Shanghai Jiao Tong University and LingYiWensi Unveil LaBraM: A Large Brain Model for Generic EEG Representation Learning in BCI

EmotionHelper
EmotionHelper

Recently, one of the three major international top conferences on machine learning:The 12th International Conference on Learning Representations(ICLR 2024) announced the acceptance results. The team of Bao-Liang Lu from the Department of Computer Science and Engineering, Shanghai Jiao Tong University, jointly published a paper with EmotionHelper titled "Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI"Paper."
Currently, deep learning models based on electroencephalogram (EEG) signals are typically designed for specific datasets and brain-computer interface (BCI) applications, which limits the scale of the models and thus weakens the representational ability and universality of EEG signals. Recently, large language models (LLMs) have achieved unprecedented success in text processing. These groundbreaking research results have prompted us to explore large-scale EEG models (LEMs). We hope that large EEG models can break through the limitations of EEG datasets across different task types, acquire universal representation capabilities of EEG signals through unsupervised pre-training, and then fine-tune the model on various downstream tasks.
However, compared with text data, EEG datasets are usually very small in scale and vary greatly in format. The development of large-scale EEG models faces the following challenges:
1) Lack of sufficient EEG data.
Compared with natural language and image data, it is extremely difficult to collect large-scale EEG data. Moreover, the annotation of EEG data usually requires domain experts to invest a significant amount of effort, resulting in only a small number of annotated datasets available for specific tasks in BCI. These tasks often involve EEG signals collected from a small number of subjects, typically lasting less than several dozen hours. Therefore, there is currently no sufficiently large EEG dataset to support the training of LEM.
2) Diversified configurations for EEG signal acquisition.
Despite the existence of the internationally recognized 10-20 system to ensure standardized EEG signal acquisition, users can still choose EEG caps with different electrode numbering or patch electrodes based on practical application needs to collect EEG data. Therefore, how to process EEG data in different formats to match the input units of Neural Transformer remains an issue that needs further exploration.
3) Lack of effective EEG representation learning paradigms.
The low signal-to-noise ratio (SNR) and various types of noise in EEG data present a very challenging problem. Moreover, balancing temporal and spatial features is crucial for effective EEG representation learning. Despite the availability of various deep learning-based EEG representation learning paradigms (such as CNN, RNN, and GNN) for raw EEG data processing, many researchers still tend to design handcrafted EEG features due to the aforementioned issues.
The goal of this paper is to design a general large-scale EEG model, called LaBraM. This model can effectively handle various EEG data with different channels and lengths. Through unsupervised training on a large amount of EEG data, we envision that the model will possess universal EEG representation capabilities, enabling it to quickly adapt to various EEG downstream tasks. To train LaBraM, we collected over 2,500 hours of EEG data from 20 publicly available EEG datasets, covering various tasks and formats.
First, we segment the original EEG signals into EEG channel segments to address issues related to different electrodes and time lengths. We employ vector-quantized neural spectrum prediction to train a semantically rich neural tokenizer for generating neural vocabularies. Specifically, the tokenizer is trained by predicting the Fourier spectrum of the raw signals. During pre-training, some EEG segments are masked, and the goal of the neural Transformer is to predict the masked tokens from the visible segments. We pre-trained three models with different parameter sizes: 5.8 million, 46 million, and 369 million parameters—the largest models in the BCI field to date. Subsequently, we fine-tuned them on four different types of downstream tasks, including classification and regression.
