AIDD Small Model Focusing on Clear Hard-Core Pain Points
01
How can current generative AI technology be integrated into the specific processes of drug development?
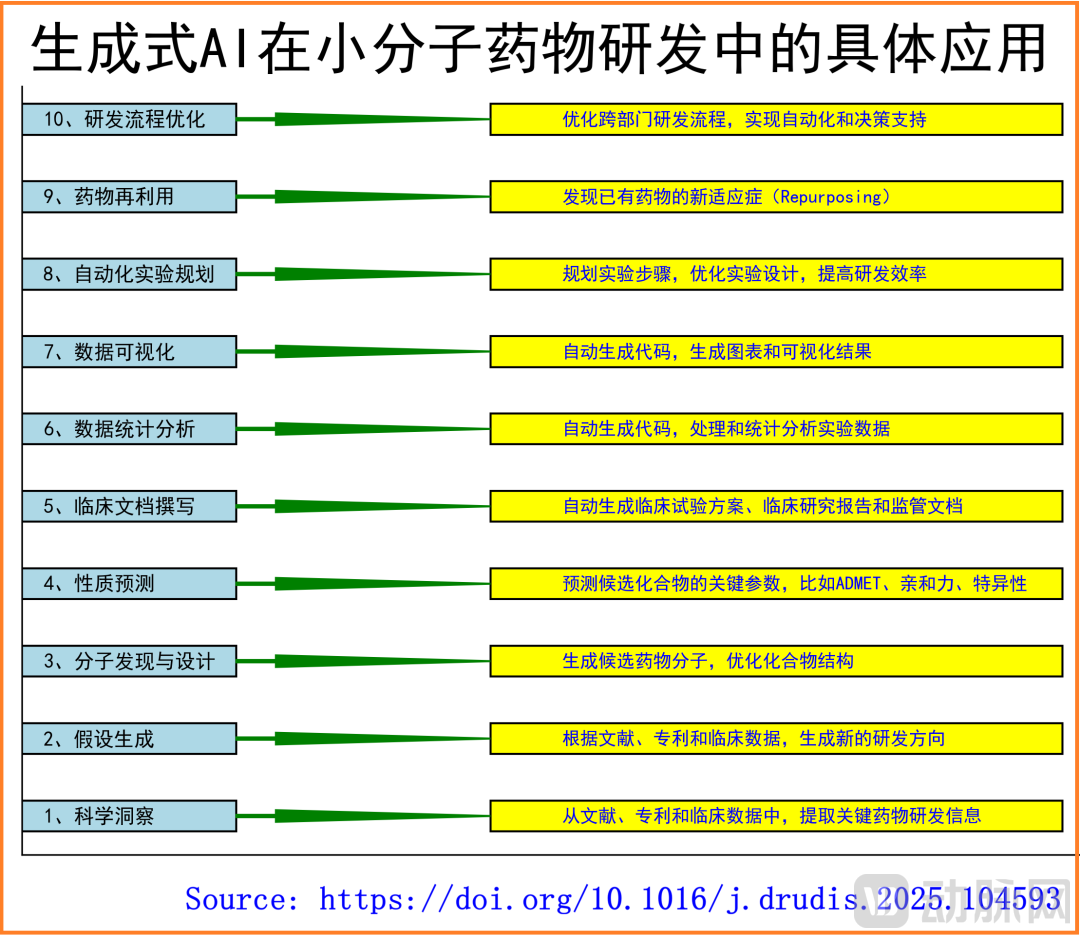
Taking small-molecule drugs as an example, generative AI is being integrated into multiple stages of the R&D process, including hypothesis generation, target discovery, drug design, preclinical research, clinical trials, and regulatory communication (as shown in the figure below). For instance, during the target discovery phase, researchers can use multi-omics data (such as gene expression, protein interaction networks, and clinical data) to train models and identify potential targets highly associated with diseases. Subsequently, in the lead compound discovery phase, AI models can generate candidate molecules with specific properties within a vast chemical space and predict their likelihood of binding to target proteins. Next, during the lead optimization phase, AI can simultaneously evaluate molecular ADMET properties such as activity, selectivity, solubility, metabolic stability, and toxicity (as shown in the figure below), rapidly proposing structural modification schemes through multi-objective optimization to reduce the costs of traditional iterative synthesis and screening. Additionally, molecular dynamics simulations (e.g., Schrödinger's IFD-MD workflow) and precise physical modeling can be combined with AI algorithms for more accurate computational predictions of protein-ligand interactions. Finally, before entering the preclinical research stage, AI can assist in predicting pharmacokinetic characteristics, potential toxicity, and human responses, helping researchers prioritize candidate compounds with higher success probabilities. Moreover, for different stages of drug development, some companies or institutions are exploring higher levels of digitization based on generative AI, such as AI virtual cells, virtual clinical trials, and automation at the laboratory level, such as intelligent agents and robots applied in automated compound synthesis + wet lab validation.
