Hulu-Med: A Transparent, Unified Multimodal Foundation Model for Holistic Medical Understanding
Editor’s Note: This article is from QbitAI (WeChat Official Account ID: QbitAl). Republished with permission by VCBeat.
From imaging diagnosis to surgical guidance, from multilingual consultations to rare disease reasoning—
Medical AI is evolving from a “specialty assistant” into an “all-rounder.”
This is the general-purpose medical vision-language large model jointly proposed by Zhejiang University (Wu Jian/Liu Zuozhu Group), Shanghai Jiao Tong University (Xie Weidi Group), the University of Illinois Urbana-Champaign (UIUC, Sun Jimeng Group) in collaboration with Alibaba, Hunan University, A*STAR Singapore, China Mobile, Angelalign, and the Key Laboratory of Artificial Intelligence in Medical Imaging of Zhejiang Province.Hulu-Med,First TimeAchieve unified understanding of medical text, 2D images, 3D volumes, and medical videos within a single model.
Simply put, it isA Model That Comprehends the Entire Medical World。
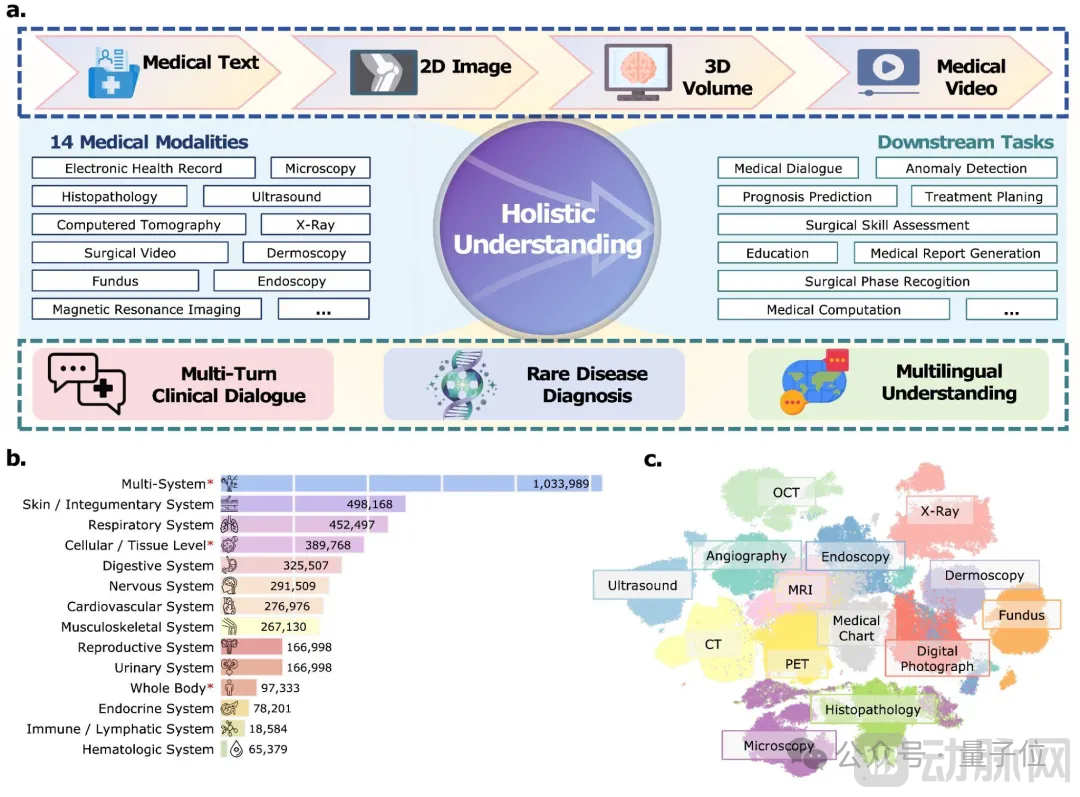
Moreover, as an open-source model, its training data are derived entirely from public medical datasets and proprietary synthetic data, which not only substantially reduces GPU training costs but also demonstrates performance comparable to that of leading models in 30 authoritative benchmarks.GPT-4.1the superior performance of closed-source models.
This means that academic institutions and medical developers can reproduce and customize high-performance medical models without relying on proprietary data, significantly reducing privacy and copyright risks.

Below are more detailed information about Hulu-Med.