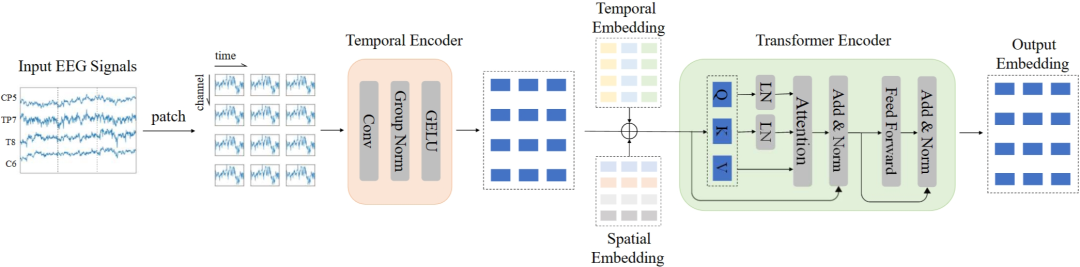
We introduce Neural Transformer, a universal architecture for decoding EEG signals that can handle any input EEG signal with an arbitrary number of channels and time lengths, as shown in Figure 1. The key operation to achieve this goal is segmenting the EEG signals into patches, inspired by patch embeddings in images. Due to the high resolution of EEG in the time domain, it is crucial to extract temporal features before patch interaction through self-attention. We employ a temporal encoder composed of multiple temporal convolution blocks to encode each EEG patch into a patch embedding. The temporal convolution block consists of a one-dimensional convolution layer, a group normalization layer, and a GELU activation function. To enable the model to perceive the temporal and spatial information of the patch embeddings, we initialize a list of temporal embeddings and a list of spatial embeddings. For any given patch, we add its corresponding temporal embedding and spatial embedding to the patch embedding. Finally, the sequence of embeddings will be directly fed into the Transformer encoder.
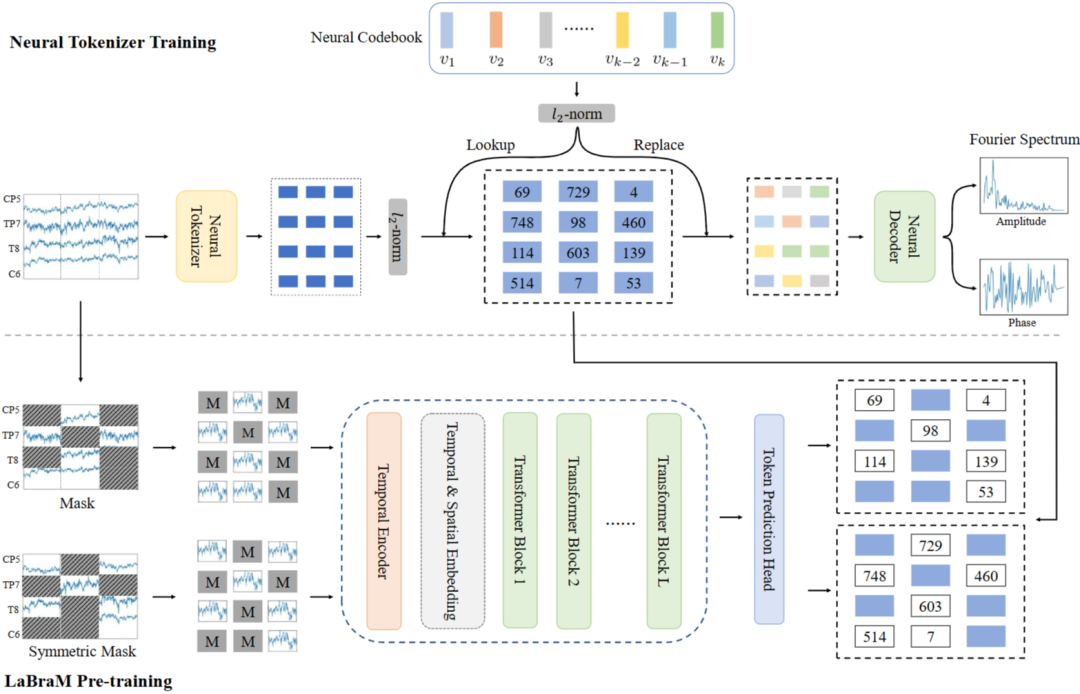
Before pre-training LaBraM through masking and prediction, we need to convert EEG tokens into discrete tokens. We propose Vector-Quantized Neural Spectral Prediction, which is trained by predicting Fourier spectra, as shown in the upper part of Figure 2. The key components are the neural tokenizer that encodes EEG samples into patch representations and the neural decoder that decodes Fourier spectra from neural embeddings. To enable LaBraM to learn universal representations from large-scale EEG data, we propose Masked EEG Modeling. The entire process is illustrated in the lower part of Figure 2. Given an EEG sample, the temporal encoder first converts it into patch embeddings. We randomly generate a mask, and the masked EEG patches are added with temporal and spatial embeddings before being fed into the transformer encoder to predict the masked EEG patches. We further propose a symmetric masking strategy to improve training efficiency.
