Groundbreaking Scientific Breakthrough of 2024: AlphaFold 3 Revolutionizes Molecular Interaction Prediction and Drug Discovery

Isomorphic Labs
AI Drug Developer

May 8, 2024, GoogleDeepMindJointly published with Isomorphic Labs in the journal *Nature* the latest AI model in the protein field, AlphaFold 3! This model can accurately predict the structures of proteins, DNA, RNA, and ligands, as well as their interactions. This follows...Another Major Breakthrough After AlphaFold 2

In predicting drug interactions, AlphaFold 3 has achieved unprecedented accuracy, including the binding of proteins with ligands and antibodies with their target proteins. In the PoseBusters benchmark,AlphaFold 3 is 50% more accurate than the current best traditional methods, and it requires no structural information input, making it the first artificial intelligence system to surpass traditional physics-based prediction tools.This ability to predict antibody binding to proteins is crucial for understanding various aspects of the human immune response and for the design of new antibodies.
Frontier Research on Deep Learning in Protein Design: Deep learning's cutting-edge research in protein design primarily focuses on protein structure prediction, protein sequence design, protein-protein interaction prediction, protein function annotation, and protein optimization and screening. These research directions provide new ideas for the development of novel functional proteins and drug targets, with applications in biomedicine, drug discovery, and biomaterials. The application of deep learning in protein design is considered one of the current frontier research areas, and its continuous development brings many innovations and opportunities to new drug development, biopharmaceuticals, and life science research.
The Three Most Anticipated Technologies in 2024

1. Deep Learning Protein Design
2. CADD Computer-Aided Drug Design
3. AIDD Artificial Intelligence Drug Discovery Design

echnology
Deep Learning in the Field of Protein DesignFrontier ResearchMainly focused on protein structure prediction, protein sequence design, protein-protein interaction prediction, protein function annotation, and protein optimization and screening. These research directions provide new ideas for the development of novel functional proteins and drug targets, and are profoundly applied in the fields of biomedicine, drug discovery, and biomaterials. The application of deep learning in the field of protein design is considered one of the cutting-edge research directions at present. The future of the protein structure prediction and design field will be full of innovation and interdisciplinary advancements, offering more possibilities to address significant challenges in biomedicine, bioengineering, and bioenergy.
Top journals published in recent years and their directions:
Nature Communications | Protein Design Using Structure-Based Residue Preferences
Nature biotechnology| Machine Learning for Functional Protein Design
Scientific reports| Deep-WET: A Deep Learning-Based Approach Using Word Embedding Technology with Weighted Features to Predict DNA-Binding Proteins
Cell Systems| Deep Learning Opens a New Era for Protein Design
Nat. Comput. Sci| Rotamer-Free Protein Design Based on Deep Learning
Comput Struct Biotech| Deep Learning for Protein Design: From Structure to Sequence and Function
This course focuses on the fundamentals and cutting-edge advancements in protein design, offering in-depth instruction ranging from protein structure prediction and optimization to de novo protein design. The course is primarily aimed at participants with a programming background, providing detailed explanations of foundational knowledge while incorporating discussions of state-of-the-art literature to illustrate the application of related technologies. By the end of this training, participants will gain an understanding of the underlying logic and basic principles of protein design, become proficient in the practical operation of common protein design algorithms, and acquire the essential skills for developing protein design algorithms along with a forward-looking perspective.
Deep Learning Protein Design Curriculum

