Chinese Team Completes Multicenter Clinical Validation of Medical AI Platform CC-Cruiser, Featured on The Lancet Digital Health Cover

Zhongshan Ophthalmic Center
Ophthalmology Specialty Hospital
In certain specific disease categories, AI performance is increasingly surpassing that of physicians. However, many medical AI products remain in the research, development, and experimental training phases. In actual comparative trials, the effectiveness of medical AI in disease diagnosis and treatment decision-making has not yet been evaluated using large-scale, unfiltered clinical data. This raises questions about how AI will perform when deployed in real-world clinical applications.
Leiphone(WeChat Official Account: Leifeng.com)It is understood that,Recently, the ophthalmic artificial intelligence team led by Liu Yizhi and Lin Haotian from the Zhongshan Ophthalmic Center, Sun Yat-sen University, completed the latest clinical multicenter randomized controlled trial to compare the clinical differences between CC-Cruiser and physicians in traditional ophthalmology clinics. This paper was published as a cover article in the latest issue (March 2019) of EClinicalMedicine (ECM), a subsidiary journal of the globally authoritative medical journal The Lancet.
CC-Cruiser is an “Artificial Intelligence Diagnostic Decision-Making Platform for Congenital Cataracts” developed using deep learning by the Medical Artificial Intelligence Team at the Zhongshan Ophthalmic Center, Sun Yat-sen University (ZOC). This collaborative cloud platform supports patient data sharing among individual hospitals for data integration and patient screening. The training dataset employed by CC-Cruiser comprises 410 images of pediatric cataract eyes and 476 images of normal eyes, sourced from the Chinese Ministry of Health’s Pediatric Cataract Project (CCPMOH) at the National Clinical Research Center for Rare Diseases.
Background:CC-Cruiser is an artificial intelligence platform designed for diagnosing pediatric cataracts and providing risk stratification and treatment recommendations. The high accuracy of CC-Cruiser was previously validated on specific datasets. The aim of this study was to compare the diagnostic performance and treatment decision-making capabilities of CC-Cruiser and ophthalmologists in real-world clinical settings.
Methods:This multicenter randomized controlled trial was conducted at five ophthalmology outpatient clinics across different regions of China. Pediatric patients (aged ≤14 years) without a diagnosis of cataracts or a history of prior ophthalmic surgery were randomly assigned (1:1) to receive either the CC-Cruiser assessment or diagnostic and treatment recommendations from ophthalmologists with more than five years of clinical experience in pediatric ophthalmology. The experts providing the gold-standard reference, as well as the researchers performing slit-lamp photography and data analysis, were blinded to group allocation.
The primary outcome was the diagnosis of pediatric cataracts based on expert consensus standards for cataract specialists. Secondary outcomes included assessments of disease severity and treatment determination, time required for diagnosis, and patient satisfaction, which was determined by mean scores. This trial has been registered at ClinicalTrials.gov (NCT03240848).
Findings:Between August 9, 2017, and May 25, 2018, 350 participants (700 eyes) were randomly assigned to undergo diagnosis by either the CC-Cruiser system (350 eyes) or ophthalmologists (350 eyes). The accuracy rates of the CC-Cruiser for cataract diagnosis and treatment determination were 87.4% and 70.8%, respectively, which were significantly lower than the 99.1% and 96.7% achieved by ophthalmologists (p<0.001, OR = 0.06 [95% CI 0.02–0.19]; p<0.001, OR = 0.08 [95% CI 0.03–0.25]). The mean diagnostic time for the CC-Cruiser was 2.79 minutes, significantly shorter than the 8.53 minutes required by ophthalmologists (p<0.001; mean difference 5.74 [95% CI 5.43–6.05]). Patients expressed satisfaction with the overall quality of medical care provided by the CC-Cruiser, which demonstrated time-saving advantages in cataract diagnosis.
Explanation:Compared with ophthalmologists, CC-Cruiser is less accurate in diagnosing pediatric cataracts and making treatment decisions. However, the medical services provided by CC-Cruiser require less time and have achieved a high level of patient satisfaction. CC-Cruiser has the capacity to assist human physicians in its current clinical practice.
This was a large, multicenter, parallel-group, randomized controlled trial conducted at five ophthalmic clinics in China. Our study adhered to the Consolidated Standards of Reporting Trials (CONSORT) guidelines. The primary research center for the trial was the Zhongshan Ophthalmic Center, Sun Yat-sen University. The other four participating clinics were the Shenzhen Eye Hospital, Wuhan Central Hospital, the Second Affiliated Hospital of Fujian Medical University, and Kaifeng Eye Hospital.We selected these partner hospitals from different regions to represent the diversity of healthcare environments across China.