We primarily validate LaBraM on two downstream task datasets: TUAB and TUEV. We designed three different LaBraM configurations: LaBraM-Base, LaBraM-Large, and LaBraM-Huge. LaBraM-Base has 5.8M parameters, LaBraM-Large has 46M parameters, and LaBraM-Huge has 369M parameters.
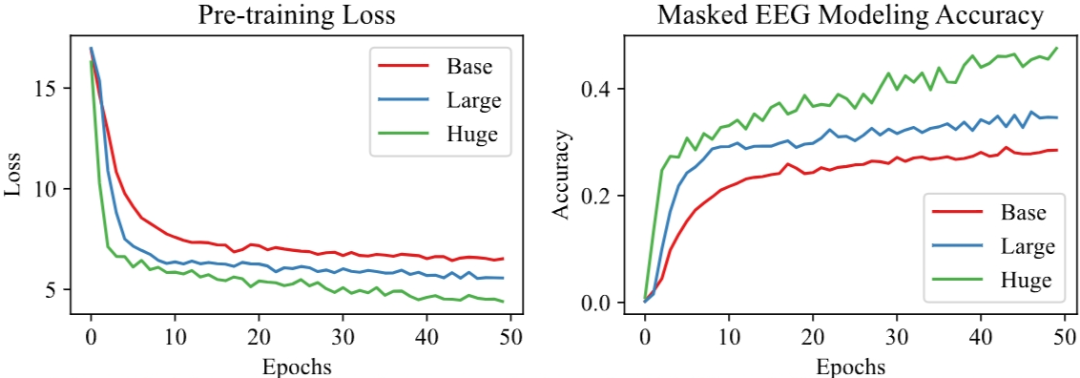
Figure 3 compares the convergence curves of the total pretraining loss and masked EEG modeling accuracy for the Base, Large, and Huge models. As shown in Figure 3, larger models with more parameters can converge to smaller losses and higher accuracy. Notably, the loss of the Huge model appears to have a significant downward trend, and if trained for a longer duration, its accuracy tends to improve. This observation suggests that scaling up the model size has the potential to achieve better performance.
