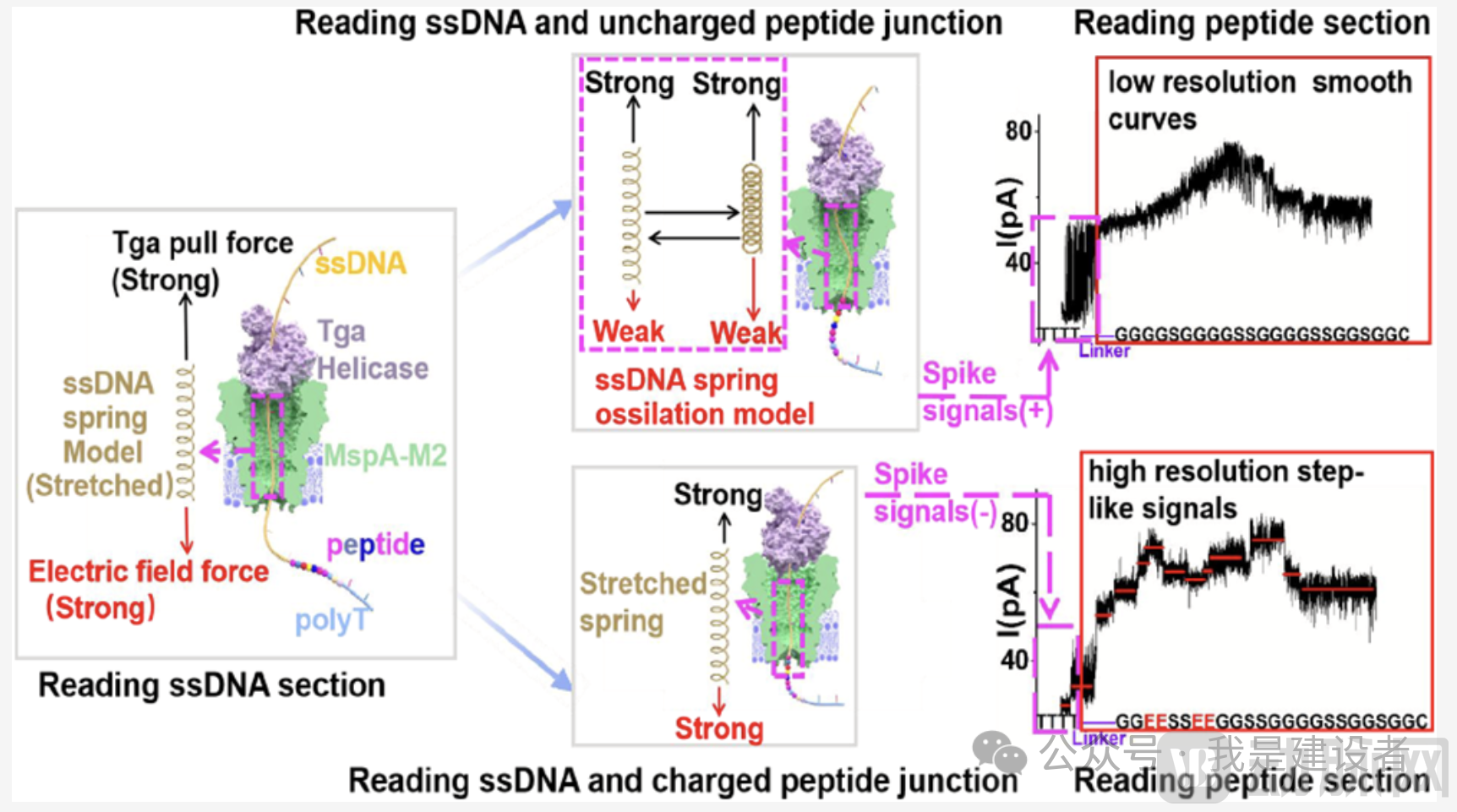
This recent JACS article can be regarded as a comprehensive validation of the hypothesis proposed four years ago.In this article, Bai Jingwei’s team has finally put forward a clear and innovative proposalDNASpring Oscillation Model, by gaining an in-depth understanding of the translocation dynamics of peptide chains within nanopores, we elucidate the mechanism by which charged amino acid mutations affect spike signals.