Day One Python Programming Basics
1. Python Basics
➣ Introduction to Python: Understanding Python's history, features, and comparison with other programming languages.
➣ Installation and Environment Setup: Install Python, set up the Python development environment (e.g., Anaconda, Jupyter Notebook).
➣ Basic Grammar: Data Types (Integer, Float, String, Boolean), Variables, Basic Operators.
➣ Control Structures: Conditional Statements (if-else), Loop Statements (for loop, while loop).
➣Function: Definition, Parameters, Return Values, Scope, Recursion.
➣ Data Structures: Lists, Tuples, Dictionaries, Sets, Operations, and Common Methods.
➣File Operations: Reading and Writing Files, File and Exception Handling.
2. Advanced Python
➣ Classes and Objects: Fundamentals of object-oriented programming, creating classes, instantiating objects, understanding encapsulation, inheritance, and polymorphism.
➣ Modules and Packages: Import standard modules, use third-party packages, create custom modules and packages.
➣ Advanced Features: List Comprehensions, Generators, Iterators, Decorators, and Anonymous Functions.
3. The Application of Python in Scientific Computing
➣NumPy: Array creation, array operations, mathematical calculations, linear algebra, etc.
➣Matplotlib: Basic Charts, Scientific Graphics, Chart Customization.
4. Data Analysis and Visualization
➣Pandas: Data Structures (Series, DataFrame), Data Loading, Data Cleaning, Data Statistics, Data Merging.
➣ Data Visualization: Advanced data visualization using Matplotlib and Seaborn.
5. Specific Applications in Protein Design
➣BioPython: Sequence processing, database access, analysis of biological data.
➣ Script Writing: Automating common protein design tasks, such as sequence alignment and structure prediction.
➣ Machine Learning: Feature extraction, model training, evaluation, and optimization using Scikit-learn.
6. Practical Projects
➣ Project 1: Protein sequence data analysis, such as calculating the frequency of specific sequences, visualizing sequence distribution, etc.
➣ Project 2: Protein Structure Prediction, using machine learning techniques to predict the secondary structure or functional sites of proteins.
➣ Project 3: Develop a small protein design tool with integrated data processing, analysis, and visualization functions.
Day 2: Basic Shell Command Line Operations
1. Introduction to Shell Environment
➣ What is Shell: Understand what Shell is and how it interacts with the operating system.
➣ Different Types of Shells: Introduction to Bash, Zsh, Tcsh.
➣ Accessing Shell: How to open a terminal window, basic command-line interface operations.
2. Basic Commands
➣File System Operations: Usage of commands such as cd, ls, pwd, mkdir, rm, touch.
➣File Operations: cat, more, less, head, tail, grep, find and other commands.
➣Permissions and Ownership: Use chmod, chown, chgrp to change file permissions and ownership.
➣Text Processing: Basic usage of tools such as echo, cat, cut, sort, uniq, tr, awk, sed.
➣ Archiving and Compression: tar, gzip, gunzip, zip, unzip and other commands.
3. Shell Script Writing
➣ Create and Execute Shell Scripts: How to Write a Simple Script and Make It Executable.
➣ Variables and Data Types: Learn how to define and use variables in scripts.
➣ Flow Control:
➣ Conditional statements: the use of if, else, elif, case and other statements.
➣ Loop Structures: Usage of for, while, and until loops.
➣Function: How to define and use functions.
➣ Input and Output: Handle user input and script output.
➣ Quotation and Escape Characters: Learn how to properly use single quotes, double quotes, and escape characters in the command line.
4. Advanced Shell Programming
➣ Debugging Shell Scripts: How to debug Shell scripts, including setting and using debugging options.
➣ Regular Expressions: Application of basic regular expressions, used in conjunction with grep, sed, and awk.
➣ Environment Management: Understand the functions and management methods of PATH and other environment variables.
➣ Script Security: Write secure scripts to avoid common security issues.
5. Practical Cases and Projects
➣ Data Backup Script: Create a script to automatically back up your important files.
➣ File Organization Script: Write a script that automatically organizes files in the download folder.
➣Writing Scripts for PDB File Analysis
Day 3: Fundamentals of Protein Design: From Classical ForcesField to DepthLearning
1. How to calculate the energy of protein conformations?
a) Common Methods for Protein Visualization and Editing
i. Brief Introduction to PyMOL Usage
ii. Brief Introduction to the Use of Chimera
iii. Detailed Explanation of the PDB File Format
iv. Editing protein structures using Python libraries such as Biopython and PyMOL
b) Introduction to Molecular Mechanics and Solvation Energy
i. Molecular Mechanics Formula Format
ii. Calculation Method of Solvation Energy
iii. MM/PBSA Method for Calculating Binding Free Energy
2. Protein Design Method Based on Statistical Potential Function —— Rosetta
a) General definition of statistical potential function
b) Statistical potential functions in protein design
i. Rosetta Statistical Potential Definition
ii. Rosetta Energy Function Common Terms and Physical Significance
c) Protein design based on Rosetta potential function
i. Design Process
ii. Experimental Results
3. The Power of Protein-Protein Docking – A Protein Drug Design Process Without Prior Knowledge
a) Introduction to Protein-Protein Docking
i. Definition of Protein-Protein Docking
ii. Introduction to RifGen Docking Method
b) Protein Drug Design
i. Design Process
ii. Experimental Results
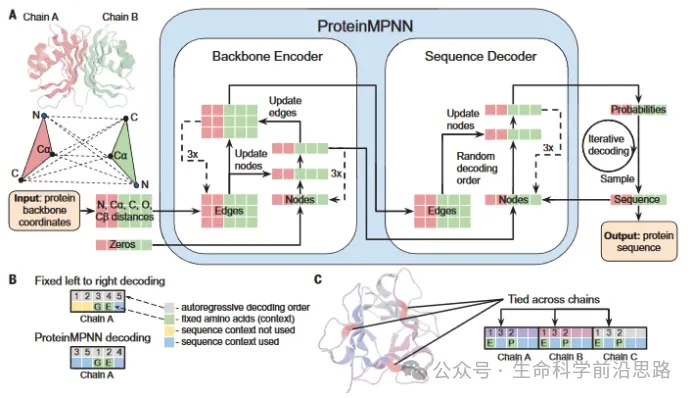
4. Deep Learning Takes the Stage —— Protein Design Model ProteinMPNN
a) Introduction to MPNN Message Passing Neural Networks
b) Introduction to ProteinMPNN Model
i. Model Structure Introduction (Input, Output, Parameters...)
ii. Model Usage (Primary Programming Language: Python)
c) Protein design based on ProteinMPNN
i. Design Process
ii. Experimental Results
5. Equal or Worlds Apart? A Comparison of Two Protein Design Methods
a) Deep learning models have a higher sequence recovery rate.
b) Deep learning models can achieve design tasks that rosetta and alphafold cannot complete.
c) Shortcomings of Deep Learning Models
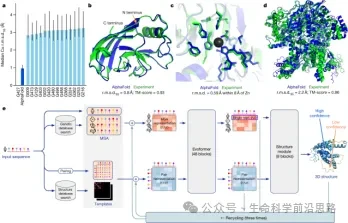
Day 4: Alphafold vs Rosettafold
1. Background Introduction to Protein Structure Prediction
2. Early Protein Structure Prediction Algorithms: From Statistical Analysis to Deep Residual Networks
2.1 Direct Coupling Analysis and Mutual Information Calculation
2.2 Deep Residual Networks and Protein Contact Map Prediction
2.3 Protein Distance Matrix Prediction
3. Gradient Descent with Geometric Constraints to End-to-End Deep Learning for Protein Structure Prediction
3.1 Introduction to trrosetta and alphafold
3.2 Introduction to End-to-End Geometric Deep Learning Methods
4. Differences and Innovations between AF and AF2
4.1 Introduction to the First Generation of Alphafold
4.2 Detailed Explanation of Alphafold2
5. Detailed Explanation of Rosettafold
5.1 SE3 Network
Day 5: Downstream Applications Based on Alphafold
1. Key Issues and Solutions in AF2 Multimeric Protein Structure Prediction
1.1 Sequence Assembly Pairing Problem in Multiple Sequence Alignment
1.2 Template Matching Problem
2. Using AF2 for flexible docking of proteins and peptides
2.1 Geometric and Physicochemical Complementarity of Protein Surfaces
2.3 Peptide Flexibility/Conformation Handling
3. Using AF2 for New Protein Structure and Sequence Design
3.1 trrosetta Fantasy Design
3.2 AF2 Sequence and Structural Fantasy Design
4. Using AF2 for structural clustering to discover new structures and functions
4.1 Introduction and Analysis of the Alphadatabase Database Structure
4.2 Introduction to Foldseek Structural Alignment Tool
4.3 New Structures and New Functions
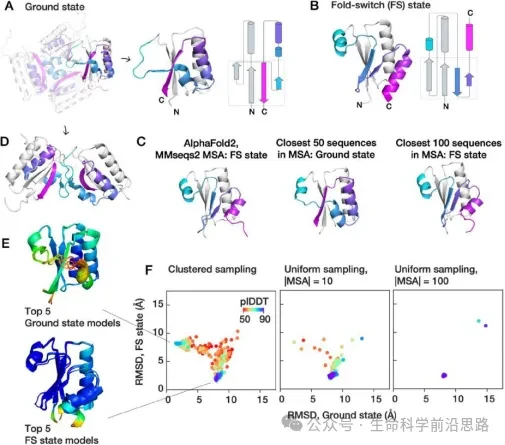
5. Using AF2 for Multi-Conformation Prediction and Function Discovery
5.1 MSA Sampling Clustering Analysis and Structure Prediction
5.2 Different MSAs Can Predict Transitions and Functions Between Conformations
6. Utilizing partial algorithm modules of AF2 for model quality assessment, side-chain conformation, etc.
6.1 Triangular Mechanism Enhances Protein Model Quality Assessment
6.2 Local Triangular Mechanism and Evoformer for Protein Side Chain Prediction
Day 6: De Novo Protein Generation Model
1. Review of Rosettafold's Basic Architecture
2. Improvements Based on Rosettafold
a) Regarding Diffusion Models
b) Model modification based on diffusion model
3. RFdiffusion Achieves General Protein Structure Generation
a) Protein binder generation
b) Protein structure generation based on backbone structure
c) De novo generation of protein monomers
d) De novo generation of multimeric proteins
4. ProteinGenerator Enables Co-Design of Protein Backbone and Sequence
a) The joint distribution of protein sequence-structure in the latent space
b) Differences and Similarities with rfdiffusion
5. Rosettafold AA Enables Prediction and Generation of Multiple Classes of Biomacromolecular Structures
a) Add small molecule structure predictor
b) Migrate the local coordinate system to the small molecule structure
6. Basic Architecture and Implementation of Chroma
a) Model Explanation
b) Utilizing chroma to approximate full-space sampling and generation of protein conformation space

