Can China Replicate OpenEvidence? The Rise of the Fastest-Growing AI in U.S. Healthcare

OpenEvidence
Medical Artificial Intelligence Technology Researcher

BAICHUAN AI
AI Medical Technology Researcher

Testing OneLife
Internet Health Management Service Provider

Yidu Cloud
Medical Big Data Platform
Authors: Zi Ren, Yao Jing
11 months, free, covering 40% of U.S. physicians.
OpenEvidence, a U.S. company, has demonstrated that even in healthcare—the most difficult industry to penetrate—a phenomenon-level blockbuster product can be achieved by leveraging specialized small models and viral growth through precise development strategies.
Founded just four years ago, OpenEvidence has set multiple industry records: approximately 40% of practicing physicians in the United States are active users, with over 250,000 registered doctors and more than 60,000 clinical queries processed daily, making it the fastest-growing AI platform for physicians in history. Since July of this year, the number of monthly clinical consultations on the platform has nearly doubled, reaching 15 million. This indicates a rapidly growing demand for this tool among healthcare professionals.
At the capital level, its valuation has seen rocket-like growth: valued at $3.5 billion in July 2025, it surged to $6 billion after completing a $200 million financing round in October, marking an increase of nearly 70% in just three months. To date, the company has secured over $300 million in investment from prominent venture capital firms such as Google Ventures, Sequoia Capital, Kleiner Perkins, and Blackstone Group, establishing itself as one of the highest-valued startups in the medical AI sector.
In the face of such a rapidly surging project, we cannot help but ask: What exactly did it do right? Are there similar products in China?
Addressing the practical pain points of clinicians is the core logic behind OpenEvidence’s development.
According to research published in *Nature*, medical knowledge now doubles every 73 days, whereas in 1950, this figure was 50 years. Based on this calculation, medical students would need to study more than 29 hours per day to keep pace with the publication rate of specialty literature, which is clearly impossible.
The founder of OpenEvidence cited an example: a patient with psoriasis comorbid with multiple sclerosis consults a dermatologist. The dermatologist then faces a dilemma, as they wish to avoid exacerbating the multiple sclerosis, which is a neurological disorder. It is challenging for dermatologists to rapidly access the latest evidence on the efficacy of IL-17 and IL-23 inhibitors, particularly regarding their efficacy and safety in patients with comorbid multiple sclerosis.
In traditional scenarios, doctors have to resort to PubMed, but searches yield only article titles, failing to provide answers to highly specific questions such as “How do the safety profiles of IL-17 inhibitors compare with those of IL-23 inhibitors?” From an AI engineering perspective, this is a process of seeking out edge cases: the comparative safety of IL-17s and IL-23s in patients with psoriasis and multiple sclerosis may be addressed in a particular article within a top-tier, peer-reviewed medical journal, yet it would never appear in the title.
According to Zhang Shichen, a partner at Zhiyaoju, OpenEvidence can be understood from two dimensions: from a technical perspective, it is an enhanced version of Google for medical evidence; from a product perspective, it is a ChatGPT designed exclusively for physicians.