As mentioned earlier,At the junction between ssDNA and the peptide, distinctive spike signals are observed, manifesting as rapid, repetitive, and sharp fluctuations in the current trace., initially appearing as an “upward spike” above the ssDNA signal, followed by a transition to a “downward spike” below the peptide signal. The dwell times of these signals are all less than 5 ms, significantly shorter than the stepping time of the helicase used in the study (approximately tens of milliseconds). This indicates that the generation of these spike artifacts is not caused by motor movement, suggesting that they may be associated with conformational fluctuations of the ssDNA–peptide complex.
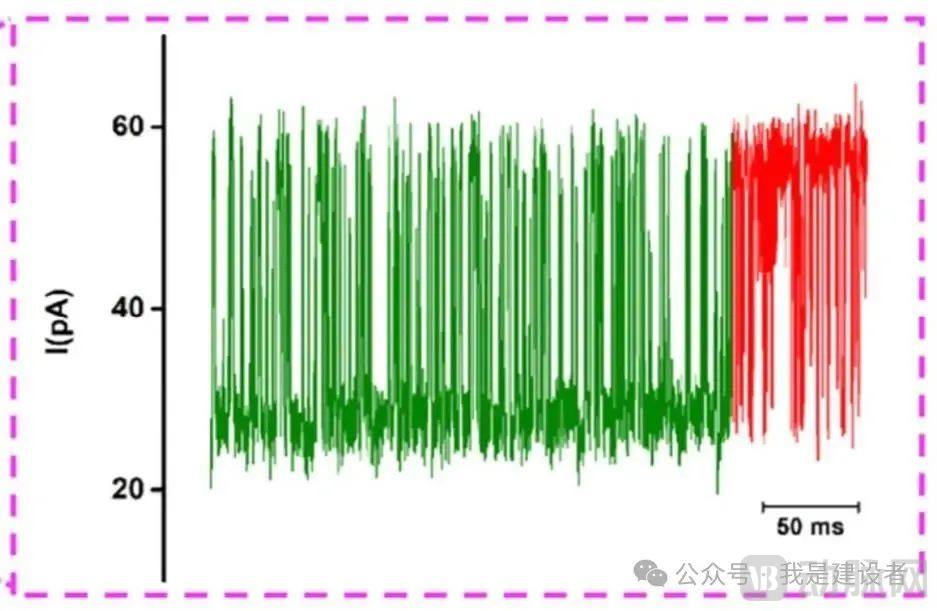
So, what exactly causes the generation of glitch signals?By comparing the signal characteristics of different amino acid mutants, it was found that if the amino acid is mutated to carry a negative charge, the ssDNA oscillation becomes brief; whereas if it is mutated to carry a positive charge, spike signals are almost absent. Meanwhile, the closer the mutated charge is to the attachment site of the ssDNA, the greater its impact on the signal. This suggestsThe charge of the peptide chain can influence the direction and magnitude of the electric field force, thereby affecting the elastic state of ssDNA.
When the negatively charged amino acids linked to the ssDNA enter the nanopore, the electric field force drops sharply. The ssDNA, which had been stretched by this force, rapidly contracts like a “released spring,” briefly pulling the peptide segment into the nanopore. This results in increased resistance and an upward spike signal. Subsequently, the ssDNA rebounds under the influence of the electric field force, causing the peptide to partially exit the nanopore. At this stage, only the ssDNA remains within the nanopore, generating a downward spike. The repetition of this process creates periodic fluctuations.
To validate the rationality of this model, the articleCritical evidence was obtained through three experiments.。
ApprovedDetection of Loss of Terminal Nucleotide Signal in ssDNA Guide Strand-Peptide Conjugates, preliminarily confirming that DNA possesses spring-like properties. Because the elastic contraction of ssDNA causes terminal bases to pass through the nanopore too rapidly to be detected, the results suggest that positive charges enhance this contraction, leading to greater loss of terminal base translocation signals, whereas negative charges inhibit contraction, thereby preserving the signal readout of terminal nucleotides.
