Turing-Darwin Pattern Discovery Platform: A 'Beidou System' for AI-Driven Biomarker and Drug Application Discovery in Computational Medicine

PHIL RIVERS
Medical Information Technology Service Provider
Drug development is facing significant challenges: the R&D cycle for new drugs is lengthy (approximately 14 years), costs remain prohibitively high (exceeding $1 billion), and the likelihood of a drug reaching the market is slim (with a success rate of less than 10%). To reverse this trend, the pharmaceutical industry has turned its attention to AI technologies, which are expected to reduce R&D costs.
There are now over 100 companies worldwide in the AI-driven drug discovery sector, with most focusing on optimizing candidate drugs. Unfortunately, the increasing number of candidates entering Phase I clinical trials has not directly led to a significant improvement in approval success rates. Pharmaceutical companies that leverage big data and AI technologies to achieve breakthrough solutions in the following areas stand to gain substantial returns: How can clinical trial success rates be improved? How can drug efficacy be enhanced? How can indications be continuously expanded? Can failed drugs be revived?
These issues can all be attributed to the challenge of identifying biomarkers that enable better patient-drug matching. Biomarkers are used for disease diagnosis, classification, and staging, as well as for assessing the efficacy and safety of drugs in target populations. Their role in drug development and clinical application is increasingly significant, earning them the metaphorical title of the “compass” on the long journey of pharmaceutical research and development.
So,What is the current status of biomarker development? How do AI and big data facilitate biomarker development? Beyond single molecules, in what other forms can biomarkers be developed?
In this article, the following six key points are worth noting.
1. The dividends from single-molecule biomarkers are gradually being exhausted, while new biomarkers based on big data will bring new dividends;
2. From data to biomarkers, three major challenges exist: the curse of dimensionality, the flood of variability, and the quagmire of computational power;
3. A life and computation interdisciplinary team from China's top institutions has dedicated two decades to developing a Pattern discovery engine for drug development based on computational medicine;
4. Having navigated the phase of technological and data accumulation, the TD-P platform for drug pattern discovery has entered its commercialization stage;
5. The platform’s latest achievements: new application scenarios for CDK4/6 inhibitors in cancer types beyond breast cancer have been discovered;
6. Achieve a comprehensive upgrade in drug R&D from the “Three 10s” to the “Three 5s.”
Single-molecule biomarkers have once led to the success of numerous star targeted drugs. However,The Dividend from Simple Biomarkers Is Gradually DepletingIf the discovery of genomic biomarkers for drug companion diagnostics is likened to picking peaches from a tree, then the approach of obtaining clear-cut biomarkers by “screening” for single-site mutations is akin to picking low-hanging fruit: easy to obtain and with obvious cost advantages. However, such low-hanging fruit are limited in number and have largely been exhausted.
The total volume of biological data generated globally each year has reached EB (109G) tier. With the continuously declining cost of sequencing, the volume of data generated, encompassing multi-omics data, medical imaging, and clinical information, has reached a level of 10 TB per person.Biomedical big data can now fully characterize life systems.The PubMed database indexes 30 million biomedical literature articles, with over 10,000 new submissions added daily. Leveraging knowledge and interpreting data to uncover the new benefits of novel biomarkers has undoubtedly brought fresh hope to the industry. The former director of the U.S. FDA’s Center of Excellence in Oncology once stated,One of the most promising applications of artificial intelligence is the discovery and development of biomarkers.
From a global perspective, several AI companies have emerged internationally that leverage knowledge graphs and machine learning to harness biomedical big data. In 2019, the UK-based unicorn BenevolentAI entered into a collaboration with Novartis aimed at utilizing AI technologies to explore indications for clinical-stage oncology drugs and identify responsive patient populations. Insilico Medicine collects multi-omics data from diverse healthy and diseased individuals across various age groups to identify biomarkers associated with aging and disease.
Does Having Data Guarantee the Discovery of Biomarkers?
Given the high dimensionality and complexity of the data, leveraging AI technologies to discover novel biomarkers remains fraught with challenges:
1. The Curse of DimensionalityThe data explosion has yielded thousands to tens of thousands of detectable potential biomarkers. Traditional bioinformatics tools and analytical methods are unable to leverage the increasingly large and diverse datasets for biomarker discovery. Biomarkers identified using these conventional approaches only represent patient characteristics within a limited scope and fail to be validated in prospective clinical trials. In this context, it becomes critically important for AI algorithms to effectively separate biomarker signals from noise.