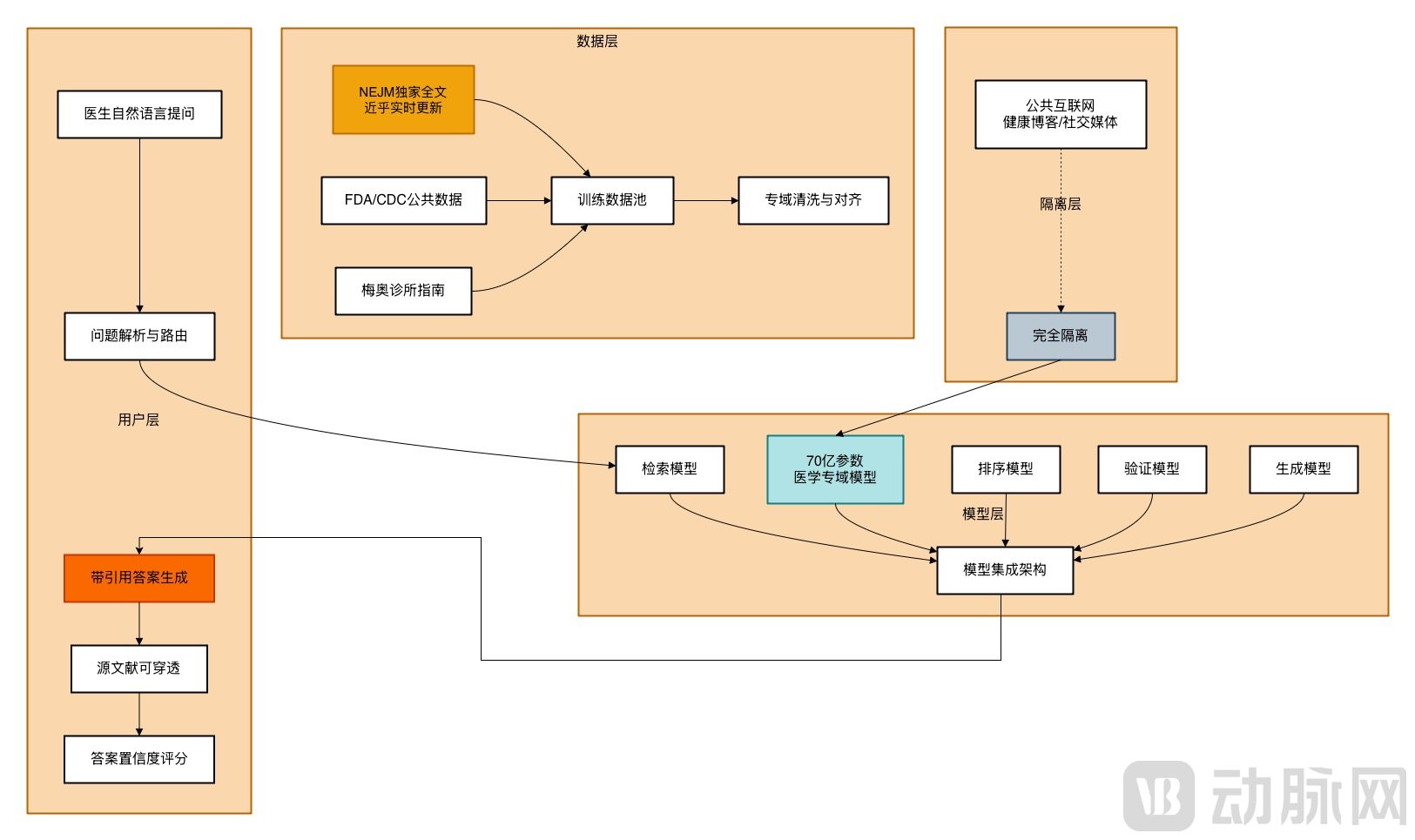
OpenEvidence provides an AI-powered search engine for licensed physicians, delivering trustworthy medical evidence amidst the exponential growth of medical knowledge. By integrating authoritative medical literature from around the world, it generates traceable, structured clinical decision support content within seconds. At its core, OpenEvidence addresses the pain point of “knowledge overload coupled with a scarcity of credible information.” Every conclusion it outputs is precisely linked to specific paragraphs in top-tier journals such as NEJM and JAMA, thereby mitigating the risk of AI hallucinations.
OpenEvidence opts for vertical specialization over a scale-driven competition model in building its product.
OpenEvidence has abandoned the "parameter race" logic of general-purpose AI, opting instead for a path of vertical knowledge deepening. Its technical framework is built around three core pillars: "vertical model training," "evidence credibility," and "clinical usability."
Currently, with the widespread adoption of large AI models, an increasing number of AI companies are pursuing general-purpose models with massive parameter scales. Notably, although OpenEvidence was founded in 2022, amidst the wave of general-purpose large language models spurred by ChatGPT, it took a contrarian approach. In 2023, OpenEvidence published the paper “Do We Still Need Clinical Language Models?” which elaborates on the underlying rationale that specially trained models with 7 billion parameters outperform general-purpose models with trillions of parameters in high-precision domains such as healthcare.
In August 2025, OpenEvidence achieved a milestone breakthrough by scoring 100% on the United States Medical Licensing Examination (USMLE), accurately answering all 325 questions and providing correct references. This performance surpassed ChatGPT-5, making it the first AI system in history to achieve a perfect score on this exam. Such results undoubtedly serve as the strongest endorsement of its model methodology.