To test the potential value of AI in drug discovery and to allow AI to truly integrate into specific processes of drug development, the current AI-driven drug discovery track exhibits a "hammer looking for nails" approach: reshaping the drug discovery process through AI or even defining an entirely new paradigm to reduce costs, increase efficiency, improve success rates, and shorten R&D cycles. However, this holistic approach lacks clear and specific definitions and evaluation criteria during implementation: what core pain points in the pharmaceutical industry does the industry expect AI to solve that traditional paradigms cannot address? And how should its effectiveness be evaluated? Take AlphaFold as an example. Before the DeepMind team developed AlphaFold, experimental structural biology faced a core challenge: while the accuracy of experimentally determining protein structures was indisputable, its efficiency lagged far behind the growth rate of protein sequence data. Therefore, this problem, known as the holy grail of computational structural biology, was clearly defined from the outset: how to accurately and efficiently predict protein structures from protein sequences? Moreover, there were well-defined criteria for evaluating prediction results. The subsequent breakthrough progress in this field is now widely recognized in both traditional CADD (Computer-Aided Drug Design) and AIDD (AI-Driven Drug Discovery) tracks.
02
How to efficiently verify and unleash the potential unique value of AI in drug development?
From a tool perspective, they can be roughly divided into two categories: one is "qualitative-level tools," which have phenomenal impact and paradigm-shifting significance, such as AlphaFold; the other is "quantitative-level tools," which mainly operate within existing technological paradigms, optimizing execution by improving efficiency, reducing costs, or expanding scale. Examples include molecular docking, molecular dynamics (MD) simulations, and FEP+, which achieve improvements in speed, accuracy, or resource consumption, and belong to "quantitative-level tools." These lack phenomenal unique value (see Reference Link 1) and, overall, still serve traditional R&D paradigms.
Looking back at the present, for the AI-driven drug pipelines currently advancing in the AIDD field, which specific step in the process cannot be replaced by traditional paradigms/technologies/tools? Which step can highlight the unique value of AI? Is the starting point of initiating an AI-driven drug pipeline to validate the value of AI technology or to address unmet medical needs? If an AIDD company plans to go public, should its narrative focus on "tools" or "problems"? Technical narrative or market narrative? Capital narrative or healthcare demand narrative? Should the business model adopt a "technology platform + SaaS" approach or a "technology platform + SaaS + Biotech/Pharma" structure? Another practical question is: Someday in the future, when we finally witness the approval and market launch of the first drug fully discovered and designed by AI, there is no denying that this will be an important milestone for AI-driven drug discovery. However, does the underlying technology platform have paradigm-shifting significance? Is it generalizable, replicable, and transferable? After all, whether a small molecule compound is designed by traditional CADD or by AIDD, this attribute alone does not enhance the compound's efficacy, safety, or accessibility, nor is it what most patients truly care about.
The above issues may already have clear and definite answers from AI pharmaceutical companies/Biotechs, or they may still be wavering, refusing to choose between two options, or perhaps wanting to "have their cake and eat it too," or even choosing to ignore them. It is undeniable that different companies have different strategic positions and business models. They can either bypass tough challenges or focus solely on tackling the hardest ones. However, when AI technology platforms face the practical challenges of business models, whether the mindset of "looking for nails with a hammer" can truly and efficiently unleash the potential unique value of AI in drug discovery becomes a debatable question. This article adheres to the principle of "problems first, tools second," focusing on AIDD small models that address well-defined core pain points, and proposes a central hypothesis: The primary issue in fully realizing AI's potential unique value in drug discovery does not lie in the accumulation of algorithms, data, automated processes, or technical platforms, but rather in the precise definition of core problems/hardcore pain points within specific R&D processes and the establishment of clear outcome evaluation criteria.
03
Clear Hard-Core Pain Points in the Drug Development Process——Definition + Examples
Taking early drug discovery and design as an example, the first question that needs to be answered is: what are the core pain points in the pharmaceutical industry that AIDD is expected to solve, and which traditional CADD cannot address? And how is its effectiveness evaluated? Due to the highly complex nature of human physiology and pathology, disease types, indications, target mechanisms, and individual differences all exhibit significant heterogeneity. This abstract question does not have a unified specific definition, and the evaluation criteria for its results also vary. This is also an important characteristic that distinguishes the pharmaceutical industry from fields such as the Internet: the market is relatively fragmented, with different diseases, different indications, and different targets, and there are multiple strong companies, unlike Google’s global oligopoly in the search market. Therefore, when discussing the specific process of drug development projects, the clear and hard-core pain points are not abstract propositions at the industry level, but rather practical challenges that fall on a certain unmet clinical need, a specific indication, a specific target, or even a specific safety issue. The objective existence of these practical challenges has been repeatedly confirmed by the industry's drug development practices.