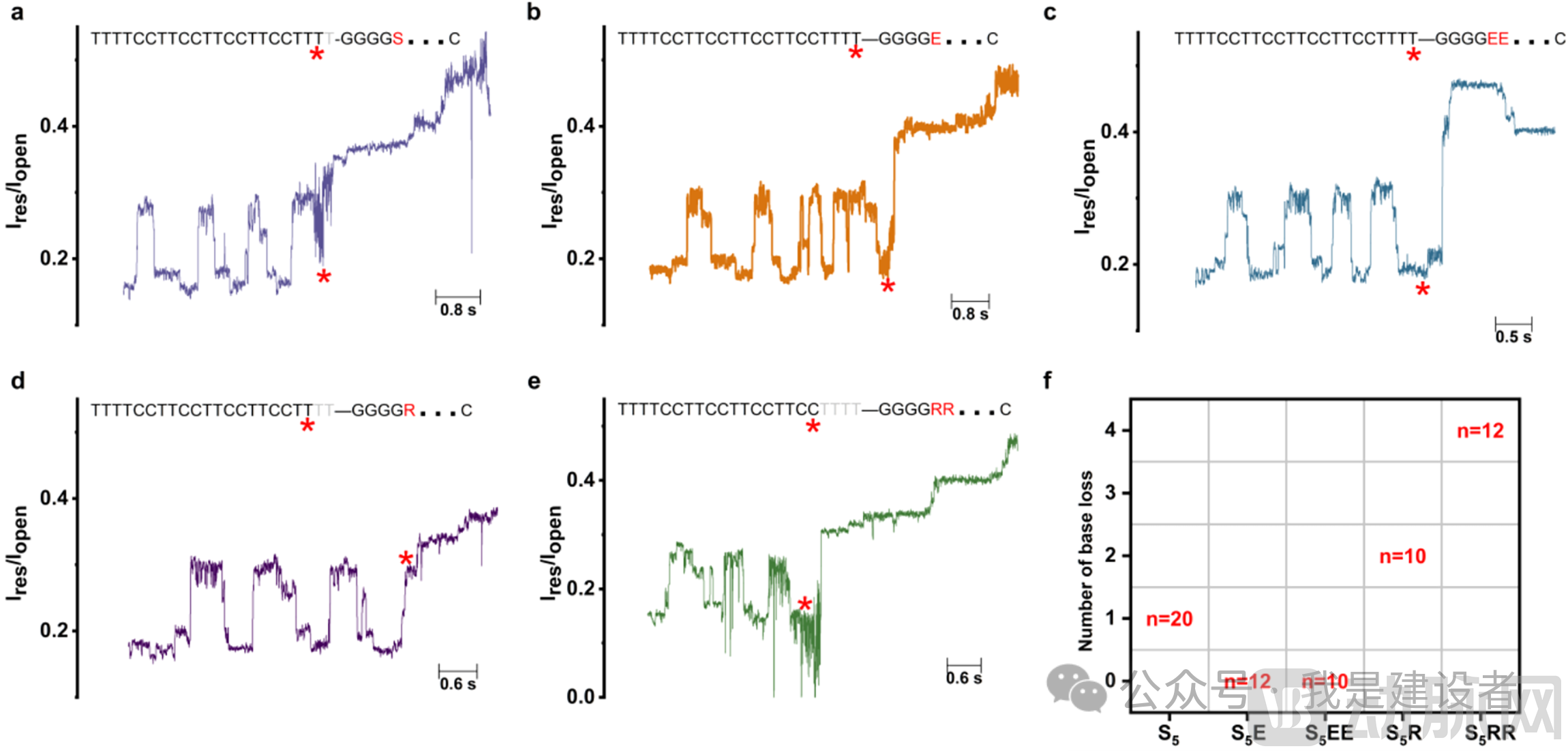
PassedIntroduction of flexible C6-spacer-modified DNA reduces the elastic constant of ssDNA, resulting in the complete disappearance of spike signals; reducing the elasticity of ssDNA suppresses its oscillatory capacity, which further supports the DNA spring model.
Molecular Dynamics Simulations Conducted in Collaboration with DeepModeling, not only directly observed the oscillatory behavior of DNA springs, but also found that uncharged polypeptides exhibit dynamic coiled/extended conformations in nanopores. This unstable conformation makes it difficult to form stepwise current signals, whereas strongly negatively charged polypeptides remain in a stretched and fixed state, thereby generating distinct stepwise signals.