Fragmentation and Lack of Transparency in Medical AI
The development of medical artificial intelligence is at a critical crossroads.
In the past, AI applications in healthcare were limited to single-task/single-modality scenarios. Researchers have developed numerous high-performance specialized models targeting individual tasks such as radiological imaging, pathological slides, or surgical videos.(Specialized Models)。
However, these models feature heterogeneous architectures and siloed data, functioning as isolated “information islands.” When comprehensive analysis of a single patient’s multimodal data is required in clinical practice, it becomes necessary to assemble a complex and costly system. This not only incurs high maintenance costs but also limits the ability of AI to learn from and reason through cross-modal associations.
Today, the rise of large language models and foundation models has brought us the realization of “general medical intelligence” (Generalist Medical AI)” of hope, promising to resolve the aforementioned challenges.
However, this wave has also brought a more severe challenge: the lack of transparency(Lack of Transparency). Many leading medical AI systems often keep their training data sources, processing methods, model architectures, and even evaluation details confidential. This lack of transparency is a key barrier hindering the widespread adoption of AI in the healthcare sector:
● The research community finds it difficult to independently verify and improve upon them;
● Regulatory agencies face challenges in assessing their safety and fairness;
● Clinicians find it difficult to fully trust and integrate these tools into high-risk decision-making processes;
● Data privacy and copyright issues also pose significant potential risks.
It is precisely against the backdrop of the coexistence of two major industry pain points: fragmentation and opacity,Hulu-Medemerged as the times required, aiming to provide a truly unified(Unified)and fully transparent(Transparent)solution.
Toward Unified, Transparent, and Efficient Medical AI
The research team adhered to three core design principles in its R&D efforts:Full-Modal Understanding(Holistic Understanding)、Economies of Scale(Efficiency at Scale) withEnd-to-End Transparency(End-to-End Transparency) 。
Hulu-Med aims to be a “medical generalist,” capable not only of understanding single types of data but also of integrating them to holistically assess patients’ health status.
Core Innovation 1: Unprecedented Transparency and Openness
Hulu-Med willTransparencyAs the highest priority, the research team firmly believes that open source and openness are the inevitable path to promoting the healthy development of medical AI.
● Fully Open Data Sources:
Training of Hulu-MedSolely based on publicly available datasets and synthetic data, eliminating reliance on private, sensitive data.
The research team has meticulously curated and constructed the largest known scale to date(16.7 million samples)Open Multimodal Medical Corpus, covering 12 major human organ systems and 14 primary medical imaging modalities(including over 60 specific types such as CT, MRI, X-ray, and pathology) 。
● Synthetic Strategies for Addressing Data Challenges:
Publicly available data often suffer from issues such as uneven modality coverage, inconsistent quality of image-text alignment, and significant long-tail distributions.
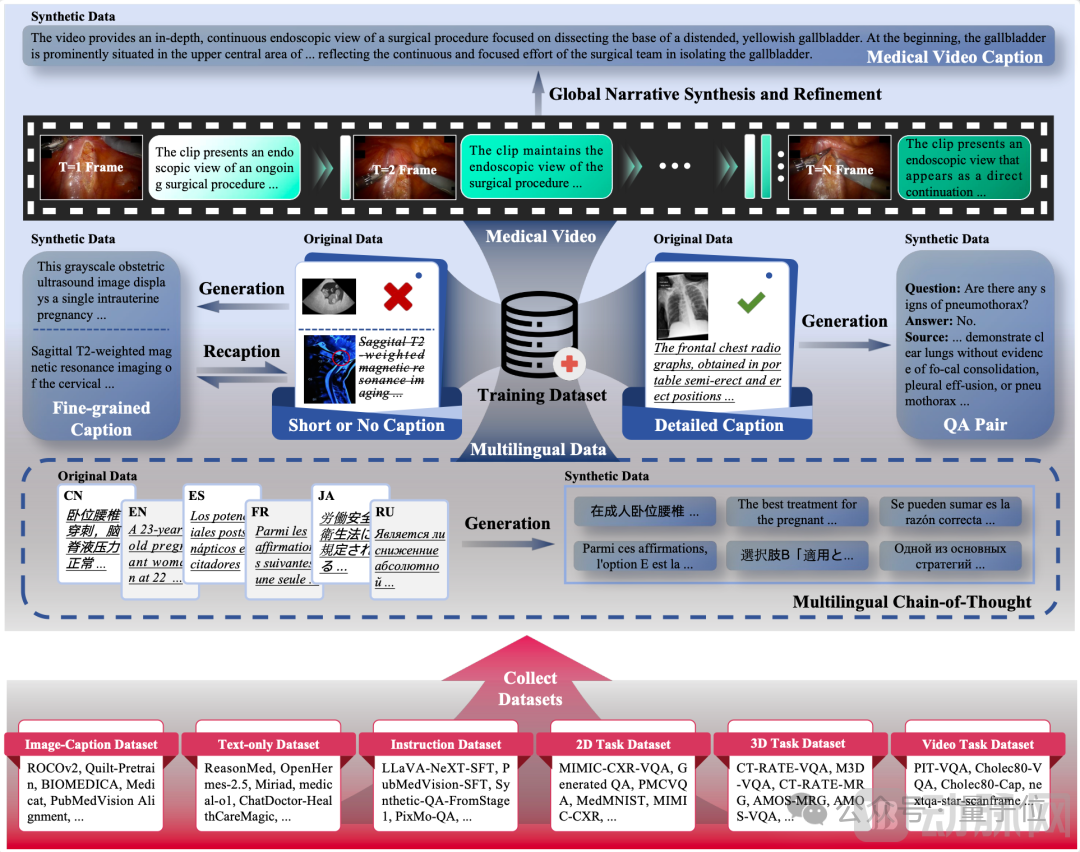