Day 7: Application of Large Language Models in Protein Design and Peptide Design
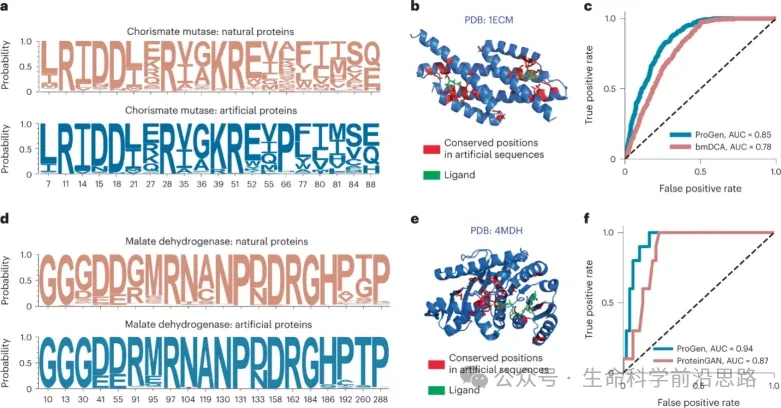
1. Basic Implementation of ProGEN
a) Model Architecture Explanation
b) Comparison with structure-based methods
2. Performance and Improvements of ProGEN
3. Basic Framework of ESM-fold
a) ESM Network Architecture
b) ESMfold Network Explanation
c) Comparison with the AlphaFold method
4. Performance Evaluation of ESM-fold
5. Downstream Applications of Protein Generation Models Based on Large Language Models
a) Rapid Prediction of Protein Structures
b) Large protein complex structure prediction
6. Differences and Connections Between Peptide Design and Protein Design
a) Molecular structure stability
i. Secondary Structure Content
ii. Hydrogen Bond Network and Local Secondary Structure
b) Functional Isomorphism and Differences of Molecules
c) Bottlenecks in peptide design faced by protein design methods
7. Peptide Design Algorithm
a) Peptide design based on Rosetta
i. Flexpepdock
ii. Anchor extension
b) Peptide design based on RF diffusion
i. Setting and Optimization of Parameters
ii. Evaluation of Generated Structures
c) Peptide backbone and sequence design based on AlphaFold gradient descent
d) Peptide docking algorithm
i. Peptide Docking Based on Autodock
ii. Flexible Peptide Docking Based on AlphaFold
iii. Other docking algorithms
8. Deep Learning Peptide Design Algorithm Trained on Peptide-Protein Complexes
Course Objectives