Taking the CD47 target as an example, although it has gained significant attention in tumor immunotherapy, clinical trial data have already confirmed its core challenge: hematological toxicity. CD47 is not only highly expressed in tumor cells but is also widely present on the surface of normal red blood cells and platelets. While blocking this pathway can activate macrophages to phagocytose tumor cells, it may also trigger severe adverse reactions such as anemia and thrombocytopenia. To address this issue, some companies are attempting strategies like novel antibody design, bispecific antibodies, or fusion proteins (e.g., Hancon Biotech’s HCB-101 project) to reduce binding to red blood cells, aiming to maintain anti-tumor activity while lowering hematological toxicity. Another example related to unexpected toxicity is Schrödinger's oral CDC7 inhibitor SGR-2921, developed for relapsed/refractory acute myeloid leukemia and high-risk myelodysplastic syndromes. Although the target compound demonstrated high inhibitory activity in vitro, serious safety events occurred during early clinical trials, including two deaths potentially related to the drug, ultimately leading to the termination of the SGR-2921 project (see Reference Link 2). This case highlights that a complex barrier of unexpected toxicity still exists between molecular design and clinical success. Additionally, it is conceivable that the termination of the SGR-2921 project was one of the key motivations behind Schrödinger’s development of Predictive Toxicology, a toxicity prediction tool.
Take the TIGIT target as another example. It was once regarded as one of the most promising immune checkpoints following PD-1/PD-L1, attracting significant investment from several multinational pharmaceutical companies and some Chinese drugmakers. However, this field has encountered a series of clinical setbacks in recent years. Some underlying reasons include: the complex regulatory mechanisms of TIGIT-related pathways, limited efficacy of monotherapy; while combination therapies showed some potential in early studies, they struggled to consistently replicate results in phase III clinical trials. Additionally, insufficient understanding of key biomarkers and imprecise patient selection strategies not only amplified clinical trial risks but also reduced clinical translation efficiency. The collective setbacks of the TIGIT target indicate that "analogical extrapolation" based on existing immune checkpoint paradigms has inherent limitations: even if valid at the molecular mechanism level, if it does not play a dominant role in the tumor immune regulation network, it is difficult to translate into an intervention target with decisive clinical benefits. This case illustrates that the core challenges in drug development lie not only in the technical means themselves but also in the deep identification and accurate definition of unmet clinical needs and the core pain points of specific R&D projects. In fact, when the low-hanging fruits of the pharmaceutical industry have been picked, only the high-hanging ones remain; when the soft persimmons have been squeezed, only the hard ones are left. If AI can indeed bring about a revolutionary boost in productivity as expected, or even reshape traditional drug R&D paradigms, then aren't these high-hanging fruits, hard persimmons, and even tough nails the natural touchstones for AIDD's true value?
04
Focused Small AIDD Models Addressing Clear Hard-Core Pain Points——Taking the CD47 Target as an Example
1. Definition of Core Hard Pain Points
● Significant blood toxicity limits drugability and clinical application feasibility
● Core Objective: Reduce blood toxicity while maintaining/improving anti-tumor activity
2. Key Modeling Variables
● Efficacy: Tumor cell phagocytosis rate, activity of congenital and adaptive immune systems in jointly suppressing tumors
● Safety: Red blood cell binding rate, blood toxicity indicators
● Molecular Characteristics: Protein Sequence, Structure (Monomer/Complex), Antibody CDR Region, Fc Segment Type, Post-Translational Modifications, Features of the Binding Interface with Antigen Complex Structures
● Pharmacological parameters: Kd, kon/koff, in vivo half-life
3. Data Source
● Preclinical and Clinical Trial Data: In Vitro + In Vivo Animal + Clinical Stage Efficacy and Safety Data
● Protein structure data: including structural data from PDB, AlphaFold, and precise physical modeling, such as physically calculated structural data generated by Schrödinger's IFD-MD and FEP+ workflows.