To overcome these challenges, the research team developed five specialized data synthesis pipelines capable of expanding brief captions into detailed descriptions and generating high-quality, long-form textual descriptions for unlabeled images.(particularly for modalities with sparse samples)• Construct diverse visual question-answer pairs • Generate multilingual long chain-of-thought(Long CoT)Inference data and temporal description generation for unlabeled surgical videos.
These high-quality synthetic data(approximately 2.86 million samples in total)Greatly enriches the training corpus, enhancing the model's generalization capability and its ability to understand complex instructions.
● End-to-end full-process open source:
The research team has publicly released the entire R&D pipeline, including detailed data filtering and synthesis workflows, three-stage training code, evaluation scripts for all benchmarks, and the final trained model weights.
This means that any researcher can fully reproduce the team’s work and either improve upon it or fine-tune it for specific applications.
● Mitigating Risks, Empowering Communities:
This thorough openness not only effectively mitigates the risks of privacy breaches and copyright disputes associated with the use of proprietary data, but more importantly, it empowers the entire research community, lowers the barrier to entry for developing high-quality medical AI, and helps foster the emergence of more customized and trustworthy healthcare applications.
The positive feedback Hulu-Med has received on GitHub and Hugging Face, including its consecutive number-one rankings on the Hugging Face medical trending list over the past two weeks, serves as a testament to the recognition of its open-source strategy.
Core Innovation II: Unified Multimodal Understanding Architecture for Medicine
One of Hulu-Med’s core technological breakthroughs lies in its innovative unified architecture,First timeAchieved native processing of four core modalities—text, 2D images, 3D volumes, and medical videos—within a single model.
Traditional VLMs typically require different visual modalities(such as 2D images and 3D volumes)Designing independent encoders, or adopting the compromise approach of decomposing 3D/video data into sequences of 2D frames, limits the model’s deep understanding of spatial or temporal continuity.
Hulu-Med, on the other hand, takes a different approach:
● Innovative Application of Rotary Positional Encoding:
Adopting the advanced SigLIP vision encoder, integrated with 2D rotary positional encoding(2D RoPE)combined.
2D RoPE can dynamically encode the relative positional information of patches in two-dimensional space, without requiring predefined fixed input dimensions.
● Unified Visual Encoding Unit:
Through ingenious design, it treats image patches as universal processing units across all visual modalities (2D images, 3D slices, and video frames), enabling the model to process 3D volumetric data as sequences of slices and video data as sequences of frames.
and naturally comprehend their spatial or temporal continuity and correlations within a unified Transformer architecture, whileNo need to introduce any complex modules specific to 3D or video.。
This unified architecture not onlySupports medical image input at any resolution, it also naturally possesses powerfulSpatiotemporal Understanding Ability。
● Decoupled Training Approach:
Based on Independent Visual Encoders and Large Language Models(LLM)The decoder undergoes continuous pre-training and post-training, offering substantial flexibility that allows researchers to easily replace or upgrade the vision encoder or LLM backbone according to specific needs.(When using Qwen series models of different scales or capabilities), without waiting for the emergence of a new general-purpose VLM before conducting post-training for medical scenarios.