Structural Prediction Basis:Students will learn to analyze protein sequences using bioinformatics tools, predict their secondary and tertiary structures, and understand the relationship between structure and function.
Model Application and Evaluation:Students will be able to use machine learning and deep learning models for protein structure prediction, while learning how to evaluate the accuracy and reliability of the models and select the appropriate tools for application.
Drug Design:Master the principles of drug design related to protein structure prediction, learn to design drug molecules and peptide drug molecules targeting specific proteins, and understand the mechanisms of protein-drug target interactions.
What you will gain through the course

General-Purpose Protein Design Model Based on Deep LearningIn recent years, this course has developed rapidly, focusing on the fundamentals and cutting-edge work of protein design. It provides in-depth teaching ranging from protein structure prediction and optimization to de novo protein design. Starting from scratch, the course explains basic knowledge in detail and combines it with the latest literature to illustrate the application of related technologies, helping students...Through this training, participants will understand the underlying logic and basic rules of protein design, master the practical operation of common protein design algorithms, and gain foundational skills for developing protein design algorithms as well as a forward-looking perspective.
Course Structure

1. Course Features -- Comprehensive course technology application, principle process, and instance connections throughout.
2. Learning Mode -- Combining theoretical knowledge with hands-on operation, enabling beginners to quickly master the skills.
3. Course Service Q&A -- The main lecturer will provide professional answers to the problems you encounter in your actual work.
Course Q&A, Student Reviews, and Materials

The teacher patiently answers every trainee's questions, with nearly 2000 Q&A sessions each training.
More than 300 pages of PPTs along with corresponding code, providing software installation and guidance. Preview videos will be sent upon successful registration for pre-study.
The lecturers are from the top 1 university in China, and the group's work mainly focuses on novel protein design, protein structure prediction algorithm development, and automated high-throughput drug screening. They have already published in Nature. Chemistry Sub-Journal, Published 2 SCI-indexed papers in authoritative journals such as JCAS, Angew, JMC, and JCTC.0More than...
02
CADD Computer-Aided Drug Design
Course Objectives
Science Technology
CADD Computer-Aided Drug Design:Based on the research achievements in life sciences such as biochemistry, enzymology, molecular biology, and genetics, and using computational chemistry as a foundation, this method involves simulating, calculating, and predicting the interactions between drugs and receptor biomacromolecules through computer modeling. It examines the structural and property complementarity between drugs and their targets to design rational drug molecules. This approach serves as a method for designing and optimizing lead compounds and is widely applied in areas like food, biology, chemistry, pharmaceuticals, plants, and diseases! The discovery and validation of targets represent the first step in modern new drug development and also one of the bottlenecks in the process of creating new drugs.
Computer-Aided Drug Design (computer aided drug design) is a method based on computational chemistry that designs and optimizes lead compounds by simulating, calculating, and predicting the interactions between drugs and receptor biomacromolecules through the use of computers. In essence, computer-aided drug design involves optimizing and designing lead compounds by simulating and calculating the interactions between receptors and ligands. Computer-aided drug design generally includes active site analysis, database searching, and de novo drug design.
CADD Computer-Aided Drug Design Course Schedule