Researchers recruited participants based on the inclusion criteria of the ophthalmology clinics at these hospitals. Participants were eligible for the study if they were under 14 years of age, presented with or without ocular symptoms, and had no prior history of ophthalmic surgery. All participants underwent slit-lamp photography, with sedatives such as chloral hydrate administered when necessary. Patients with a confirmed diagnosis of cataracts, other normal ocular conditions, or ocular trauma were excluded.
Written informed consent was obtained from at least one parent or guardian of each participating child at enrollment, and the principles of the Declaration of Helsinki were followed throughout the study. The study protocol was approved by the Ethics Committee of Zhongshan Ophthalmic Center (ZOC) and the Institutional Review Boards of all collaborating centers, including Shenzhen Eye Hospital, Wuhan Central Hospital, the Second Affiliated Hospital of Fujian Medical University, and Kaifeng Eye Hospital. The trial is registered with ClinicalTrials.gov (NCT03240848).
2.2 Randomization and Blinding
Participants were randomly assigned (1:1) to receive diagnosis via the CC-Cruiser system or by ophthalmologists, with both eyes of each participant assigned to the same group. Centralized randomization was performed using a random number generation program without stratification factors to avoid selection bias. Investigators at each study center assessed patient eligibility. If a patient met the inclusion criteria, the investigator transmitted the patient’s information to the study coordinator, who then notified the investigator of the assigned group. Slit-lamp photography and patient recruitment were conducted at each participating clinic by trained clinical staff. To prevent confirmation bias, clinical staff, investigators involved in data management and analysis, and experts providing the gold-standard diagnosis at each clinic were blinded to group assignment. However, study participants, ophthalmologists, study coordinators, and investigators responsible for randomization were not blinded to the allocation information.
2.3 Protocol
The CC-Cruiser platform of the ZOC Pediatric Cataract Center is connected via the internet to all collaborating clinics. A CC-Cruiser website (https://www.cc-cruiser.com/version1) has been established, containing instructional videos with guidelines and explanations. Registered users can upload new cases to CC-Cruiser, and the output results include: diagnosis (normal lens versus cataract), comprehensive assessment (opacity area, density, and location), and treatment recommendations (surgery versus follow-up). Ophthalmologists with at least five years of clinical experience in pediatric ophthalmology provide preliminary diagnoses at each center. Investigators created a profile for each eligible participant who provided consent, recording their demographic information and baseline clinical characteristics, including sex, date of birth, family history of cataracts, and ocular symptoms. Participating investigators and clinical staff at each center received standardized training on study procedures prior to the trial. All eligible participants underwent slit-lamp photography with pupillary dilation before group assignment, using diffuse light as the single standard, with appropriate slit-lamp illumination intensity and uniform eye positioning. Clinical staff attempted no more than three times per eye. Researchers administered sedatives (chloral hydrate) to 43 very young patients who would otherwise have been uncooperative during the examination.
Participants in the AI group were assigned to the AI clinic after slit-lamp photography. Researchers sent images of the anterior segment to CC-Cruiser for preliminary diagnosis (normal lens versus cataract) and comprehensive assessment of disease severity (lens opacity and area, density, and location of opacities), and provided treatment recommendations (surgery versus follow-up). Researchers calculated the time required to access CC-Cruiser and receive the preliminary diagnosis. Participants in the ophthalmologist group were assigned to the routine ophthalmology clinic. Ophthalmologists provided patients with preliminary diagnostic reports, including disease severity and treatment decisions. Researchers also calculated the time required for the diagnostic process.
Following the initial diagnosis, all participants with identifiable IDs underwent a gold-standard diagnosis by an expert panel comprising three cataract specialists, each with over 10 years of clinical experience in ophthalmology. The expert panel conducted slit-lamp examinations and reached a consensus to establish the final diagnosis and treatment plan for each patient. After the initial diagnosis report and the gold-standard diagnosis, participants and their guardians were asked to complete a questionnaire assessing their satisfaction with the accuracy and efficiency of the diagnostic process.