This “native” multimodal integration approach, compared to merely fine-tuning general-purpose Vision-Language Models (VLMs), better ensures transparency in data usage and strengthens domain-specific reasoning capabilities, making it key to building reliable clinical AI systems.
Core Innovation III: Balancing Efficiency and Scalability
Processing large-scale medical data, particularly 3D volumetric and video data comprising numerous slices or frames, imposes extremely high demands on computational resources.
Hulu-Med successfully achieves a balance between high performance and high efficiency through a series of innovative designs.
● Medical-Aware Token Compression:
To address the prevalent issue of inter-frame/inter-slice information redundancy in 3D and video data, the research team proposed a "Medical-Aware Token Compression" strategy.
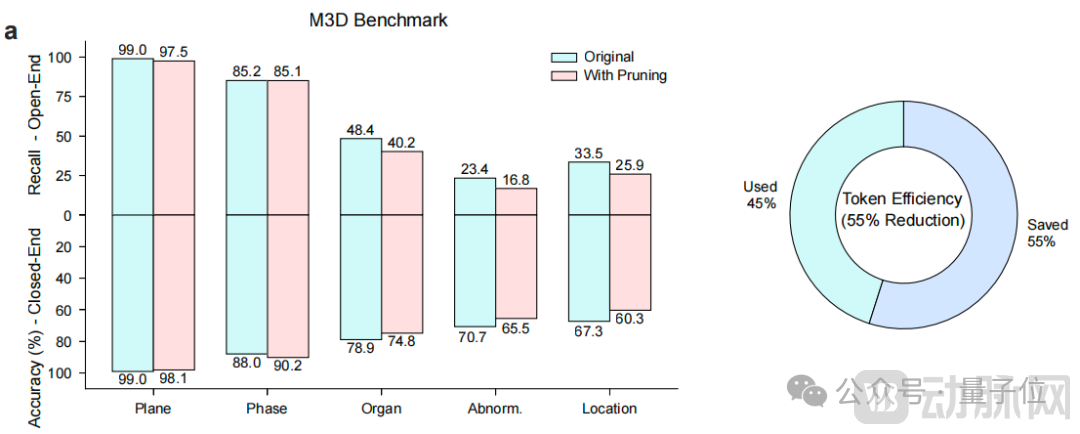
This strategy combines in-plane bilinear interpolation downsampling with inter-plane redundant token pruning based on L1 distance, achieving an average reduction of approximately55%the number of visual tokens (as shown in the figure above).
This significant efficiency improvement makes it possible to process surgical videos lasting several hours, while substantially reducing memory and computational overhead during model inference.
● Progressive Three-Stage Training Program:
Hulu-Med adopts a meticulously designed progressive three-stage training pipeline.

Phase I, freeze the LLM and train only the visual encoder and projector, leveraging massive 2D image–short text pairs to establish foundational vision-language alignment.
Phase II, we conduct continuous pre-training by incorporating long-text descriptions and general-purpose data, while unfreezing all model parameters, with the aim of injecting rich medical knowledge and enhancing general visual-text understanding capabilities.
Phase III, conduct mixed-modality instruction fine-tuning by incorporating diverse downstream task data—including 3D, video, multi-image, and interleaved image-text formats—to comprehensively enhance the model’s instruction-following and complex reasoning capabilities.
This “easy-first, hard-later; progressively deeper” strategy fully leverages the relatively abundant 2D data resources to build a robust foundation for visual representation, enabling the model to learn more quickly and effectively when subsequently tackling 3D and video tasks with relatively limited data.
Experiments demonstrate that this progressive training approach significantly outperforms the method of mixing all modalities together.
● Controllable Training Costs:
Thanks to its efficient architecture and training strategies, the training costs of Hulu-Med have been effectively controlled.
Even the largest 32B-parameter model required only about40,000A100 GPU hours, while the 7B model requires only about4,000GPU hours.