In terms of "evidence credibility," OpenEvidence chooses to train its large language models using peer-reviewed data from authoritative public sources such as PubMed and Cochrane, while refraining from scraping content from the public internet to minimize errors. Meanwhile, to address the issue of AI "hallucinations," it requires that every output conclusion be strongly linked to specific passages from at least two high-quality publications, thereby ensuring traceable conclusions and verifiable evidence.
Meanwhile, when using OpenEvidence, physicians can directly view the sources of the answers, meaning that OpenEvidence directs traffic back to the original databases. This very mechanism has secured an exclusive partnership with the *New England Journal of Medicine* (NEJM), one of the top medical journals worldwide, granting OpenEvidence full-text training rights and enabling near real-time updates to its knowledge base, while also driving significant traffic to the journal. Physicians gain access to reliable content, professional journals receive increased visibility, and OpenEvidence enhances model accuracy through authoritative content, thereby creating a virtuous cycle.
Schematic Diagram of the OpenEvidence Architecture, Compiled and Drawn Based on Public Information
In terms of “clinical usability,” OpenEvidence is designed around the entire clinical decision-making workflow. Real-world testing at the Mayo Clinic demonstrated that the system reduced the time required to manage complex cases by 40%, lowered the misdiagnosis rate by 35%, and improved diagnostic consistency by 68% particularly in multidisciplinary tumor board consultations. In emergency departments, the system increased triage accuracy to 92%, significantly reducing both misdiagnosis and missed diagnosis rates. Its performance was even more pronounced in rare disease diagnosis: for 121 rare conditions, its identification accuracy exceeded that of a panel of specialists by 15.7 percentage points, with an average decision-making time just one-eighth that of human experts.
In terms of the product interface, the design prioritizes physicians’ workflows, centering on the core principle of evidence traceability. Every response is annotated with cross-reference numbers, and a complete list of references is appended at the end to facilitate verification by physicians. Meanwhile, a dual-mode response mechanism is adopted for queries: the “Clinical Evidence” mode focuses on presenting supporting evidence and literature reviews, while the “Nursing Guidelines” mode provides direct operational recommendations.
Overall, OpenEvidence has successfully built a moat, establishing competitive barriers that are difficult to replicate in the short term.
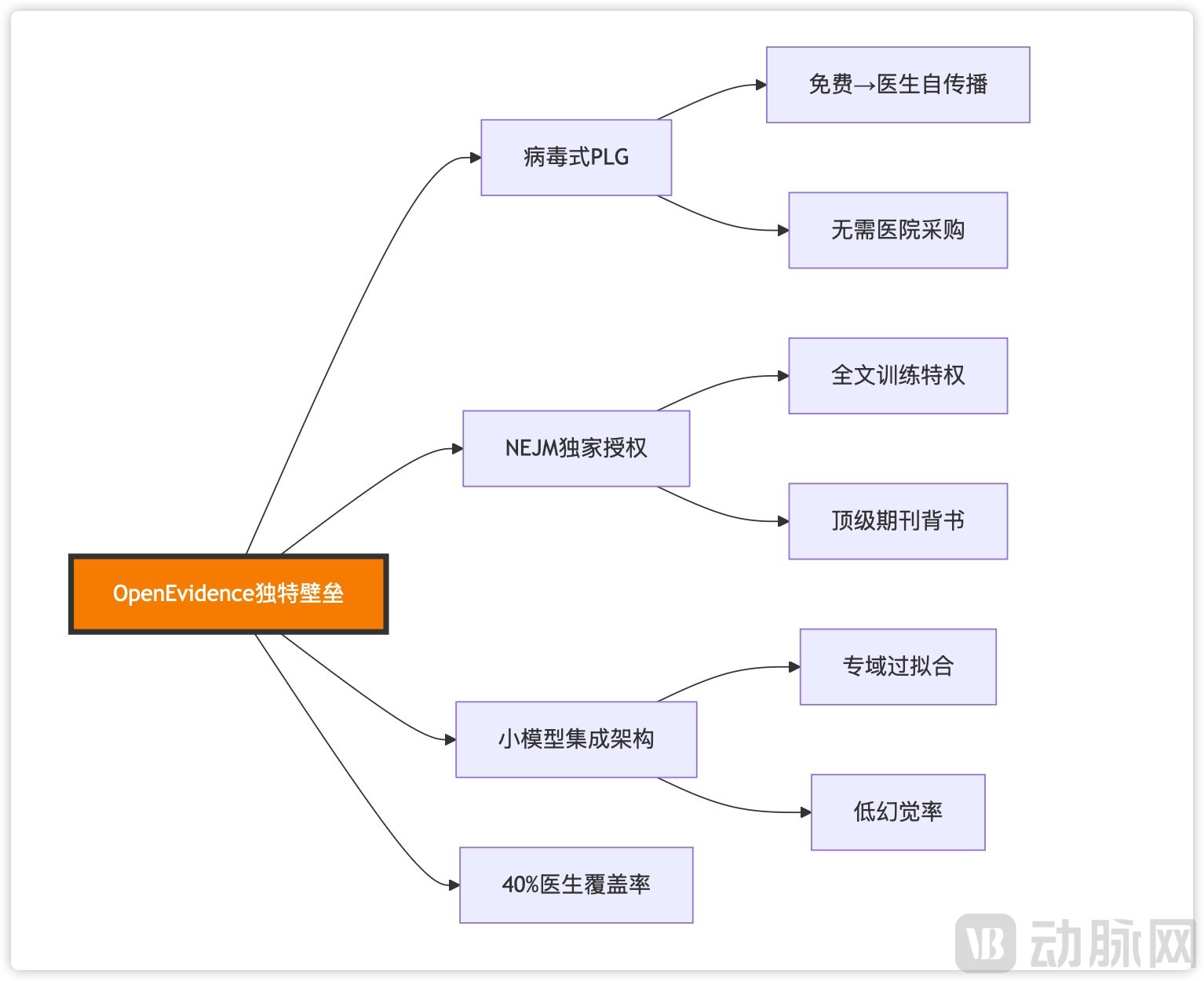