2.4 Results
The primary outcome was the accuracy of diagnosing normal lenses versus cataracts.As there is no international classification system available for pediatric cataracts, the reference standard for assessing pediatric cataracts is the diagnosis by cataract specialists.Researchers compared the diagnostic accuracy of CC-Cruiser with that of ophthalmologists, using the gold-standard diagnoses established by cataract specialists as the reference. Secondary outcomes included assessment of disease severity, time required for diagnosis, and patient satisfaction. Disease severity was comprehensively evaluated based on the extent of opacification (extensive vs. limited), density (dense vs. non-dense), location (central vs. peripheral), and treatment recommendations (surgery vs. follow-up).
When the opacity covers more than 50% of the pupil, the opacity area is defined as extensive; otherwise, it is defined as limited. When the opacity completely obscures fundus imaging, the opacity density is defined as dense; otherwise, it is defined as non-dense. When the opacity completely covers the visual axis region, the opacity location is defined as central; otherwise, it is defined as peripheral.
Since the diagnosis is based on slit-lamp images of the anterior segment, the time required for diagnosis spans from image acquisition to the completion of the initial diagnostic report and treatment recommendations by either CC-Cruiser or an ophthalmologist.Patient satisfaction was assessed and analyzed using a seven-item questionnaire. Scores were assigned as follows: 1 indicated disagreement, 2 indicated neutrality, 3 indicated agreement, and 4 indicated strong agreement. The number and percentage of participants for each item were recorded, and the mean rating for each item was calculated.
2.5 Statistical Analysis
Based on data from the comparative study of CC-Cruiser, we calculated that a sample size of at least 700 eyes (assuming a 1:1 allocation ratio, with 350 eyes per group) is required to compare the diagnostic accuracy between CC-Cruiser and ophthalmologists. The expected accuracy for the AI-driven outpatient clinic using CC-Cruiser is 90%, while the expected accuracy for the ophthalmologist-led outpatient clinic is 95%, with a statistical power of 80% and a significance level of 5%.
The study analysis adhered to a comprehensive, pre-specified statistical analysis plan. Demographic and clinical data were recorded at baseline. Statistical analyses of baseline demographic and disease characteristics were conducted to confirm that all 350 participants (700 eyes) were randomized into two study groups. As no patients discontinued or withdrew from treatment after enrollment, the per-protocol population was identical to the intention-to-treat population. Consequently, our primary analysis included all patients as initially randomized. Diagnostic accuracy was analyzed at the eye level, with both eyes of the same individual analyzed separately within the same group.
We calculated the sensitivity, specificity, accuracy, positive predictive value (PPV), and negative predictive value (NPV) of CC-Cruiser and ophthalmologists using the gold standard (cataract specialists). The correct diagnosis of cataracts was further analyzed through a comprehensive assessment of disease severity and treatment recommendations. The generalized estimating equation (GEE) method, an extension of quasi-likelihood methods, is increasingly used to analyze longitudinal and other correlated data, particularly when they follow a binomial distribution or are in count form.
Data from both eyes of each participant were included; as these data are correlated, generalized estimating equations (GEE) were employed to determine significant differences in accuracy, true positive fraction (TPF), and false positive fraction (FPF) between CC-Cruiser and ophthalmologists. TPF is equivalent to sensitivity, and FPF is equivalent to 1 − specificity. The time required by CC-Cruiser and ophthalmologists was assessed using the Mann–Whitney U test. Patient satisfaction with medical services was calculated as mean ratings with standard deviations. The Mann–Whitney U test was performed to determine significant differences in responses to each question between the two groups. The significance level was set at α = 0.05. For all models, results were expressed as effect size estimates in terms of odds ratios (ORs), 95% confidence intervals, and p-values. All statistical analyses were conducted using SPSS (version 20; SPSS, Inc., Chicago, IL, USA).
Between August 9, 2017, and May 25, 2018, 353 patients were screened for eligibility (Figure 1). After screening, three very young children were excluded because they could not tolerate chloral hydrate or undergo slit-lamp photography. The remaining 350 participants (700 eyes) were randomly assigned to either the AI group (350 eyes) or the ophthalmologist group (350 eyes). No participants withdrew from the study after randomization. The study ultimately included 350 participants (700 eyes). Baseline demographic and disease characteristics—including sex, age, family history, ocular symptoms, presence of cataracts, and cataract severity—were comparable between the two groups (Table 1).