Day OneMorning
Background, Theoretical Knowledge, and Tool Preparation
1. Introduction and Use of the PDB Database
1.1 Introduction to the Database
1.2 Query and Selection of Target Protein Structures
1.3 Download of Target Protein Structure Sequence
1.4 Download and Preprocessing of Target Proteins
1.5 Batch Download Protein Crystal Structures
2. Introduction and Use of Pymol
2.1 Introduction to Basic Software Operations and Fundamental Knowledge
2.2 Protein-Ligand Interaction Diagram
2.3 Protein-Ligand Small Molecule Surface Diagram, Electrostatic Potential Representation
2.4 Protein-Ligand Structure Superposition and Alignment
2.5 Plotting Interaction Forces
3.Introduction and Use of Notepad
3.1 Introduction to Advantages and Main Functions
3.2 Interface and Basic Operations Introduction
3.3 Plugin Installation and Usage
Afternoon
General Protein
-Ligand Molecular Docking Explanation
1. Introduction to Relevant Theories of Docking
1.1 The Concept and Basic Principles of Molecular Docking
1.2 Basic Methods of Molecular Docking
1.3 Commonly Used Software for Molecular Docking
1.4 General Process of Molecular Docking
2. Conventional Protein-Ligand Docking
2.1 Collection of Receptors and Ligand Molecules
2.2 Processing of Complex Pre-conformations
2.3 Preparation of Receptor and Ligand Molecules
2.4 Protein-Ligand Docking
2.5 Analysis of Docking Results
Taking the main protease of the新冠病毒 protein and related inhibitors as an example
The Next Day
Virtual Screening
1. Introduction and Download of Small Molecule Database
2. Introduction to Relevant Programs
2.1 Introduction and Usage of OpenBabel
2.2 Introduction and Use of ChemDraw
3. Preprocessing for Virtual Screening
4. The Process and Practical Demonstration of Virtual Screening
Case: Screening for Main Protease Inhibitors of SARS-CoV-2
5. Result Analysis and Plotting
6. Drug ADME Prediction
6.1 Introduction to ADME Concepts
6.2 Introduction to Relevant Websites and Software for Prediction
6.3 Analysis of Prediction Results
Day Three
Methods for Expanding Docking Usage
1.Protein-Protein Docking
1.1 Application Scenarios of Protein-Protein Docking
1.2 Introduction to Related Programs
1.3 Collection and Preprocessing of Target Proteins
1.4 Calculation Using Examples
1.5 Preset of Key Residues
1.6 Acquisition of Results and File Types
1.7 Analysis of Results
Currently popular targets
PD-1/PD-L1, etc.
2. Docking involving metalloenzymes
2.1 Background Introduction of Metalloenzyme Protein-Ligand
2.2 Collection and Preprocessing of Proteins and Ligand Molecules
2.3 Treatment of Metal Ions
2.4 Docking of Metal Cofactor Protein-Ligand
2.5 Result Analysis
Taking human farnesyltransferase and its inhibitors as examples
3. Protein-polysaccharide molecular docking
4.1 Protein-Polysaccharide Interactions
4.2 Key Points of Docking Processing
4.3 The Process of Protein-Polysaccharide Molecular Docking
4.4 Protein-Polysaccharide Molecular Docking
4.5 Analysis of Related Results
Taking α-glucosidase and polysaccharide molecular docking as examples
5. Nucleic Acid-Small Molecule Docking
5.1 Application Status of Nucleic Acid-Small Molecules
5.2 Introduction to Related Procedures
5.3 Types of Nucleic Acid-Small Molecule Binding
5.4 Nucleic Acid-Small Molecule Docking
5.5 Analysis of Related Results
Human Telomere
g - Quadruple chain and ligand molecular docking as an example.
Introduction to Operation Process and Practical Demonstration
Day 4
Methods for Expanding Docking Usage
1.Flexible docking
1.1 Introduction to the Use Cases of Flexible Docking
1.2 Advantages of Flexible Docking
1.3 Protein-Ligand Flexible Docking
Focus: Method for Setting Flexible Residues
1.4 Analysis of Related Results
Cyclin-dependent kinase
2 (CDK2) with ligand 1CK as an example
2. Covalent Docking
2.1 Introduction to Two Covalent Docking Methods
2.1.1 Flexible Side Chain Method
2.1.2 Two-Point Attractor Method
2.2 Collection and Preprocessing of Proteins and Ligands
2.3 Covalent Docking of Covalent Drug Molecules with Target Proteins
2.4 Comparison of Results
Taking the currently popular covalent drugs for COVID-19 as an example.
3. Protein-Hydration Docking
3.1 The Significance and Methods of Hydration in Protein-Ligand Interactions
3.2 Collection and Preprocessing of Proteins and Ligands
3.3 Preparation of Relevant Parameters for Docking
Focus: The Addition and Treatment of Water Molecules
3.4 Protein-Water-Ligand Docking
3.5 Result Analysis
With Acetylcholine Binding Protein
(AChBP) with nicotine complex as an example
Day 5
Molecular Dynamics Simulation (Linux and GROMACS Installation and Usage)
1. Introduction and Simple Use of Linux System
1.1 Common Linux Command Lines
1.2 Common Program Installation on Linux
1.3 Experience: How to Perform Virtual Screening on Linux
2. Introduction to Molecular Dynamics Theory
2.1 Principles of Molecular Dynamics Simulation
2.2 Methods and Related Programs of Molecular Dynamics Simulation
2.3 Introduction to Related Force Fields
3. Introduction and Usage of Gromacs
Focus: Introduction to Main Commands and Parameters
4. Introduction and Use of Origin
Day Six
Execution of Solvated Molecular Dynamics Simulations
1. General Workflow for Handling Solvated Proteins
2. Preparation of Protein Crystals
3. Energy Minimization of Structures
4. Pre-equilibration of the system
5. Unrestricted Molecular Dynamics Simulation
6. Presentation and Interpretation of Molecular Dynamics Results
Taking lysozyme in water as an example
Day Seven
Execution of Protein-Ligand Molecular Dynamics Simulations
1. Protein-Ligand Processing Workflow in Molecular Dynamics Simulations
2. Preparation of Protein Crystals
3. Preparation of Initial Conformations for Protein-Ligand Docking
4. Preparation of Ligand Molecular Force Field Topology Files
4.1 Brief Introduction to Gauss
4.2 Brief Introduction to Ambertool
4.3 Generating Force Field Parameter Files for Small Molecules
5. Pre-equilibration with separate restraints on temperature and pressure in the complex system
6. Unrestricted Molecular Dynamics Simulation
7. Presentation and Interpretation of Molecular Dynamics Results
8. Trajectory Post-processing and Analysis
Taking the main protease of the新冠病毒 protein and related inhibitors as an example
Course Objectives