First, exclusive authorization of authoritative content constitutes its core competitive barrier. It is not only the sole AI tool with full-text indexing rights for NEJM and JAMA, but has also partnered with multiple top-tier global medical societies to access authoritative structured data. In contrast, general-purpose AI models can only retrieve literature abstracts, making their content depth and completeness incomparable.
Secondly, the real-world query data generated by 400,000 active physicians—including specific case details, medication inquiries, and guideline-related ambiguities—can serve as golden data for model optimization after de-identification. Meanwhile, the profound accumulation in the field of medical natural language processing, including specialized optimizations for medical entity recognition and relation extraction, clinical context understanding and query intent recognition, as well as evidence quality assessment and ranking algorithms, cannot be replicated overnight.
Finally, there is brand trust. Currently, OpenEvidence covers more than 40% of licensed physicians in the United States, and its extensive user base reflects doctors’ recognition of its accuracy and reliability. A cardiologist at Stanford Hospital stated, “Whenever I doubt OpenEvidence’s answers, I verify them against the original literature, and in most cases, the information it provides is accurate and well-cited. This kind of trust takes time to build, but once established, it becomes a powerful competitive advantage.”
A “Google-style” business loop featuring free user access and ad-based monetization.
When discussing OpenEvidence’s business model, it is essential to mention the background of its founder, Daniel Nadler. Nadler earned a Ph.D. in Economics from Harvard University. In 2013, he founded Kensho, a financial AI company that developed an intelligent system capable of analyzing the impact of financial events on markets in real time. Kensho was later acquired by S&P Global for $550 million. Subsequently, Nadler co-founded OpenEvidence with Zachary Ziegler, who holds a D.Phil. in Computer Science from the University of Oxford.
As a finance major, the founder naturally understands the importance of an efficient business model to an enterprise.
For traditional medical AI software systems to enter hospitals, they must navigate lengthy procurement processes. In the United States, it takes at least two years to go from evaluation to procurement for a hospital information system. Additionally, these systems must meet the FDA’s stringent approval requirements, and the approval process itself is quite protracted.
Therefore, OpenEvidence chose to bypass these obstacles, efficiently capturing users while iterating rapidly. First, it positioned itself as a medical information retrieval tool rather than a diagnostic device requiring approval, thereby avoiding the need for FDA clearance.
