More Effective Than Real Data? Silicon Valley Is Already Using Synthetic Clinical Data to Train AI

Airdoc
Artificial Intelligence Technology R&D Provider in Healthcare

SHUKUN
Provider of Intelligent Products and Innovative Solutions
After NFT and Web3.0, Silicon Valley is now rushing into Generative AI.
As the wave掀起 by large language models (LLMs) reaches every corner of the world, more and more people believe that generative AI offers us not just simple interaction—it can serve as a new form of productivity, gradually disrupting our work and life.
The first to detect the trend of change were investors focused on cutting-edge technology. Lu Zhang, founding partner of Fusion Fund in Silicon Valley, had not witnessed such a frenzy for a long time. As one of the earliest Silicon Valley investment firms to invest in AI applications in the healthcare sector, Fusion Fund has been strategically positioning itself in the field of generative AI for healthcare over the past few years. Its investment portfolio includes high-quality medical AI companies like Huma.AI and Subtle Medical, some of which have been collaborating extensively with OpenAI for as long as two years.
"The application of generative AI in vertical fields requires the industry to possess a vast amount of high-quality data to fully demonstrate its technical capabilities. The medical field, in particular, has an enormous amount of high-quality data—approximately 30% of all data in human society is healthcare-related, making it the largest category. Based on this, generative AI brings significant opportunities to the medical field," said Zhang Lu.
Unlike many popular tracks, the medical field appears to be dormant with billions of big data on the surface. However, when it comes to specific clinical scenarios, developers often worry about the quantity, quality, and acquisition cost of data. Particularly in the R&D direction of application-level clinical AI, what restricts its development is precisely the scarcity of medical data.
This time, can the artistic AI, proficient in drawing and lyric writing, enter the medical field and inject new vitality into the development of clinical AI?
The development trend of AI can be roughly summarized in two directions: one is single-task discriminative AI models, with typical examples such as AI-assisted diagnosis and treatment, classification, and detection for specific diseases; the other is generative AI applications, which generate higher-dimensional information from local data, such as predicting medical image data and generating health reports.
Both directions rely on clinical data for model training and are also limited by the lack of clinical data. Zhang Lu said: "As early as around 2018, researchers tried to use few-shot learning, Generative Adversarial Networks (GAN), and other methods to compensate for the insufficient number of training samples. It was also from that time that generative AI began to be applied in the medical field. It's just that now its definition is clearer, emphasizing the construction of Transformer Models on top of deep learning."
Taking Subtle Medical, invested in by Fusion Fund, as an example, the company's core business is to use AI to accelerate MRI and PET imaging speeds and improve imaging quality. This process itself involves using generative AI to process raw data to obtain synthetic data, and then reconstructing MRI and PET images based on the synthetic data.
"In clinical MR scanning, some sequences often suffer from low signal-to-noise ratio and significant artifacts, affecting the generation of the final images. Research published in IEEE titled 'One Model to Synthesize Them All: Multi-contrast Multi-scale Transformer for Missing Data Imputation' shows that with the support of AI, new images (such as higher resolution, different contrasts, or simulated contrast-enhanced images) indirectly generated from existing images like T1 and T2 can even outperform direct imaging. Currently, we are able to accelerate the imaging process of MRI and PET by 4-10 times and reduce the use of contrast agents by 10 times. Models based on the latest generative AI will continue to enhance product performance," Gong Enhao, CEO of Subtle Medical, told VCBeat.
"In addition, we are also working on image degraders to transform some gold-standard high-quality images into lower-quality ones that are closer to those obtained from actual scans, thereby training new models. This diffusion model, which integrates multiple data sources, performs significantly better than models trained through traditional methods."
Chinese AI company SHUKUN has applied generative AI to the image enhancement of coronary CTA. In collaboration with Shanghai First People's Hospital, both parties utilized GAN for post-processing of coronary CTA images, successfully repairing motion artifacts and ultimately improving the imaging quality of coronary CTA, bringing its diagnostic accuracy to the "gold standard" level of coronary angiography.