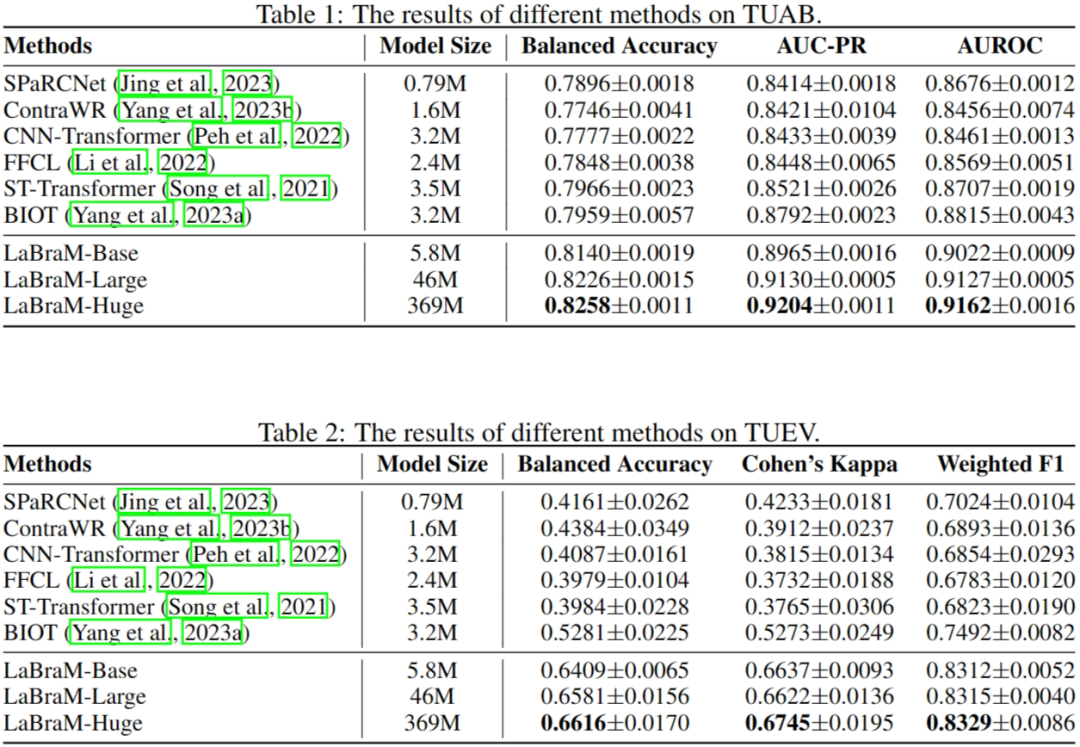
Table 1 and Table 2 list the best baseline results in TUAB and TUEV as well as the results of LaBraM. Clearly, our LaBraM-Base model outperforms all baseline models across various evaluation metrics in both tasks. Particularly in the more challenging TUEV multi-class classification task, our model achieves a significant performance improvement. Among our own models, we observe that the LaBraM-Huge model performs the best as the number of model parameters increases, followed by the LaBraM-Large model, and finally the LaBraM-Base model. We attribute this strong performance to the increase in both the amount of pre-training data and the number of model parameters. We infer that with sufficient EEG data, large-scale EEG models can learn more general EEG representations, thereby enhancing the performance of EEG signals across various downstream tasks.
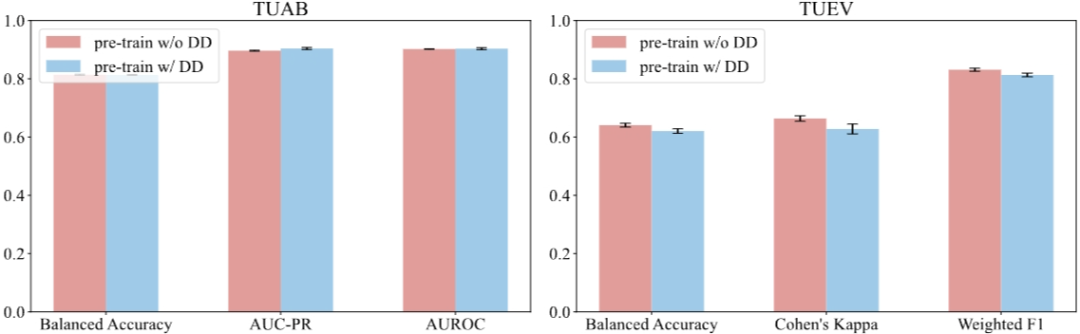
During the pre-training process, we hope the model can learn general EEG representations that are not specific to any particular task. Although no labeled data was used during pre-training, to eliminate the influence of the pre-training data on downstream tasks, we compared the results of whether or not the downstream task datasets were included in the pre-training process. Notably, the recordings from TUAB and TUEV do not overlap with those in the pre-training dataset. As shown in Figure 4, whether or not the downstream task datasets are included in the model’s pre-training process has little impact on the model's performance in downstream tasks. This indicates that our model has the ability to learn general EEG representations and provides guidance for collecting more EEG data in the future. In other words, we do not need to expend significant effort labeling EEG data during the pre-training process.