Second, the mutation surge.Through sequencing technologies, we can now obtain a relatively clear overview of the tumor genome; however, the resulting “picture” remains extremely chaotic. Each tumor harbors 50 to 100 types of mutations, which vary significantly across different tumors, and the majority of these genetic alterations remain poorly understood. Genes do not act in isolation; rather, they function as a collective within complex network systems formed by various pathways to transmit signals regulating proliferation and apoptosis. Therefore, beyond identifying individual mutations, AI algorithms must also recognize biomarkers within these intricate gene networks.
Third, the Compute QuagmireCan we master computing power? This is the next challenging hurdle. Understanding biomedical big data requires the use of supercomputing. Access to computing power has become relatively easy, as it can be obtained through paid services from supercomputing centers and cloud computing centers available in society. However, off-the-shelf computing resources are not designed for biomedical big data; if they score 100 points in handling computation-intensive algorithms, they would only score 1 point when processing genomic data. If computing power is likened to an aircraft, piloting the plane loaded with biomedical data requires parallel optimization technology as the pilot. Teams equipped with specialized parallel optimization technologies and expertise in the biomedical field are a scarce resource globally.
Over the past two decades, the Research Center for High-Performance Computers at the Institute of Computing Technology, Chinese Academy of Sciences, has been engaged in research on “Biomedical Information Processing Systems.” Supported by national projects, the center has achieved multiple significant technological breakthroughs in high-performance computing technologies for biomedical big data and life-integrated big data analytics.
The center’s interdisciplinary team in life sciences and computing pioneered “computational medicine,” leveraging artificial intelligence and high-performance computing to shift from interpreting the functions of individual genes or proteins toward mining insights from systems biology, particularly cellular signaling pathways.Pattern-level (functional modules composed of a set of genes that implement a specific biological performance) novel biomarkers。
Computational medicine interprets data from the perspective of global variation.Although tumors harbor many rare variants, the downstream events they drive are not rare. Therefore, by constructing a new model that establishes the relationship between rare variants and downstream events, it is possible to unravel the challenge of tumor heterogeneity, identify undiscovered mechanisms of tumor evolutionary biology, and uncover pattern-level biomarkers.
Much like AlphaGo, its advantage over humans lies in its algorithm’s emphasis on the big picture rather than local calculations. Identifying the optimal move in any given local scenario does not necessarily guarantee ultimate victory; only a clear understanding of the overall situation can lead to a winning strategy.
This has been the team’s primary focus over the past few years.
Breaking the Curse of Dimensionality: Reducing the Mutation Deluge to a Cell Function Event Model. The team’s big data modeling process employs algorithmic strategies akin to those of AlphaGo. Leveraging the genomic characteristics of rare variants within 1,000 cell lines from diverse sources, focusing on 18,000 genes known to undergo mutations, the team conducted associative training on over 200 phenotypic traits (sets of deterministic intracellular events). This yielded a neural network-based model elucidating the relationships among cellular behaviors, functions, and signaling pathways.Transforming scattered, isolated variants into functional and interpretable eventsRather than directly linking genetic variants to disease modeling, the team first reduced dimensionality to cell functional event models before associating them with diseases and drugs, thereby significantly enhancing the efficiency of discovering new insights from data.
After years of foundational work, the team has developed over 400 basic models of deterministic intracellular events. AlphaGo, the Go-playing AI that defeated human champions, faced 361 possible moves on a 19x19 Go board, generating countless game variations. Similarly, these 400 basic models can be combined to simulate countless different tumor evolution scenarios, sufficient to construct a digital life equation for each patient. Among the verified lung cancer cases, there were no false-negative reports, with an overall effectiveness rate of 70.6%, and the anti-angiogenesis pathway achieving an even higher effectiveness rate of 91%.