According to the standards of cataract experts, the sensitivity, specificity, accuracy, positive predictive value (PPV), and negative predictive value (NPV) of the diagnosis were 89.7%, 86.4%, 87.4%, 74.4%, and 95.0%, respectively. For CC-Cruiser, these metrics were 98.4%, 99.6%, 99.1%, 99.2%, and 99.1%, respectively (Table 2). The diagnostic accuracy and true positive fraction (TPF) of CC-Cruiser for pediatric cataracts were significantly lower (p < 0.001, OR = 0.06 [95% CI 0.02–0.19]; and p = 0.012, OR = 0.14 [95% CI 0.03–0.65]), while the false positive fraction (FPF) of CC-Cruiser was significantly higher than that of ophthalmologists (p < 0.001, OR = 43.05 [95% CI 5.42–341.70]) (Table 2). The accuracy of CC-Cruiser in diagnosing cataracts was significantly lower than that of ophthalmologists. The correct rates for comprehensive evaluation of lens opacity area, density, and location were 90.6%, 80.2%, and 77.1%, respectively, compared with 93.3%, 85.0%, and 87.5% in the ophthalmologist group (Table 3).
Compared with ophthalmologists, CC-Cruiser showed no statistically significant differences in assessing the area, density, and location of opacities (p = 0.463, 0.286, and 0.130, respectively) (Table 3). The treatment recommendations (surgery vs. follow-up) provided by CC-Cruiser were significantly inferior to those provided by ophthalmologists (70.8% vs. 96.7%, p < 0.001, OR = 0.08 [95% CI 0.03–0.25], Table 3).
CC-Cruiser required less time to propose diagnostic and treatment recommendations than ophthalmologists did (2.79 minutes vs. 8.53 minutes, p<0.001; mean difference 5.74 [95% CI 5.43 to 6.05]; Table 4).
At the end of the study, 345 participants completed the assessment questionnaires (172 in the CC-Cruiser group and 173 in the ophthalmologist group). Due to personal reasons, the guardians of five participants did not complete the questionnaires. Table 5 summarizes the questionnaire data. The response rates for the completed questionnaires were 98.3% in the AI group and 98.9% in the ophthalmologist group.Patients reported high satisfaction with the medical services provided by CC-Cruiser, particularly regarding the time required for diagnosis. The mean overall satisfaction score for CC-Cruiser was 3.47 ± 0.501, which was higher than that for ophthalmologists (3.38 ± 0.554; p = 0.007; Table 5), indicating that patients preferred AI over actual physicians when receiving medical services.
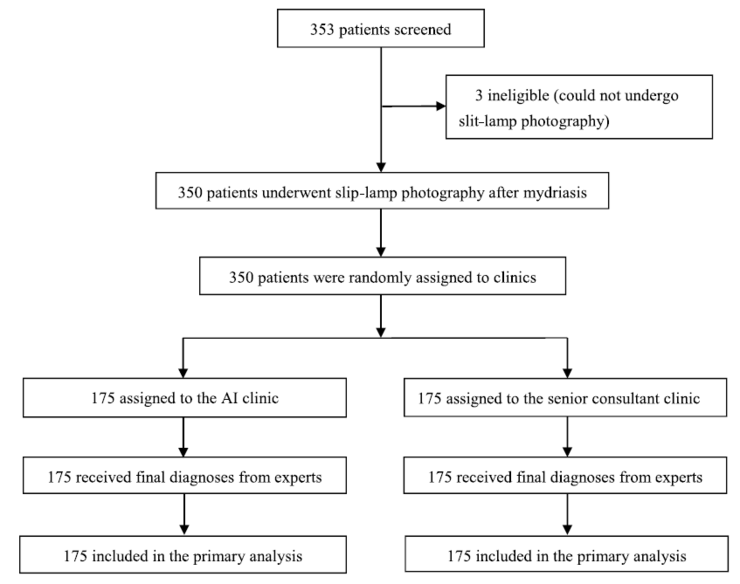
Figure 1. Experimental Grouping
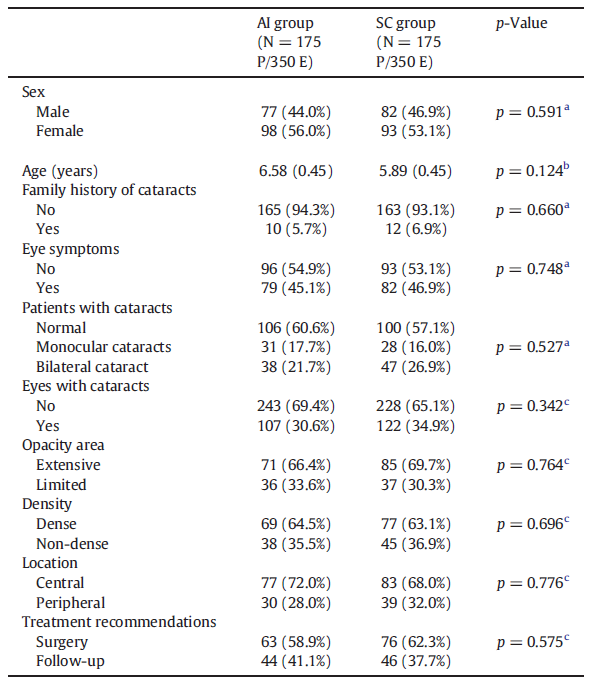
Table 1: Baseline Demographics and Disease Characteristics

Table 2: Diagnostic Manifestations of Pediatric Cataracts;Using the eye as the unit of analysis (N=700), there were 350 eyes in the CC-Cruiser group and 350 eyes in the ophthalmologist group.