Secondly, it bypasses hospital procurement departments to provide free services directly to individual physicians. Users verified through the NPI (National Provider Identifier) or equivalent medical licensing credentials in other countries can access basic features at no cost. For core services such as literature search, guideline queries, and case analysis, physicians need only register with an email address. This streamlined process is fast and efficient, significantly reducing the decision-making burden for doctors. Meanwhile, its exceptional user experience and free-access policy have driven rapid, viral growth within the medical community through word-of-mouth.
Finally, there is scenario-based precision advertising targeting the physician user base. In the past, multinational corporations (MNCs) such as Eli Lilly, Pfizer, and Roche relied on broad-reach promotional strategies through medical representatives, academic conferences, or professional journals for their marketing budgets. Today, OpenEvidence provides these MNCs with a channel to precisely deliver product information to physicians in relevant specialties.
For example, when an oncologist searches for “PD-1 inhibitors,” the platform pushes Phase III clinical trial results of relevant drugs. All promotional content is reviewed by the platform’s clinical experts to ensure compliance with clinical guidelines. Meanwhile, advertisements and the answer system are physically separated in the user interface to avoid interfering with physicians’ clinical judgment. For advertisers, digital advertising enables precise tracking of impressions, click-through rates, and subsequent prescribing behaviors, thereby clearly demonstrating return on investment (ROI) data.
Currently, OpenEvidence’s annual advertising revenue has exceeded $50 million, with approximately $400 million in advertising inventory on hand that is expected to be further converted into revenue in the future. Moreover, thanks to its digital delivery model, the company boasts a gross margin of over 90%, far surpassing the average level for AI startups.
While most AI startups rely on financing to survive, OpenEvidence has already established a viable profitability model, with a 90% gross margin demonstrating its strong monetization capabilities. In the medium to long term, it can further expand through technology integration by offering customized API interface services tailored to hospitals, medical schools, and pharmaceutical companies, thereby diversifying its revenue streams.
The unique characteristics of the Chinese market have led to divergent development paths.
There are also many AI-based evidence-driven decision support tools positioned for physicians in China, which share the same core objectives as OpenEvidence.
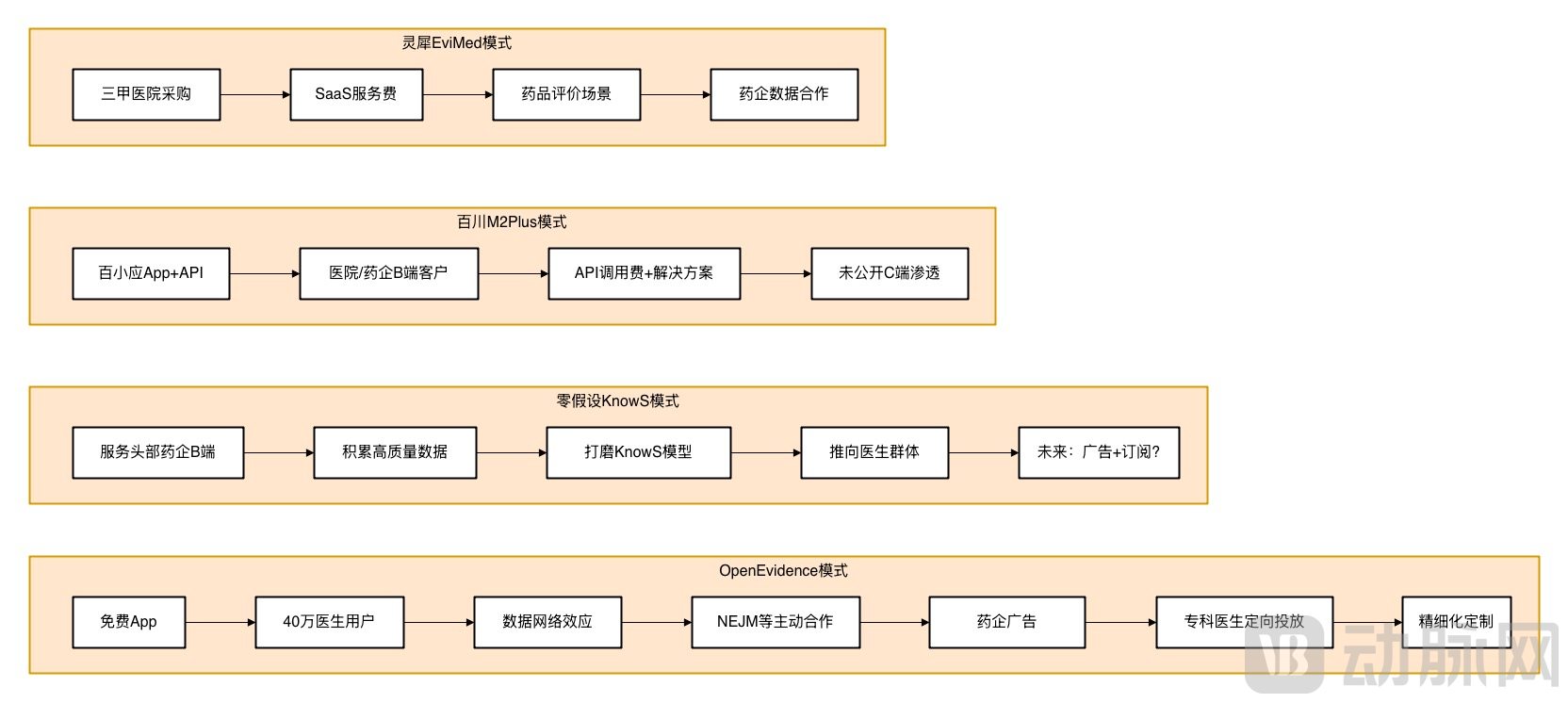
For example, Shanghai Null Hypothesis Information Technology Co., Ltd. (hereinafter referred to as “Null Hypothesis”), established in 2019, specializes in the development of intelligent medical products. Its “KnowS” product series is a virtual medical assistant that integrates data technology with medical expertise to provide physicians with research solutions centered on literature analysis and clinical data analysis, thereby facilitating medical research and innovation.