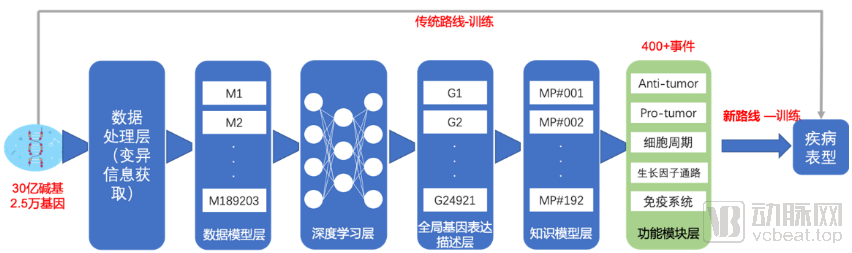
Encoding Variant Data into Cellular Functional Events
Deriving Novel Insights into Biomedical Mechanisms from KnowledgeThe team constructed its own life science-specific knowledge graph, TWIRLS, based on massive amounts of biomedical literature to uncover associations among diseases, phenotypes, genes, proteins, and drugs. By applying this knowledge graph, it is possible not only to maximize the extraction of existing knowledge but also to make inferences based on such knowledge, thereby generating new insights.
During the COVID-19 pandemic, the team conducted intelligent reasoning and analysis of over 14,000 publications on coronaviruses within four hours, ultimately concluding that the binding between the virus and ACE2 may induce functional changes in ACE2/AT2R, leading to homeostatic imbalance in the cytokine regulatory axis involving the renin–angiotensin system (RAS) and subsequently triggering a “cytokine storm.” The team posited that this mechanism might be a key regulatory factor contributing to host pathological changes following coronavirus infection, a hypothesis further corroborated by retrospective studies from three authoritative institutions in China. This study was recently published in the journal Drug Development Research.
High-performance computing that significantly accelerates data processing efficiency.The team possesses world-leading parallel optimization algorithms; during the model training phase, the team utilized 106Processing the data for G required 2,000 CPUs running for six months. Without parallel optimization techniques, it might have taken years to produce results, if at all. For the same model and data volume, direct computation on a minicomputer would take 10,000 hours; with parallel optimization, the computation time can be reduced to 100 hours. A high-level parallel optimization team can achieve even greater efficiency gains.
Is the computational medicine-based drug pattern discovery engine still in the research phase, and can it provide commercialized solutions?
To empower the industry with the “Biomedical Information Processing System,” the Institute of Computing Technology (ICT) of the Chinese Academy of Sciences incubated PHIL RIVERS to commercialize its research achievements. Together, they established the “ICT CAS · PHIL RIVERS-Turing-Darwin Laboratory,” dedicated to advancing computational medicine. The laboratory leverages the TD-P Platform (Turing-Darwin Pattern Discovery Platform), a drug pattern discovery engine, to empower drug development and precision medicine. Having surpassed the stages of technological and data accumulation, the platform is now capable of providing industrial-scale services.
First, excellent biomarker compatibility. The TD-P platform not only enables the discovery of novel biomarkers with quantitative properties and biological significance, but also maintains backward compatibility with single-molecule biomarkers. For instance, in a collaboration with a renowned principal investigator (PI) in China to identify patient populations suitable for chemotherapy in a specific solid tumor, the platform ultimately pinpointed variant sites detectable by PCR technology. This cost-effective, high-quality approach provides a novel solution for the in vitro diagnostics (IVD) industry.
Second, Rapidly Resolve Clinical IssuesTo meet the R&D and clinical application needs for a specific drug, only a small amount of specified sample data is required for adaptation on this technical platform, enabling the delivery of initially discovered biomarkers on a weekly basis. Subsequently, patient data can be used to perform further prospective predictions with the model, thereby optimizing its accuracy. In the aforementioned case, preliminary findings were achieved with a sample size of just 20, and the positive detection rate reached 70% when the prediction model was applied to over one hundred prospective samples.
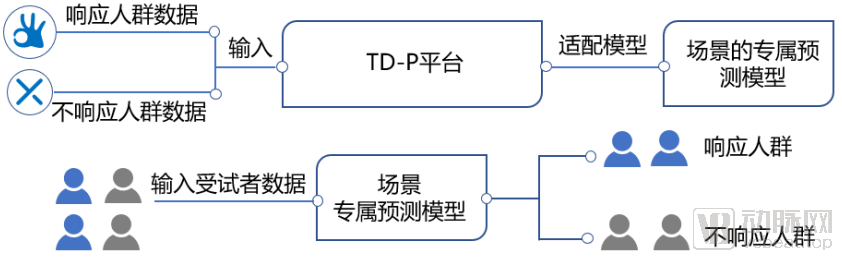
Scenario-Specific Model Adaptation
Third, Wide Range of Applicable ScenariosThe platform serves a dual purpose: matching drugs to patients and patients to drugs. During the drug development phase, it assists in selecting clinical scenarios for new drugs, optimizing clinical trial enrollment, expanding indications, and facilitating cross-line advancement. In the clinical application phase, it matches patients with medication regimens that offer the optimal response and minimal side effects, maximizing the value of valuable clinical treatment protocols and experience accumulated by physicians in practice, thereby enabling more precise personalized therapy.