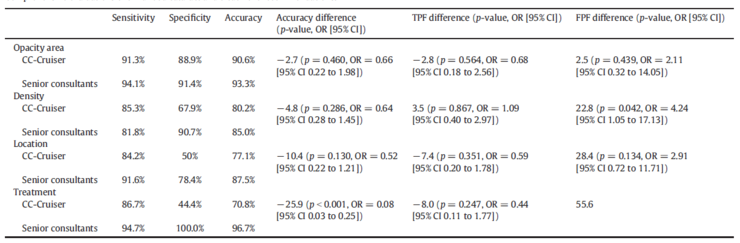
Table 3: Comprehensive Evaluation and Treatment Recommendations for Pediatric Cataracts
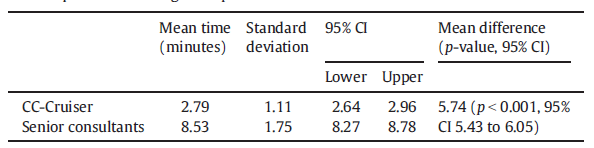
Table 4: Time required for the diagnostic processes of CC-Cruiser and ophthalmologists;The analysis included 300 patients (175 in the CC-Cruiser group and 175 in the ophthalmologist group). A Mann–Whitney U test revealed a significant difference in the time required between the CC-Cruiser and the ophthalmologists.
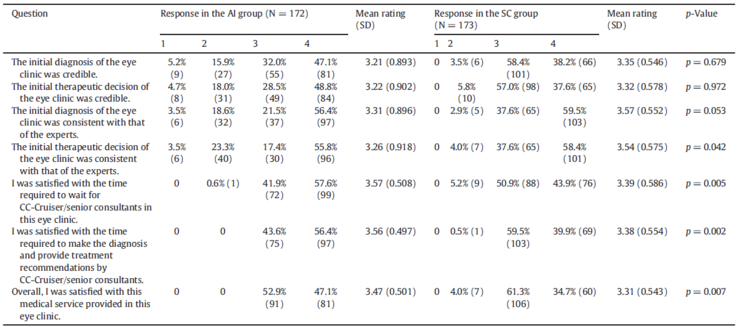
Table 5: Responses of questionnaire participants to clinical services
In this study, we found that CC-Cruiser was less accurate than ophthalmologists in diagnosing pediatric cataracts and making clinical treatment decisions. However, compared with ophthalmologists, CC-Cruiser required shorter diagnostic time and achieved higher patient satisfaction. These findings highlight the importance of evaluating the clinical performance of CC-Cruiser through randomized controlled trials before its routine use in outpatient settings.
The actual diagnostic accuracy of CC-Cruiser was lower than that reported in our previous studies using screening datasets.Although CC-Cruiser demonstrated high accuracy in evaluating 306 standard images of the anterior segment, its misdiagnosis and assessment of 43 cases of poor-quality cataracts were often less accurate than those by ophthalmologists, which can be attributed to several reasons:
First, due to photophobia or lack of attention, some pediatric patients are unable to cooperate adequately and fixate their eyes on the camera. Consequently, the slit lamp cannot focus properly on the lens.
Secondly, the eyelids and eyelashes may cause occlusion, thereby affecting the quality of the captured images.