Enable students to master proficiently:PDB database, target protein, protein-ligand, protein-ligand small molecule, protein-ligand structure, molecular docking, protein-ligand docking, virtual screening, protein-protein docking, protein-polysaccharide molecular docking, protein-hydration docking, molecular dynamics and other technologies
Target Audience

At present, computer-aided drug design serves a wide audience in the human body, such as CADD, drug design, pharmaceuticals, drug discovery, drug screening, new drug development, medicinal chemistry, biopharmaceuticals, immunology, natural products, veterinary drug research, bioinformatics, Chinese medicine pharmacology, Chinese medicine chemistry, network pharmacology, structural pharmacology, food safety, food flavor, food and drug research, food development, anti-tumor drugs, tumor immunity, enzyme engineering, genetics, antibody drugs, agricultural engineering, chemistry, organic synthesis, organic chemistry, structural biology, synthetic biology, and many other scientific researchers.
Training Architecture

1. Course Features -- Comprehensive coverage of course technology applications, principles and processes, and practical examples throughout.
2. Learning Mode -- Combining theoretical knowledge with hands-on operation, enabling beginners to quickly master proficiency.
3. Course Service Q&A -- The main lecturer will provide professional answers to the problems you encounter in your actual work.
Teaching Materials

The teacher's preparation PPT is nearly 1000 pages. The training software will be provided along with installation guidance. So far, there have been over 30 sessions, with more than 3000 participants. The feedback from the attendees has been consistently very positive, making it the best training course for CADD (Computer-Aided Drug Design) in China.
The lecturer for computer-aided drug design comes from the Institute of Materia Medica at Peking Union Medical College Hospital, a leading university in China. The lecturer specializes in research areas such as virtual drug screening, computer-aided drug design, AI-driven drug discovery, molecular docking, and molecular dynamics, with over a decade of research experience and more than 20 papers published as the first author.
SPORTS
03
AIDD Artificial Intelligence Drug Discovery and Design
Course Objectives
Science Technology
AIDD Artificial Intelligence Drug Discovery and Design:It is artificial intelligence and machine learning technologies that have modernized the pharmaceutical field. Currently, machine learning and deep learning algorithms have been applied to various drug discovery processes, including peptide synthesis, virtual screening, toxicity prediction, drug monitoring and release, pharmacophore modeling, quantitative structure-activity relationships, drug repurposing, multi-pharmacology, and physiological activity. These technologies can effectively integrate traditional chemistry-oriented drug discovery with AI-driven drug design. Moreover, systems biology and chemistry scientists worldwide are collaborating with computational scientists to develop modern ML algorithms and principles, significantly accelerating drug discovery and development.
AIDD Artificial Intelligence Drug Discovery and DesignCurriculum Schedule