Additionally, BAICHUAN AI has developed M2Plus, an evidence-enhanced large medical model. By employing an innovative six-source evidence-based reasoning paradigm, M2Plus encompasses a comprehensive knowledge system ranging from basic research to real-world clinical feedback. This approach significantly improves the accuracy and reliability of medical knowledge while substantially reducing the rate of medical "hallucinations." When generating responses, M2Plus also incorporates an evidence-enhanced training mechanism to ensure that it cites authoritative sources rather than producing arbitrary content.
Lingxi Medical’s independently developed “EviMed Intelligent Evidence-Based Analysis Engine” dynamically integrates hundreds of millions of global medical literature records, clinical trial data, and real-world evidence to construct an evidence chain network covering the entire disease lifecycle. It not only tracks the latest medical advances in real time but also automatically resolves evidence conflicts through multimodal evidence fusion and causal reasoning algorithms, providing trustworthy decision support for physicians and researchers and achieving “zero-hallucination” precise search and reasoning.
DingTalk and Testing OneLife Jointly Launch “Doukou Doctor Super Assistant,” the First Professional AI Application for Physicians on DingTalkCapable of integrating over 40 million global medical professional literature sources within one minute with full-chain traceability, the application leverages authoritative medical research evidence to support high-complexity clinical scenarios such as prenatal diagnosis and gynecologic oncology. Obstetricians and gynecologists need only submit patient cases; the AI then intelligently retrieves information from professional guidelines and literature to generate a complete evidence chain comprising “guideline recommendations + real-world data + similar cases,” and produces diagnostic and treatment recommendations within one minute.
Also positioned as “the most convenient clinical decision-making tool for physicians,” the Yidu Clinical Copilot deeply integrates a healthcare-specific large language model, a dynamic evidence-based knowledge system, and in-hospital patient data. It addresses AI “hallucinations” through evidence-based validation, enabling one-click tracing to top-tier evidence to ensure accuracy. Furthermore, it automatically interfaces with patient data, seamlessly linking medical evidence with individualized clinical conditions to directly provide actionable diagnosis and treatment strategies, thereby eliminating cumbersome steps. The Copilot is available in both desktop versions integrated into physician workstations and mobile applications, facilitating use by doctors in various settings such as ward rounds and remote access from home.