Third, if the reflection point is focused near the visual axis, the features of the lens reflection point cannot be accurately extracted, leading to misdiagnosis of cataracts by CC-Cruiser and a high false-positive rate.
Fourth, the intense illumination from the slit lamp may induce lens opacification, which is another reason for the high false-positive rate of CC-Cruiser.
However, these issues can typically be identified by ophthalmologists, as they can manually adjust the focus and assess opacities from different positions or angles. A higher rate of false positives may increase the burden on medical resources and costs, and could potentially lead to physical or psychological harm to patients.
Furthermore,Although the diagnosis using CC-Cruiser at this stage may still require clinician intervention (including the use of sedatives) to ensure the quality of image acquisition, we believe that further improvements in medical AI auto-focusing technology will achieve higher diagnostic accuracy and reduced human intervention.For example, improvements in the identification of lens reflection points can significantly reduce the false positive rate.
Previous studies have demonstrated that AI-assisted diagnosis can reduce physicians’ workload and provide high-quality medical services to patients in need. Here, we show that in clinical practice, a medical AI platform outperforms human physicians in reducing diagnostic time. Participants in the CC-Cruiser group consistently perceived faster diagnoses, with a significant reduction in waiting time for diagnosis.
Patient satisfaction with medical AI has not been adequately studied. Laure et al. used the electronic health website Sanoia to assess patient satisfaction with rheumatoid arthritis (RA) care. The authors demonstrated that researchers found patient satisfaction to be inconsistent with the use of the AI platform, primarily because RA is a chronic condition; during periods of remission, patients may lose interest in using Sanoia and reduce their engagement in self-management of the disease.
However, without early diagnosis and appropriate treatment, pediatric cataracts can pose a threat to vision. Therefore, parents of pediatric patients urgently seek medical services to facilitate efficient diagnostic and therapeutic decision-making.
Our study indicates that patients’ overall satisfaction with CC-Cruiser was slightly higher than that of ophthalmologists, suggesting a favorable experience for patients when utilizing AI-driven medical services. This patient satisfaction may stem from their curiosity or interest in medical AI, or from a preference for healthcare services that offer shorter diagnostic times while maintaining acceptable accuracy, reflecting a trade-off between diagnostic precision and efficiency.
Therefore, the current version of CC-Cruiser has demonstrated its potential to assist human physicians in clinical applications. In future studies, we will focus on improving the accuracy of CC-Cruiser to enhance patient satisfaction.
The strengths of this study include its randomized, controlled design, large sample size, and data sourced from five ophthalmic clinics in China. However, our trial has some limitations.
First, since patients without symptoms such as blurred vision were less willing to participate in this study, we may have missed some patients with slight lens opacity. Therefore, the assessment of early cataracts by CC-Cruiser needs further improvement.
Secondly, the treatment recommendations provided by CC-Cruiser did not take into account the patient's general condition. Therefore, a small subset (6 cases) of the treatment recommendations provided by CC-Cruiser were inconsistent with those provided by experts, despite the accurate assessment of lens opacity. Further improvement in treatment decision-making capabilities requires consideration of non-ophthalmic factors, such as age and health status.
Third, our artificial intelligence system relies on computing power and internet accessibility; therefore, widespread application of CC-Cruiser in developing regions with unstable internet connectivity may face challenges. Nevertheless, remote areas with internet access can still benefit from the medical services provided by CC-Cruiser.
Fourth, a cluster randomized controlled trial (with clusters defined at the level of pediatric patients) was conducted in this study, as randomization was performed at the patient level while observations and analyses were conducted at the eye level. However, the design of the randomized controlled trial did not account for the intraclass correlation between the two eyes of the same child. This will result in statistical power lower than the anticipated 0.8, because cluster randomized controlled trials require larger sample sizes than standard randomized controlled trials to achieve the same statistical power.
In summary, this is the first clinical randomized controlled trial to validate the accuracy and effectiveness of an artificial intelligence system in ophthalmic clinical diagnosis. Compared with human ophthalmologists, CC-Cruiser demonstrated lower accuracy in diagnosing pediatric cataracts and making treatment decisions; however, in its current state, it has the capacity to assist human physicians in clinical practice. Further clinical controlled trials are needed to better evaluate the true diagnostic performance of medical AI.Leiphone Leiphone
Supplementary data for this article are available athttps://doi.org/10.1016/j.eclinm.2019.03.001Found.
Original article by Leiphone. Reproduction without authorization is prohibited. For details, seeReprint Guidelines。