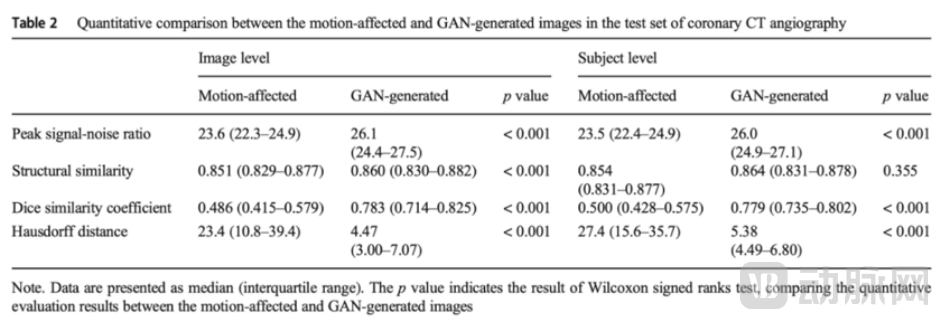
Quantitative analysis results show that the quality of coronary CTA images repaired using GAN technology is significantly higher than that of the pre-repaired coronary CTA images.
Generally speaking, a CT scanner with 64 rows or more is required to perform cardiac CTA scans. However, generative AI can enable CT scanners with 32 rows or even 16 rows to carry out CTA scanning tasks, producing images that meet the diagnostic needs of doctors. In theory, this technological empowerment can effectively enhance the capabilities and service quality of primary healthcare.
MR likewise, empowered by AI, the more common 1.5T equipment or low-field portable devices significantly enhance image quality, achieving diagnostic quality and scanning efficiency comparable to high-end 3T equipment.
Overall, the role of generative AI in single-task discriminative AI applications is to generate synthetic data based on raw data and apply it to the generation of final results, achieving image enhancement. Meanwhile, throughout the model training process, generative models can be used for data augmentation, enabling the acquisition of higher-quality images more quickly with smaller datasets, which benefits researchers in exploring scenarios where data is relatively scarce.
Compared with single-task discriminative AI that mainly focuses on improving analytical capabilities, the capabilities of generative AI applications are somewhat ahead of current medical needs. To give an imperfect example: discriminative AI applications can evaluate a patient's current health status, while generative AI applications aim to predict the future of everyone’s body.
Currently, there are very limited projects in China exploring the application of generative AI. A typical example is the retinal research conducted by Airdoc in collaboration with the Peking University Clinical Research Institute and Healthcheckup Group. By observing the development and changes in the retinal blood vessels and nerves of 400,000 individuals, researchers enabled generative AI to self-learn in order to predict the subsequent developments of the subjects and assess the risk of future cardiovascular and cerebrovascular diseases. The relevant research has been published in the internationally renowned journal *Science Bulletin*.
According to Airdoc, Alzheimer's disease risk prediction, myopia progression prediction, and Parkinson's disease risk prediction based on generative AI are also under development. If these diseases can be predicted or detected early through AI, timely prevention and treatment measures could help a large number of patients avoid disease risks and prevent subsequent long and uncontrollable treatments.
Since both single-task discriminative AI applications and generative AI applications use generated data during computation, can we directly generate medical data as AIGC does in finance and art?
Last year, the Informatics Institute at Washington University School of Medicine in St. Louis initiated a research project based on generative AI to create synthetic patient datasets, aiming to provide medical technology researchers with richer data and accelerate the development of various medical AIs.
The study utilized a generative AI model developed by the Israeli company MDClone. MDClone's system is directly connected to the hospital’s EHR, allowing it to extract and de-identify patient data, break down the data into specific dimensions, and then recombine it using its self-developed generative AI model. Through this process, MDClone can accurately generate large amounts of synthetic data based on a small number of real patient records from electronic health records, reconstructing the characteristics of real patients.
In subsequent research, relevant personnel will compare the synthetic dataset with the real dataset under three specific tasks: analyzing the mortality risk of pediatric trauma patients; predicting which hospitalized patients are most likely to develop sepsis; and creating a map of chlamydia infection rates by zip code in the St. Louis area over a year.
The comparative study results showed that the results of synthetic data analysis were statistically similar to those of real data analysis, and the same conclusions were drawn from each dataset. In the vast majority of cases, the statistical results were identical, with differences between real and synthetic datasets occurring only in rare instances.
This research result is consistent with the direction of Subtle Medical's research in imaging acceleration. It also means that, in the past, researchers often spent several months preparing training data, but with the empowerment of generative AI models, they can now build, query, and download their own synthetic datasets within hours to days.
In addition, this method of generating synthetic data also creates a strict way to protect patient privacy. Since synthetic data cannot be linked to real individuals or identities, hospitals may be able to use this technology to turn data into a specific asset, maximizing its utility for clinical research without compromising patient privacy.