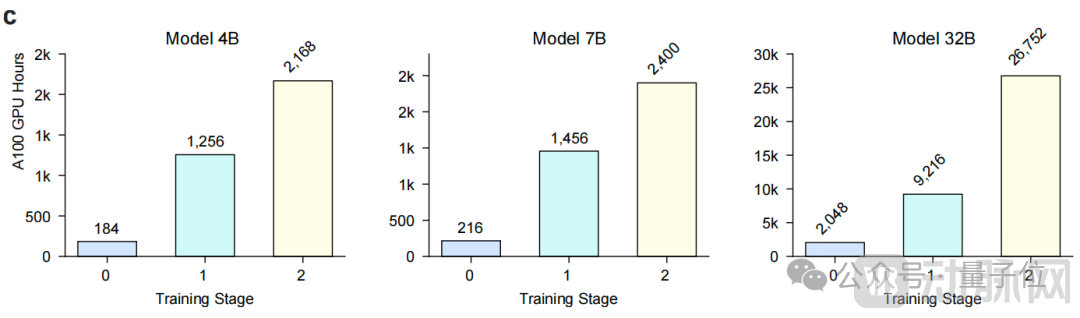
This means that general-purpose medical VLMs with state-of-the-art (SOTA) performance can be developed within computationally feasible budgets, significantly enhancing the accessibility of advanced medical AI technologies.
Setting a New Benchmark for Medical Vision-Language Models
To comprehensively evaluate the capabilities of Hulu-Med, the research team30 Public Medical Benchmarks...underwent extensive and rigorous evaluation.
These benchmarks range from basic text-based question answering and image classification to complex visual question answering.(2D, 3D, Video). Medical Report Generation(2D、3D), to various task types such as multilingual understanding, rare disease diagnosis, and multi-turn clinical dialogue that require deep clinical knowledge and reasoning capabilities, while simultaneously evaluating the model's in-distribution(ID)and out-of-distribution(OOD)Task Generalization Ability.
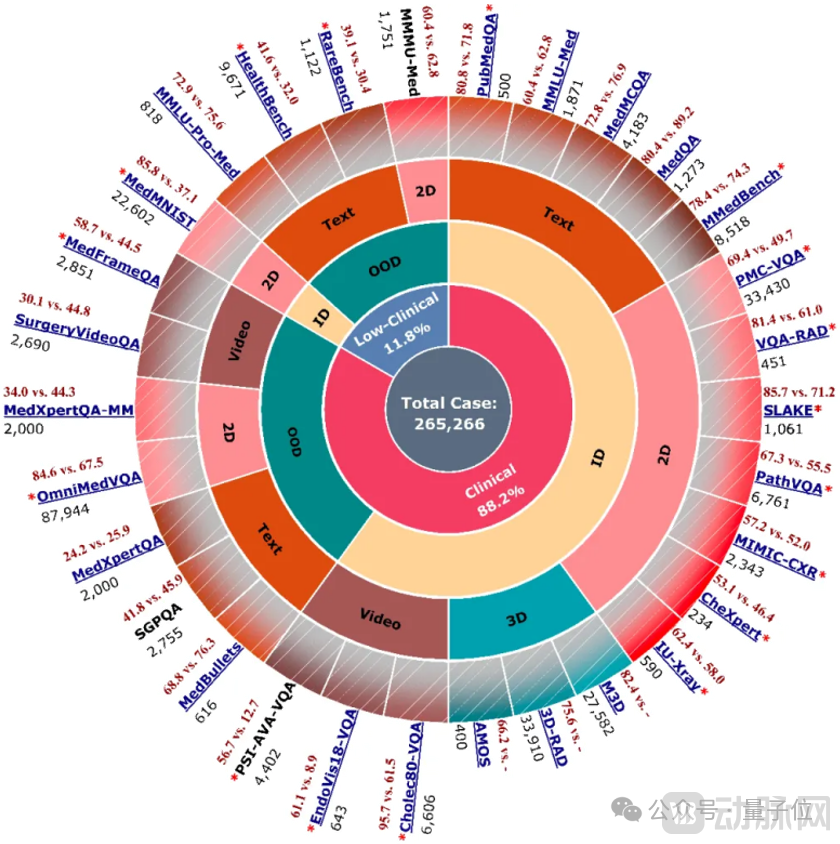
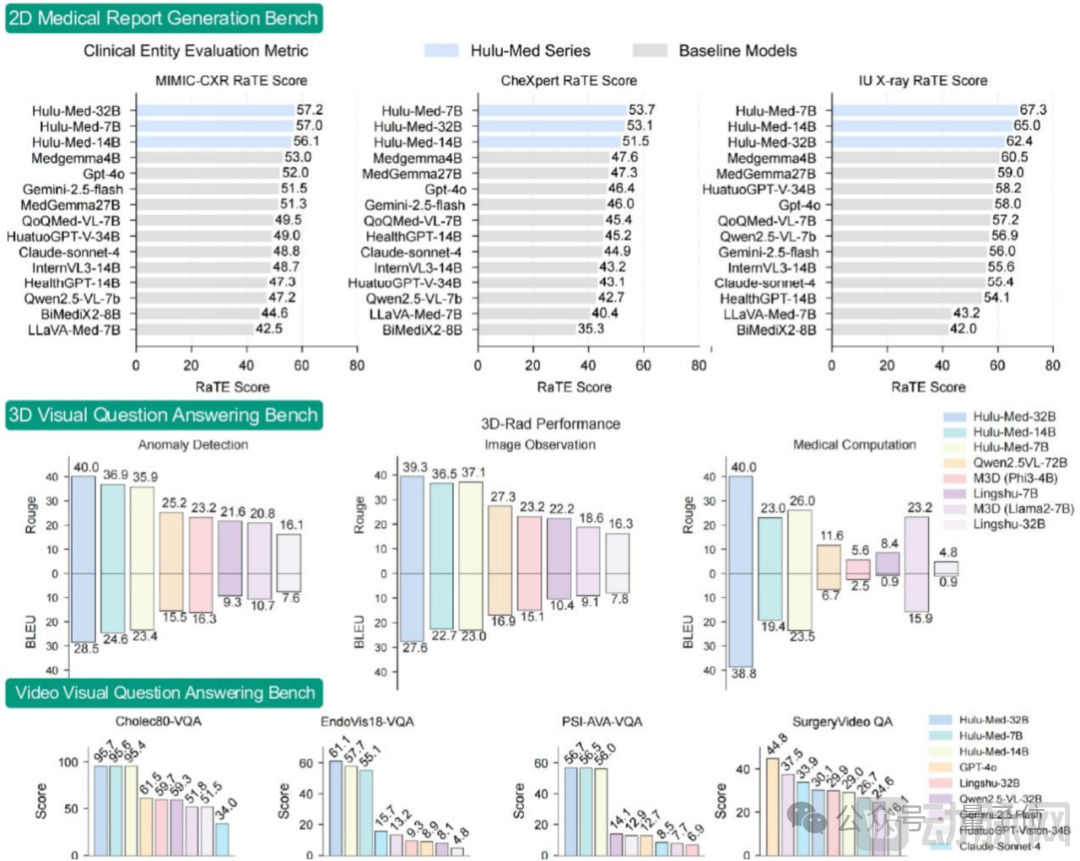
Ultimately, Hulu-Med’s performance was remarkable. As shown in the figure above, among the 30 benchmarks included in the comparison, Hulu-Med achievedAll 27 metrics surpassed existing open-source medical or general-purpose VLMs.。
Moreover, it rivals and even surpasses top-tier closed-source systems, outperforming powerful closed-source models in 16 benchmarks.GPT-4o。
Notably, although Hulu-Med is a vision-language model, it outperformed GPT-4o and matched the performance of GPT-4.1 on HealthBench, a pure-text clinical dialogue benchmark recently proposed by OpenAI, fully demonstrating that its robust text understanding and reasoning capabilities have not been compromised by multimodal training.
Furthermore, whether in 2D medical VQA and report generation(Particularly outstanding in terms of the RaTEScore metric, which reflects clinical value), or in 3D VQA and report generation that require spatial understanding(superior to specialized 3D models), or video understanding tasks that require temporal reasoning(e.g., MedFrameQA and various surgical VQA), Hulu-Med demonstrated leading or highly competitive performance.