Day One
1.Overview of AIDD and Introduction to Comprehensive Drug Database
2. Overview of Artificial Intelligence-Aided Drug Design (AIDD)
3. Installation Environment
(1)anaconda
(2)vscode
(3)pycharm
(4) Virtual Environment
4. Basic Usage of Third-Party Libraries
(1)numpy
(2)pandas
(3)matplotlib
(4)requests
5. Acquisition Methods of Comprehensive Databases for Multiple Drugs
(1) KEGG (requests crawler)
(2)Chebi(libChEBIpy)
(3)PubChem(pubchempy / requests)
(4)ChEMBL(chembl_webresource_client)
(5)BiGG(curl)
(6)PDB(pypdb)
The Next Day ML-based AIDD
1. Machine Learning
(1) Types of Machine Learning:
①Supervised Learning
②Unsupervised Learning
③ Reinforcement Learning
(2) Typical Machine Learning Methods
①Decision Tree
② Support Vector Machine
③Naive Bayes
④Neural Network
⑤Convolutional Neural Network
(3) Evaluation and Validation of the Model
(4) Classification Evaluation: Accuracy, Precision, Recall, F1 Score, ROC Curve, AUC Calculation
(5) Regression Evaluation: Mean Absolute Error, Mean Squared Error, R2 Score, Explained Variance Score
(6) Cross-validation
2. Basic Usage of sklearn Toolkit
3.Basic Usage of RDKit Toolkit
4. Compound Coding Methods and Compound Similarity Theoretical Knowledge
5. Project Practice 1: Molecular Screening Based on ADME and Ro5
6. Project Practice 2: Ligand Screening Based on Compound Similarity
7. Project 3: Molecular Clustering Based on Compound Similarity
8. Project Practice 4: Biological Activity Prediction Based on Machine Learning
9. Project Practice 5: Machine Learning-Based Molecular Toxicity Prediction
Day Three GNN-based AIDD
1. Graph Neural Network
(1) Framework Introduction: PyG, DGL, TorchDrug
(2) Graph Neural Network Message Passing Mechanism
(3) Design of Graph Neural Network Datasets
(4) Practical Tasks for Graph Neural Network Node Prediction, Graph Prediction, and Edge Prediction
2. In-depth Paper Analysis: DeepTox: Toxicity Prediction Using Deep Learning
3.Project Practice 1: Molecular Toxicity Prediction Based on Graph Neural Networks
(1) Construction of PyG Graph Dataset from SMILES Molecular Dataset
(2) Molecular Toxicity Prediction Based on GNN
4. Project Practice 2: Prediction of Protein-Ligand Interactions Based on Graph Neural Networks
(1) Protein molecular graphing, constructing PyG graph dataset
(2) Network construction and interaction prediction based on GIN
Day 4 NLP-based AIDD
1.Natural Language Processing
(1) Encoder-Decoder Model
(2) Recurrent Neural Network RNN
(3)Seq2seq
(4)Attention
(5)Transformer
2.Project Practice 1: Molecular Toxicity Prediction Based on Natural Language
(1)SMILES Molecular Dataset Word Vector Representation Method
(2) Molecular Toxicity Prediction Based on NLP Model
3.Project Practice 2: Prediction of Organic Chemical Reaction Yields Based on Transformer (Prediction of chemical reaction yields using deep learning)
4. In-depth Paper Reading and Code Explanation: "Mapping the space of chemical reactions using attention-based neural networks"
Course Objectives

AIDD Artificial Intelligence Drug Discovery and Design Course: Allow students to understand the frontier background of drug discovery, learn various common algorithms in the field of artificial intelligence, become familiar with the installation and use of toolkits, master certain algorithm programming skills, and be able to apply computational methods to study drug-related problems. Through extensive case explanations and hands-on practice, students will gain the ability to construct AIDD models and perform data analysis.
Training Process

So far, it has held more than 30 sessions, with over 2,800 participants. The attendees have consistently expressed high satisfaction, filling the gap in AI-driven drug discovery technology in China.
Target Audience

Currently, AIDD drug research and development design targets a wide range of human bodies, such as CADD, drug design, pharmaceuticals, drug development, drug screening, new drug development, medicinal chemistry, biopharmaceuticals, immunology, natural products, veterinary drug development, bioinformatics, traditional Chinese medicine pharmacology, traditional Chinese medicine chemistry, network pharmacology, structural pharmacology, food safety, food flavor, food and drug development, food development, anti-tumor drugs, tumor immunity, enzyme engineering, genetics, antibody drugs, agricultural engineering, chemistry, organic synthesis, organic chemistry, structural biology, synthetic biology, and many other researchers.
Training Architecture

1. Course Features -- Comprehensive coverage of course technology applications, principles and processes, and practical examples.
2. Learning Mode -- Combining theoretical knowledge with hands-on operation, enabling beginners to quickly master the skills.
3. Course Service Q&A -- The main lecturer will provide professional answers to the problems you encounter in your actual work.
Instructor

AIDD Instructor, with over a decade of experience in computer algorithm research and program design. Research areas include bioinformatics, deep learning, drug target identification, and adverse drug reactions. Participated in two National Natural Science Foundation of China projects and led three provincial-level scientific research projects. As the first author, published several SCI papers in well-known journals such as BMC Bioinformatics, Journal of Biomedical Informatics, and International Journal of Molecular Sciences.


Course Schedule

Deep Learning Protein Design Class Time

2024.06.08-2024.06.09(9:00-11:30)--(13:30-17:00)
2024.06.15-2024.06.16(9:00-11:30)--(13:30-17:00)
2024.06.22-2024.06.23(9:00-11:30)--(13:30-17:00)
2024.06.29(9:00-11:30)--(13:30-17:00)
A total of 7 days of classes via Tencent Meeting live stream, online hands-on practice, with all sessions recorded.
CADD Computer-Aided Drug Design Class Time

2024.06.08-2024.06.09(9:00-11:30)--(13:30-17:00)
2024.06.15-2024.06.16(9:00-11:30)--(13:30-17:00)
2024.06.22-2024.06.23(9:00-11:30)--(13:30-17:00)
2024.06.29(9:00-11:30)--(13:30-17:00)
A total of 7 days of classes via Tencent Meeting live stream, online hands-on practice, with all sessions recorded and provided.
AIDD Artificial Intelligence Drug Discovery and Design Class Schedule