● Experimental Data in Literature and Patents
4. Model Training
● Input features: Sequence encoding (One-hot, amino acid physicochemical properties), structural features (binding interface, charge distribution, Fc region information), pharmacological features
● Algorithm: Transformer architecture, graph neural network, or others
● Learning and Parameter Optimization Strategies: Multi-task Learning, Bayesian Optimization or Reinforcement Learning for Generating Candidate Mutation Sequences
● Closed-loop iteration: Prediction → Candidate generation → Experimental validation → Feedback → Retraining
5. Evaluation Criteria
● Reduce blood toxicity (erythrocyte binding rate, improvement in blood parameters)
● Maintain or enhance anti-tumor activity (phagocytosis rate, tumor killing)
● Candidate molecules can be rapidly iterated and validated in the preclinical research stage.
6. Examples of Drug Modality Application
● Monoclonal Antibodies: Predicting the Impact of CDR Region Mutations on Antitumor Activity and Hematotoxicity, Optimizing Fc Structure
● Bispecific Antibody: Evaluate the Blood Safety and Affinity Ratio Balance of Two Arms for Different Targets
● Fusion protein: Optimize the SIRPα-Fc interface, Fc type, and glycosylation pattern to reduce red blood cell affinity while maintaining anti-tumor activity.
05
Focused AIDD Small Models with Clear Hard-Core Pain Points —— Comparison Between Small Models and Large Models
As is known to all, the pharmaceuticals industry is a heavily regulated one. Compared with large models that rely on external resources, deploying small AIDD models within an enterprise has significant advantages. On the one hand, enterprises have control over core data, including candidate molecular structures, preclinical experimental data, patent layouts, and R&D strategies. Internal deployment keeps data within the enterprise boundary, reducing the risk of leaks while meeting regulatory requirements. It also supports meticulous data governance, making model training, prediction, and iteration fully auditable and traceable. On the other hand, the internal environment significantly reduces data access latency, allowing enterprise R&D personnel to directly call upon data for training and validation, shortening the model iteration cycle, and enabling rapid feedback and continuous optimization. Thus, small models offer greater flexibility in terms of security, compliance, and engineering execution, enabling AI to be deeply embedded in internal R&D processes.
From a methodological perspective, the core value of small models lies in "focusing on pain points and achieving results with minimal effort." Taking CD47 as an example, a multitask learning framework simultaneously predicts anti-tumor activity and hematotoxicity. Through data collection, feature extraction, labeling, small model training, candidate generation, experimental validation, and feedback iteration, a closed loop is formed. The results of small-scale experiments are directly used for retraining the model, enabling targeted optimization and continuous evolution. This rapid closed loop not only verifies the model's effectiveness but also ensures that each iteration focuses on clear, hardcore pain points, achieving targeted breakthroughs with low cost and low risk. In other words, AI-driven drug discovery resembles a constraint-based "search-screen-validate" process, with the essence being precise optimization and decision-making under complex constraints. By leveraging AIDD small models to quickly iterate and optimize against well-defined hardcore pain points, a highly focused, efficient, controllable, verifiable, and highly compliant internal corporate closed loop is established.
06
Focused AIDD Small Models Addressing Clear Hard-Core Pain Points——From Single Breakthrough to Model Array to Matrix
As is well known, drug discovery and design is a multi-parameter optimization process (see the schematic diagram below), involving multiple dimensions such as molecular activity, target selectivity, pharmacokinetics, toxicity, and drug-likeness. These factors are intercoupled and mutually restrictive, meaning that even if a single model performs exceptionally well on a core pain point, it can only address local issues and struggles to meet the complex demands of the entire R&D chain. Therefore, AIDD small models, which focus on clearly defined hardcore pain points, should be understood as "focused and sharp modular tools." Moving away from the holistic large model approach, these models are highly concentrated on specific pain points, enabling rapid iteration and validation around particular objectives. In practical applications, their value often lies in synergy with other models and experimental systems: for example, integration with pharmacokinetic simulations, structure-activity relationship models, and high-throughput screening data to form a multi-model collaborative optimization framework. Through this approach, different models handle their respective areas of expertise, evolving collaboratively under a unified objective function or decision-making framework, thereby progressively approximating the relatively optimal solution under multi-parameter conditions. By comparison, the output of a single model struggles to cover the complex biological and chemical space, while multi-model, multi-dimensional joint optimization may become the preferred path to improving success rates.
From a methodological perspective, a more feasible strategy is to build a synergy of "generative AIDD small models + model array/matrix + experimental validation." In this framework, the small models focus on core pain points and are responsible for generating high-value candidate molecules with directional guidance; a multi-model system (including traditional CADD tools, such as FEP+ based on precise physical modeling, and the latest AIDD tools, such as Iso-DDE, see Reference Link 1) evaluates and screens candidate molecules from multiple dimensions; experimental validation provides real-world feedback to continuously iterate, correct, and enhance model capabilities. The three components are coupled to form a controllable and iterative closed loop. Thus, the significance of AIDD small models lies not in replacing everything but in leveraging key areas to provide high-quality input for preclinical validation, thereby reducing failure rates in clinical stages.