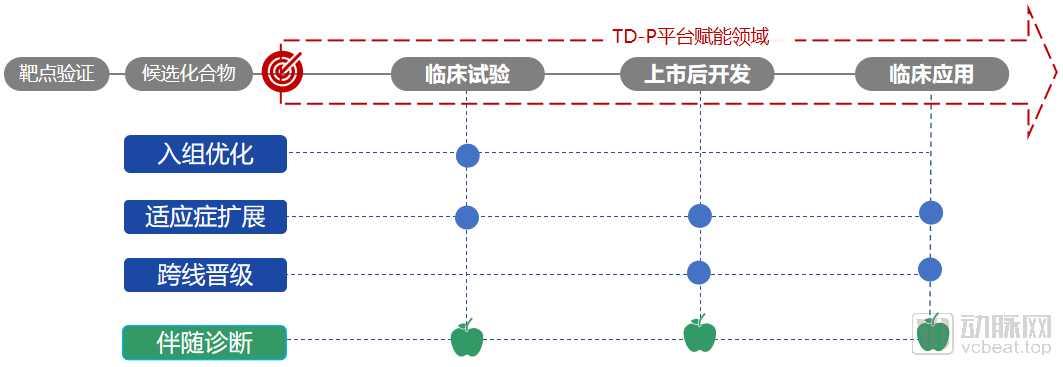
Extensive Service Scenarios
Can the TD-P Platform Deliver a Major Surprise to the Industry?
CDK4/6 inhibitors are targeted therapies directed against the CDK4 and CDK6 proteins, primarily used in patients with hormone receptor-positive, HER2-negative breast cancer. The first CDK4/6 inhibitor, Ibrance (palbociclib), generated nearly $5 billion in sales in 2019. Numerous prominent companies are actively developing CDK4/6 inhibitors, and competition in the Chinese market is expected to intensify rapidly.
However, even with estrogen receptors used as biomarkers, approximately 20% of patients still do not initially respond to CDK4/6 inhibitors, and all patients are eventually at risk of developing resistance. Other relevant clinical trials have also attempted to utilize various molecular markers, but the results have been unsatisfactory. It can be said that efforts to employ single molecules as biomarkers have largely failed. Those who can answer the following questions will have a better chance of succeeding in this fiercely competitive market.
1. Are there biomarkers that predict patient drug response?
2. Can it be used in combination with other therapies besides endocrine therapy?
3. Can the indications be expanded to other cancer types?
After reviewing historical research data and clinical case analyses of CDK4/6 inhibitors, the TD-P platform has identifiedPatients with several other cancer types can also benefit from CDK4/6 inhibitors, with efficacy potentially even superior to that observed in breast cancer patients.PHIL RIVERS also hopes to collaborate with developers of CDK4/6 inhibitors on this proprietary achievement. The TD-P platform has also made breakthrough discoveries in the development of companion diagnostics for anti-angiogenic agents and PD-1/PD-L1 monoclonal antibodies, as well as in the exploration of novel clinical scenarios and the optimization of patient enrollment in clinical trials.
Zhang Chunming, Executive Vice Dean of the Western Institute of Advanced Technology, Chinese Academy of Sciences Institute of Computing Technology, stated to VCBeat: “We aim to leverage AI closely aligned with clinical practice to accelerate drug development and significantly reduce R&D costs. We seek to transform the ‘Three 10s’ challenge—ten years of development, a $1 billion investment, and a 10% clinical trial success rate—into the ‘Three 5s’: five years of development, a $500 million investment, and a 50% clinical trial success rate.”
The “Beidou System” for drug R&D and application, leveraging big data, artificial intelligence, and high-performance computing networks, has ushered in a new era of precise drug targeting for the pharmaceutical industry amidst its current challenges.Developing drugs is no longer the endpoint of competition; accelerating clinical trials, continuously expanding new indications, providing patients with more precisely responsive medications, and better leveraging real-world data are the keys to future competitive success. "Computational Medicine," by understanding diseases and drugs from the perspective of digital life, assists in developing drugs with greater specificity, efficacy, and safety, enabling more precise "patient-drug matching," and will drive a new round of intelligent upgrades in the pharmaceutical industry.