Unlike OpenEvidence’s free strategy, domestic products generally adopt a paid model. For instance, “KnowS” employs a business model that initially targets leading pharmaceutical companies and focuses on medical scientific research. Through the provision of paid services, it accumulates high-quality annotated data and iteratively improves its algorithmic models, before launching its mature to-C “KnowS” model and agents to the physician community. EviMed has similarly adopted a to-B paid model. Currently, the EviMed platform is being piloted in over 100 Grade A tertiary hospitals across China, assisting in comprehensive evaluation projects covering areas such as cardiovascular drugs, anti-infective agents, and rheumatology and immunology.
Schematic Diagram of Business Model, Compiled and Drawn Based on Public Information
From a product perspective, Chinese-developed large language models (LLMs) each follow their own logical frameworks. BAICHUAN AI has adopted a path combining LLMs with medical retrieval-augmented generation (RAG) optimization, using evidence-based medicine as a constraint layer, which reflects its strong confidence in the capabilities of its LLMs. In contrast, Zero Hypothesis has chosen a strategy opposite to that of OpenEvidence: it first serves pharmaceutical companies, which have extremely high professional requirements, and only after accumulating sufficient data does it expand to serve physicians. This approach is driven by the reality in China that physicians face higher workloads and have lower tolerance for errors. Additionally, several other products are designed around existing hospital workflows, with the primary consideration being how to rapidly integrate into the current operational model of healthcare informatization in China.
The success of OpenEvidence is fundamentally rooted in the fact that physicians in the United States are independent decision-makers who can autonomously download apps and exhibit consumer-grade product usage habits. In contrast, physicians in China practice within the public hospital system, where tool procurement requires institutional approval, making it difficult for free individual tools to penetrate core clinical workflows. Therefore, whether pursuing a B2B strategy by integrating with hospital systems or offering API solutions, the focus remains on engaging the institutional system rather than individual practitioners.
Zhang Shichen stated that the true launch of the domestically produced OpenEvidence requires a cohort of active physician users. The product that can more rapidly gain recognition and support from the medical community will be better positioned to establish itself in this field; relying solely on growth in the number of general users is far from sufficient.

On the other hand, OpenEvidence initially leveraged public data from the FDA and CDC, and later secured proactive licensing from the NEJM, essentially reflecting content providers’ recognition of its user value. Although domestic products have made significant efforts to enhance data quality, they still lack authoritative endorsement comparable to that of the NEJM. Furthermore, the viral spread of OpenEvidence is fundamentally driven by product-led growth (PLG), whereas domestic products are primarily B2B-oriented, making it difficult to achieve the exponential growth seen with OpenEvidence.
Therefore, some of OpenEvidence's unique barriers have not yet been established by domestic products.
OpenEvidence’s Competitive Moat, Compiled from Public Information
For instance, OpenEvidence’s product-led growth model relies on a virtuous cycle of organic physician adoption → data optimization → enhanced user experience → word-of-mouth referrals reaching more physicians, thereby reducing sales expenses. In terms of its content moat, the proactive collaboration with the *New England Journal of Medicine* (*NEJM*) has built brand trust that no amount of paid promotion can buy, while partnerships with multiple top-tier journals to co-create business models have resolved data copyright issues. Furthermore, its technical strategy takes a contrarian approach by persisting with small language models in an era obsessed with scaling parameters, thereby achieving higher accuracy in specialized domains.
These competitive barriers established by such strategies are equally instructive for domestically produced medical AI models. If Chinese AI medical models can successfully navigate copyright and business model challenges, why should they not expand overseas to compete?
Overall, it is unlikely that an exact Chinese counterpart to OpenEvidence will emerge in the short term, due to differences in the underlying healthcare ecosystem. However, as domestic large AI models are adopted by B-end users, they will accumulate sufficient data and refine their products through collaboration. This could enable a breakthrough in the C-end market within three to five years, at which point they may replicate some of OpenEvidence’s success.
The essence of competition in medical AI lies in data and trust. Its emergence is not meant to replace physicians, but to rejuvenate the Hippocratic Oath in the age of algorithms. Whether it is OpenEvidence or Chinese-developed large language models, all are undergoing a transformation from information retrieval tools into central hubs of the healthcare ecosystem. These vertical AI sectors will continue to evolve based on the principles of “trust first” and “scenario supremacy.”