07
Summary + Outlook
As mentioned above, in the specific process of drug development, AIDD small models are lightweight, task-specific AI models constructed to address well-defined hardcore pain points. They focus on unmet clinical needs, specific indications, or clear core challenges associated with specific targets. Their core value lies in concentrating on real and quantifiable R&D bottlenecks, achieving efficient prediction, screening, or optimization for specific problems through high signal-to-noise ratio data input and targeted algorithm design. In short, the AIDD small models referred to in this article can be defined as task-specific AI models trained under conditions of high signal-to-noise ratio data and clear parameter constraints to address a single core problem. Their key characteristics include clearly defined boundaries for core pain point problems, high signal-to-noise ratio data, a singular optimization goal, and the ability to be embedded in experimental closed-loop systems. Therefore, AIDD small models are not simply "smaller-scale models," but rather constraint-driven models that focus on core hardcore pain points.Accurate collaborative optimization and rapid iteration are achieved under clear boundaries and constraints.
At the same time, this paper proposes the following methodological framework for AIDD small models: a complete process from pain point identification, constraint definition, and data construction to model training and experimental closed-loop, achieving low-cost, low-risk targeted breakthroughs and controllable R&D closed-loops within enterprises. Taking the CD47 target as an example, to ensure that the AIDD small model is verifiable and replicable, the evaluation framework here is defined as: Problem = Objective + Constraint + Metric, where Objective represents the optimization goal, such as anti-tumor activity; Constraint represents key constraints, such as blood toxicity; Metric is a quantifiable indicator, such as red blood cell binding rate and toxicity score.
In the future, small AIDD models focusing on clear and hardcore pain points are expected to truly unleash the unique value of AI in drug discovery: Deployed within enterprises, these small AIDD models will focus highly on core pain points while ensuring data security and compliance, transforming AI into verifiable and quantifiable productivity. Considering that drug discovery is a multi-parameter collaborative optimization process, the future scenario may involve an array or even a matrix of small AIDD models, scattered like stars, continuously iterating and optimizing, deeply embedded in pharmaceutical companies' internal R&D processes. By addressing clear and hardcore R&D pain points, they will consistently drive the development of efficient, safe, and affordable innovative drugs to meet unmet medical needs.
Author Introduction

Dr. Li graduated successively from the Medical College of Soochow University (Bachelor's and Master’s) and the Faculty of Science at the University of Auckland, New Zealand (Ph.D.), with an interdisciplinary educational background in basic medicine, biochemistry and molecular biology, structural biology, biophysics, and pharmacology. During his Ph.D., Dr. Li received joint training at the Jülich Research Center in Germany, where he studied protein structure-function relationships using liquid-state nuclear magnetic resonance and molecular dynamics simulations. Later, Dr. Li worked at Shantou University and Nantong University before joining Ningbo Sansheng Biotechnology to participate in the development of multiple biopharmaceuticals. He is now an independent industry observer and researcher, focusing on traditional CADD+AIDD. As of March 2026, he has published seven papers in international journals, filed two Chinese invention patents, and owns one software copyright. Additionally, Dr. Li has 15 years of hands-on Python programming experience, and is committed to integrating structural biology, structural biophysics, and high-performance computing to advance precise drug discovery and design towards greater efficiency, safety, and accessibility.
* Reference Links
1、 https://www.isomorphiclabs.com/articles/the-isomorphic-labs-drug-design-engine-unlocks-a-new-frontier#a-new-gold-standard-for-binding-affinity-prediction
2、 https://seekingalpha.com/article/4879455-schrodinger-inc-sdgr-presents-at-td-cowen-46th-annual-health-care-conference-transcript
* Conflict of Interest Statement
The content of this article only represents the author's personal views. The author did not receive any compensation for this article and has no commercial relationship with any companies mentioned in the text. This article is solely for information exchange and reference, and does not constitute any form of investment advice. The information cited in the article is sourced from publicly available materials considered reliable as of the publication date, but the author makes no express or implied guarantees regarding its accuracy, completeness, or timeliness. The data, opinions, and judgments involved in the article are for reference only. Readers should rely on their own independent judgment and conduct thorough research and due diligence. Despite the author’s best efforts to ensure the authenticity, accuracy, and completeness of the content, there may still be omissions or misjudgments. Corrections from industry colleagues are greatly appreciated.