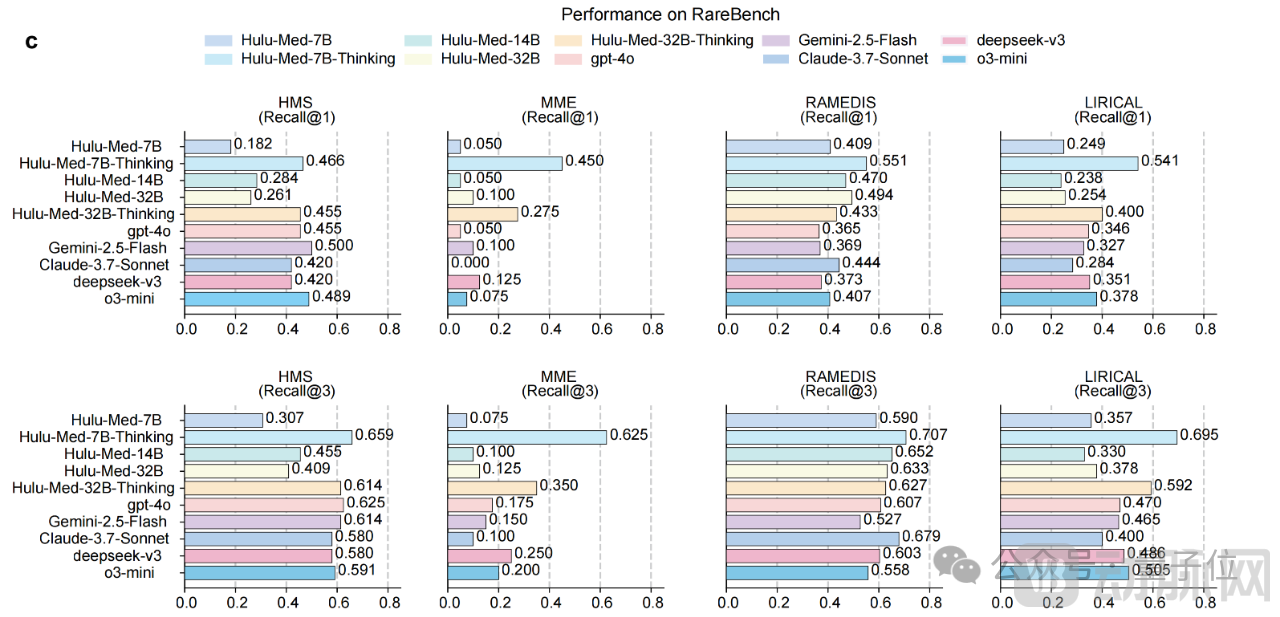
Multilingual Medical Understanding in Simulating Real-World Clinical Challenges(MMedBench, Six Languages)Rare Disease Diagnosis(RareBench)Multi-turn Clinical Safety Dialogue(HealthBench)Hulu-Med also demonstrates outstanding performance on such tasks.
Especially when combined with Chain-of-Thought(CoT)When prompted, it outperformed multiple leading closed-source models, including GPT-4, in multilingual and rare disease diagnosis, demonstrating its significant potential for clinical applications (as shown in the figure above).
The success of Hulu-Med validates that world-class general-purpose medical AI models can be built by systematically integrating public data, adopting a unified and efficient architecture, and adhering to a fully open and transparent approach.
Despite significant progress, Hulu-Med still has considerable room for improvement. Future research directions include:
● Integration of more multimodal data: Incorporating multiscale biological data, such as genomics and proteomics, into models to achieve a true multiscale understanding of diseases from macroscopic imaging to microscopic molecular levels, advancing toward predictive and personalized medicine.
● Continuously expand the scale of open data: Further aggregating a more diverse range of publicly available medical datasets worldwide is expected to continue enhancing the model’s performance and generalization capabilities.
● Deepen clinical reasoning capabilities: Leverage larger-scale and more diverse chain-of-thought data, combined with advanced training paradigms such as reinforcement learning, to further optimize the model’s clinical logical reasoning, interpretability, and reliability.
● Establish an efficient continuous learning mechanism: Ensure that the model remains synchronized with rapidly evolving medical knowledge.
● Promoting Clinical Validation and Integration: Leveraging Hulu-Med as the foundation, integrate it with specialty models or multi-agent systems to conduct validation within real-world clinical workflows, ensuring its safety and efficacy.
Overall, Hulu-Med represents a significant step toward holistic, transparent, and high-performance medical AI. It is not only a high-performance model but also an open-source research starting point and a comprehensive technical blueprint.
The research team firmly believes that openness and collaboration are key to driving the sustainable development of the medical AI field. The initial success of Hulu-Med on open-source communities such as GitHub and Hugging Face also validates the value of this philosophy.
Meanwhile, the team sincerely invites researchers, developers, and clinicians in relevant fields to leverage open models and data resources such as Hulu-Med to jointly explore, build, and validate the next generation of precise, inclusive, and personalized medical AI systems!
Paper Link: https://arxiv.org/abs/2510.08668
GitHub Link: https://github.com/ZJUI-AI4H/Hulu-Med
Hugging Face Link: https://huggingface.co/ZJU-AI4H/Hulu-Med-32B