Maintaining the peptide chain in a stretched conformation within the nanopore channel enables single-amino-acid resolution, which is a key message confirmed and conveyed by this article.
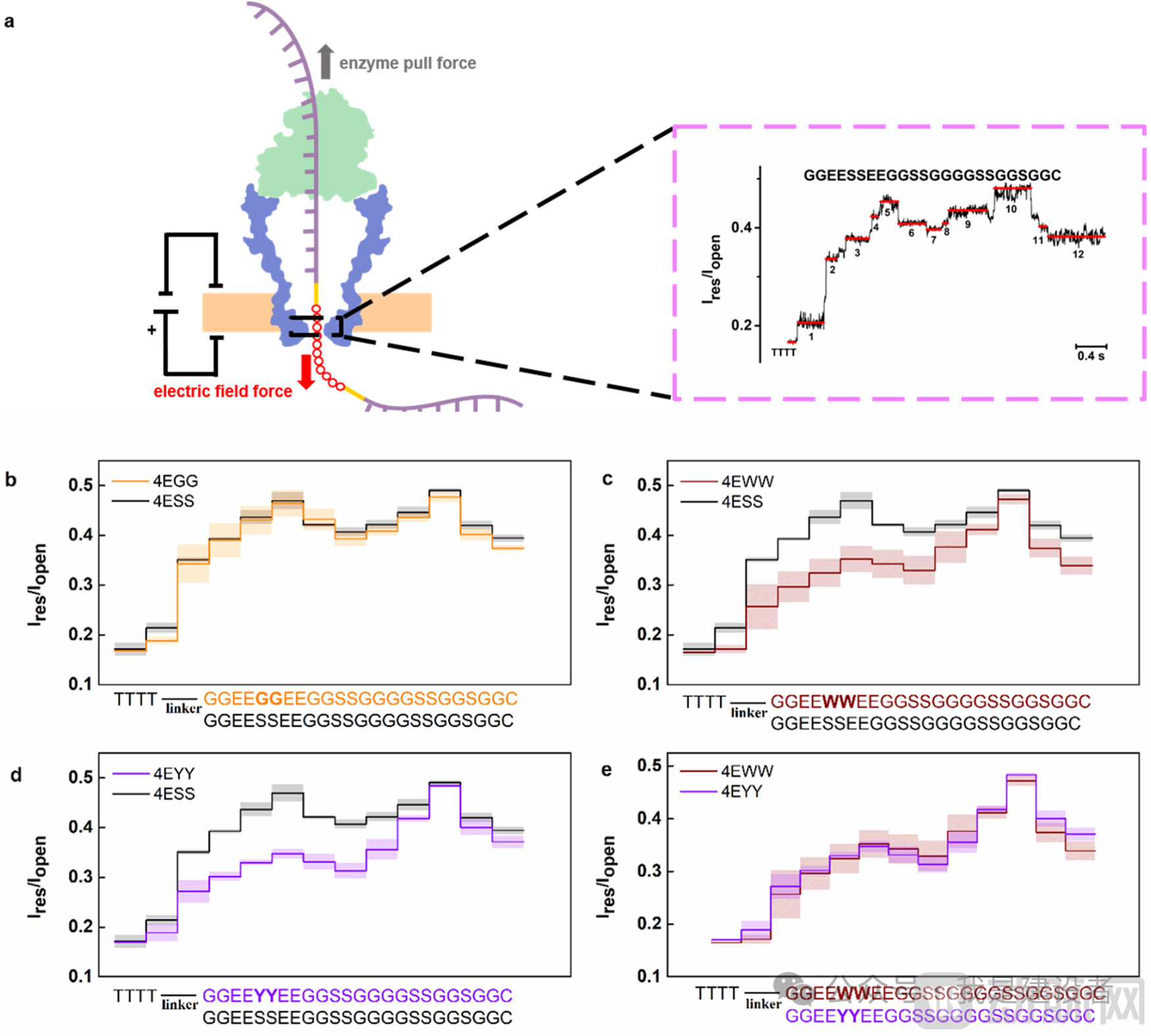
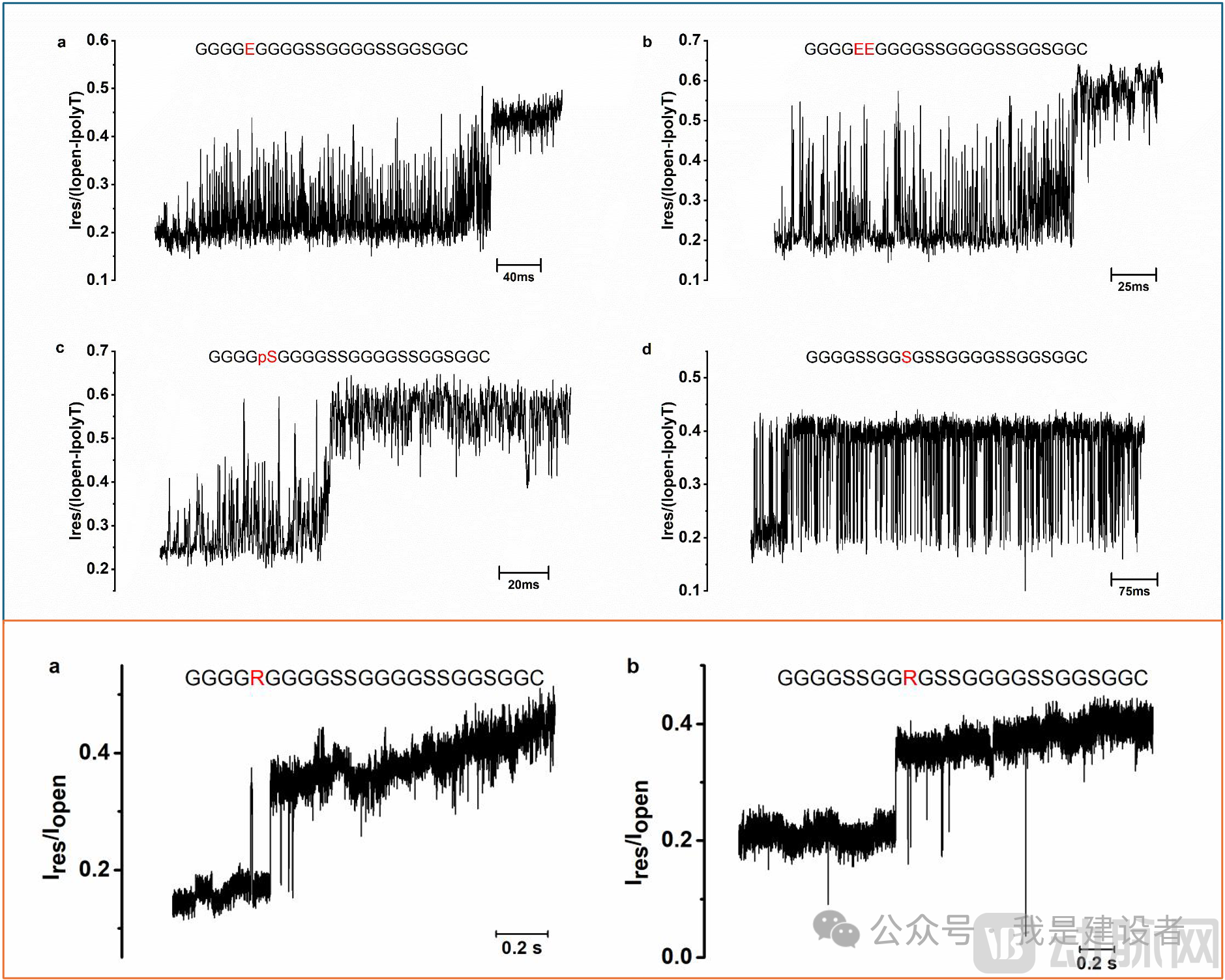
For instance, with the 4ESS peptide chain bearing periodic negative charges, the spiky signals disappeared under the combined effects of the electric field force and the helicase pulling force, restoring clear stepwise signals (averaging 12 steps), which synchronized with the motor’s stepping motion. In contrast, when mutated to 4EWW (containing tryptophan, a bulky hydrophobic side chain), the signal exhibited significant differences at positions 2–6 due to the influence of side-chain size on the pore current.And if the mutation is4EYY (Tyrosine, with a side chain ofAromatic Amino Acids), and can also be combined with4EWW signals to achieve similar discrimination, demonstrating that the nanopores used in this study are sensitive to aromatic amino acids.)