The same logic can also be applied to imaging data.
In the process of training artificial intelligence for auxiliary diagnosis, the uneven distribution of patient imaging data often affects the performance of the final model in practical applications.
Taking dermatological AI as an example, when processing images, the AI needs to calculate the probabilities of various skin diseases simultaneously. However, since human skin types and disease categories are not evenly distributed, considering only the dimension of disease types, the data frequency of eczema and folliculitis tends to be higher, while the data frequency of psoriasis will be relatively lower.
Although conventional algorithms can achieve the synthesis of imaging data, there is a difference in quality between the synthesized data and real data, meaning that synthesized data cannot fully replace the value of real data. The emergence of generative AI fills the gap in generation logic, ensuring that the generated data not only maintains high quality but also accelerates the generation process and increases the scale of data production.
NVIDIA has long been involved in synthetic data for imaging. In 2022, NVIDIA and King's College London used the Cambridge-1 supercomputer to create a dataset containing 100,000 synthetic brain images to train AI applications, accelerating understanding of dementia, Parkinson's disease, and other brain disorders. The generation logic is similar to that of text: real data is broken down into elements and then recombined by AI following specific logic to address the issue of scarce data volume.
Another potential application scenario for synthetic data lies in the review and approval of discriminative AI for multiple diseases.
The clinical trial design for multi-disease AI is a complex process. For instance, when constructing datasets and validating algorithms for multi-disease AI (using N=2 as an example), it is necessary to not only build Disease A and Disease B databases but also an A∩B database. Additionally, medical knowledge must be incorporated into the model to enable it to explain, based on medical principles, the probability derivation process of the intersection data.
When the number of disease types is relatively small, the difficulty of building an integrated database remains manageable. However, under the current evaluation and approval logic, once the number of disease types increases, the variety of combinations of these diseases and the required richness of datasets will rise exponentially. Obstacles caused by uneven data distribution will also become more prominent.
For instance, the data for patients with stage 0 and stage 6 diabetic retinopathy are naturally limited, making it difficult for companies to find a sufficient amount of data in the real world to meet the requirements of validation datasets. When considering combinations of different diseases, the complexity of relevant data collection increases rapidly, eventually becoming an insurmountable challenge in practice. Clearly, applying generative AI to augment data in some scarce dimensions holds promise to address this issue.
DeepTherapeutics has obtained certifications from the FDA, CE, NMPA, and other regions. In an interview with VCBeat, Gong Enhao said: "The application of synthetic data runs through the entire AI application process. The FDA explicitly requires companies to clearly state the quantity and details of real clinical data used for training and testing. However, the FDA has not made clear regulations on the amount or specific stages of synthetic data usage. On the other hand, there is a difference between generating synthetic data during image enhancement to reconstruct images and directly building synthetic datasets for AI training. The latter approach still has room for exploration."
China's AI medical device standardization technical units and NMPA are also at the global forefront in formulating and discussing data quality control standards, aiming to establish comprehensive standards for training data, pre-training, and transfer learning. The further expansion of generative AI may accelerate the formulation of relevant laws, regulations, and evaluation and approval clauses, providing theoretical and economic feasibility for the evaluation and approval of multi-disease AI.
Recently, the Cyberspace Administration of China released a notice titled "Measures for the Management of Generative Artificial Intelligence Services (Draft for Comments)" for public consultation, with the intention of bringing generative AI under regulatory scope as soon as possible.
For this technology that is still in its rough growth phase, effective regulation will provide a more benign development space and help companies avoid potential policy risks early on. However, to comprehensively promote the development of generative AI in China, reliance solely on regulation is insufficient.
"Any technological innovation starts from fundamental technological innovation, moves to technological application innovation, and finally brings about business model innovation. Currently, there is a certain gap between the development of generative AI in China and Silicon Valley, existing both in models and data. In the United States, tech companies represented by OpenAI have completed the construction of infrastructure such as GPT models and large language models (LLM), which means that the U.S. has entered the second stage of innovation—technological application innovation," said Zhang Lu.
To catch up with Silicon Valley is not easy. On the one hand, technology companies need to achieve breakthroughs in foundational models, allowing later-stage startups to access advanced models through APIs. On the other hand, it is necessary to accelerate the governance of multimodal data to provide data support for specialized model training.
Back in China, which enterprises are able to take on the risk and shoulder the responsibility for AI's cross-era development? Time will tell.