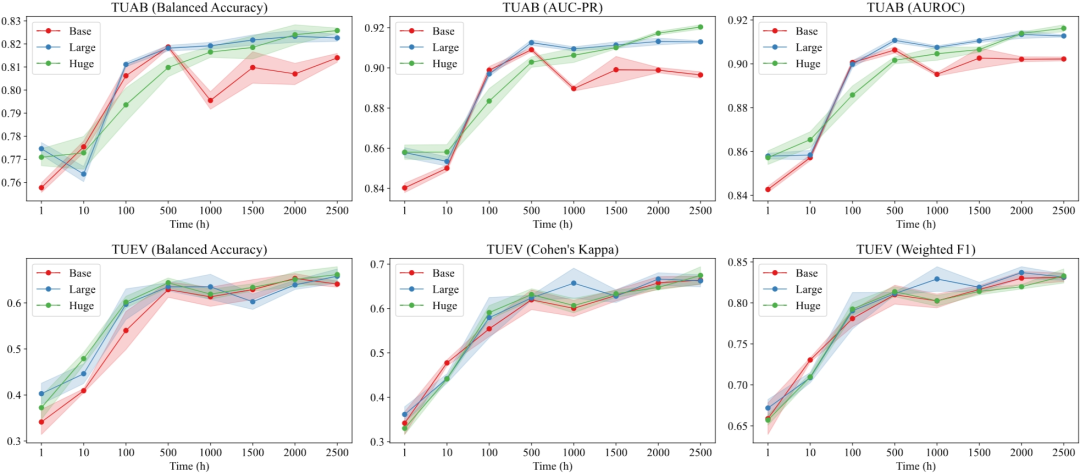
Although we have collected approximately 2,500 hours of EEG data, this is still relatively small compared to the sample sizes in natural language processing and image processing. We address the data size requirements for training LaBraMs of different sizes by adjusting the size of the pre-training data. As shown in Figure 5, the performance of the base model trained on 500 hours of data surpasses that of the model trained on 2,500 hours on the TUAB dataset, while approaching over 90% of the performance of the model trained on 2,500 hours on the TUEV dataset. For the Large model, performance generally improves with increasing data volume, although the rate of improvement slows down after 1,000 hours. In contrast, as the data volume continues to expand, the performance of the Huge model shows a clear upward trend. Therefore, we believe that as the dataset expands further, our models can achieve better performance. The question of how much EEG data is needed to pre-train large-scale EEG models is undoubtedly an important issue worth exploring in this field. However, 2,500 hours is at least not the answer to this question. Our observations largely follow the scaling law, leading us to infer that when the data volume reaches the order of at least ten thousand hours, the Huge model will continue to maintain strong performance.
Weibang Jiang, a Ph.D. candidate from the Department of Computer Science and Engineering at Shanghai Jiao Tong University, is the first author of this article. Dr. Liming Zhao from EmotionHelper and Professor Baoliang Lyu from the Department of Computer Science and Engineering at Shanghai Jiao Tong University are the co-corresponding authors.
—— End ——
Source: EmotionHelper
For academic sharing only. If there is any infringement, please leave a message and we will delete it immediately!

Join the Community
Welcome to join the Brain-Computer Interface Community Communication Group,
Discuss topics in the field of brain-computer interfaces and track the cutting-edge developments in real time.
Add WeChat group:
Add WeChat: RoseBrain [Note: Name + Industry/Major].
Add QQ group: 913607986
Welcome to contribute
1. Welcome to submit articles. For submission inquiries, please contact WeChat: RoseBrain
2. To join the community as a part-time creator, please contact WeChat: RoseBrain