By stretching the peptide chain, its conformation within the nanopore can be stabilized and the stepwise signal restored, thereby achieving single-amino-acid resolution. This lays a critical theoretical and empirical foundation for subsequent high-resolution sequencing.
However, how can this be translated into practical workflows and the establishment of a sequencing methodology framework?
The article suggests introducing negatively charged amino acids at the ssDNA-peptide conjugation site to generate tensile forces that stabilize the peptide chain conformation. However, this approach appears impractical for real-world samples, particularly given the efficiency concerns inherent in any ligation reaction. Alternatively, does the article propose using modified DNA for conjugation to render the ssDNA backbone more rigid or uncharged?
Previous studies have largely focused on achieving the unfolding of protein folded structures and their controlled translocation through nanopores. Whether using nucleic acid polymerases/helicases or protein unfoldases such as ClpX, the prevailing assumption has been that DNA–polypeptide conjugates would maintain corresponding stepwise movement under these enzyme-controlled conditions. However, the paper by Bai Jingwei’s team pointedly highlights thatRegardless of the speed control method employed, the prerequisite for achieving single-amino-acid sequencing resolution is that the peptide chain must remain in a stretched state while stepping forward.
Of course, maintaining the peptide chain in a stretched conformation is not sufficient to achieve high-efficiency polypeptide sequencing.As suggested by this article and other industry publications,The selection of nanopores and their reading accuracy is also critical for efficiently and accurately distinguishing amino acids with similar residue structures., this will also drive subsequent efforts to continuously screen, engineer, and optimize more ideal nanopore proteins, such as smaller amino acid reading heads capable of achieving higher resolution, and longer nanopore stems/channels capable of achieving longer read lengths.
But what is clear is that,With the spring oscillation model clarified, we now have clear directional guidance for both subsequent development and optimization.,Based on the criterion of whether the stretched, fixed conformation of peptide chains can be enhanced, more robust assays can be developed to facilitate or accelerate the development and refinement of protein sequencing systems.
Recently, I had the honor of exchanging ideas with Professor Bai. Following this article,His team has achieved further progress in subsequent development, establishing a systematic framework for generating opposing forces, stretching peptide chains, and enabling high-resolution readout. This system can stably produce stepwise signals as amino acids translocate through the nanopore, thereby achieving high-resolution identification and reading of amino acids within short peptide sequences.
We believe that such a technological system is already poised for productization, as demonstrated by ONT. Although achieving long-read sequencing and de novo assembly remains exceptionally challenging,This can be used at least for targeted detection of protein biomarkers and certain phosphorylation modifications. With the joint efforts of the industry ecosystem, such tools may already be explored to address and solve many real-world problems.
It is particularly important to emphasize that,The aforementioned technologies and their corresponding patents have been exclusively licensed to QitanTech.

This methodological patent, which involves linking peptides to nucleic acids, achieving conjugate translocation under nuclease control, and obtaining peptide sequences by reading nanopore current signals,The patent application was filed in China on June 29, 2019, and entered the international phase on June 24, 2020.. Currently, patents in China and Europe have been granted, while the U.S. patent is still in the response stage.From the perspective of the patent priority date, the methodological patent obtained by QitanTech (2019Year6Month29Day) vs.ONTofDNAThe patent for peptide-conjugated nanopore sequencing is even earlier (2019Year12Month2day, through patentsGB1917599.1Apriority rights obtained through the application), which also provides QitanTech with considerable confidence for its subsequent product development and commercialization.
In the 35th year of nanopore nucleic acid sequencing, the development of protein sequencing via nanopores is just getting started, and different technological approaches may each have the opportunity to compete for dominance in the future.Given the multi-billion-dollar potential market for proteomics, any innovative technological solution will have the opportunity to showcase its capabilities on this grand stage.。
For QitanTech, such a scenario seemed to have been quietly planned since the company’s inception.
As China’s first nanopore nucleic acid sequencing company, QitanTech is quietly poised to break through in nanopore protein sequencing and make its official debut.
Reference:
https://doi.org/10.1021/jacs.5c00827
https://doi.org/10.1039/D1SC04342K