2024.06.11-2024.06.14 (19:00-22:00)
2024.06.17-2024.06.20(19:00-22:00)
2024.06.24-2024.06.27(19:00-22:00)
A total of 6 days of classes through Tencent Meeting live streaming, online practical operations.Provide full recording
Training Costs and Benefits
Course Registration Fee:
Deep Learning Protein Design:
Public Price: ¥6880 per person per class (including registration fee, training fee, materials fee, and provision of full post-class playback materials)
Self-funded Price: ¥6480 per person per class (including registration fee, training fee, materials fee, and provision of full post-class playback materials)
CADD Computer-Aided Drug Design and AIDD Drug Discovery and Design:
Public Fee: ¥5,880 per person per class (including registration fee, training fee, materials fee, and provision of full post-class playback materials)
Self-funded price: ¥5,480 per person per class (including registration fee, training fee, materials fee, and provision of full post-class playback materials)
Heavyweight Discounts:
Buy Two, Get One Free (Sign up for two classes and get one free learning slot, the free class can be chosen freely)
Buy Four, Get Two Free (Sign up for four classes at the same time and get two free learning spots; the free classes can be chosen freely.)
Offer 1:
Two Classes Together: 10,880 RMB (Original Price: 18,640 RMB)
Three Classes Together: 14,880 RMB (Original Price: 23,620 RMB)
Special offer: 24,880 yuan for one year of free study (You can study any course hosted by our organization for free within one year)
Special Offer: Two Years of Free Study (28,880 RMB for two full years of any courses offered by this institution)
Offer 2: Early registration and payment can enjoy a 300 yuan discount (limited to fifteen participants).
Register for a course and get access to past course replays for free (the number of courses you register for equals the number of replays you receive).
(Click to jump to the detailed link):
Replay One:Machine Learning Biomedicine
Replay Two:Machine Learning Single-Cell Analysis Special Topic
Replay Three:Single-Cell Spatial Transcriptomics Special Topic
Replay Four:Comparative Genomics Topic
Playback Five:Machine Learning Proteomics Special Topic
Replay Six:Machine Learning Microbiology Special Topic
Replay Seven:Protein Crystal Structure Analysis
Playback Eight:Machine Learning Metabolomics Technology


1. Course Features -- Comprehensive application of course technology, principles and processes, and practical examples throughout.
2. Learning Mode -- Combining theoretical knowledge with hands-on operation, enabling beginners to quickly master the skills.
3. Course Service Q&A -- The main instructor will provide professional answers to the questions you encounter in your actual work.
Teaching Method: Online live streaming via Tencent Meeting, theory+Hands-on teaching mode, where the teacher guides students step by step through operations.Starting from scratch, electronicPPTAnd TutorialsOne week before the course starts, all training software will be sent to the students in advance. If there are any questions, they can be resolved through voice communication, screen sharing, and WeChat group discussions. Students and teachers can communicate with each other, as well as students with other students. After the training is completed, the teacher will continue to answer questions for a long time, and the training group will not be disbanded. Past trainees have consistently given very high evaluations of the training quality and teaching methods!

Tencent Meeting Live Streaming Q&A | Step-by-Step Guidance

Trainees Give High Evaluation to the Training

Trainees Publish in Top Journals After Training


Quoting a sentence from one of the participants at this conference:

Previous Participating Units
▼
Foreign university departments;From MIT, University of Bristol, UC Berkeley, Osaka University, George Mason University, Caltech, University of Manchester, Rice University, Boston University, Texas A&M University, Drake University, American Union University, Princeton University, Stanford University, Imperial College London, KAUST University, Lehigh University, The University of Queensland, The University of Queensland Australia, Yale University, University of Oxford, University of Cambridge, University of Pittsburgh, University of Sydney, University of Toronto, University of Washington Seattle, University of London, Duke University, University of Tokyo, Columbia University, Cornell University, New York University, Northwestern University, Brown University, University of Washington, etc.
Domestic Colleges and Universities; Participants include over 5,000 students from Sun Yat-sen University, Tsinghua University, Zhejiang University, Peking University First Hospital, Peking Union Medical College Hospital of the Chinese Academy of Medical Sciences, Northwest Minzu University, Southwest University, Shandong University, Qiyuan Laboratory, The First Medical Center of the PLA General Hospital, Guangdong Ocean University, Wuhan University, China Agricultural University, Henan Normal University, Nanjing Tech University, Shanghai Jiao Tong University, Southern University of Science and Technology, Nanjing University, Institute of Basic Medical Sciences of the Chinese Academy of Medical Sciences, Qinghai Academy of Agriculture and Forestry Sciences, First Teaching Hospital of Tianjin University of Traditional Chinese Medicine, Shandong University, Heilongjiang Bayi Agricultural University, Second Affiliated Hospital of Nanchang University, Taizhou Central Hospital (Affiliated Hospital of Taizhou University), People's Hospital Affiliated to Ningbo University, Xinjiang Agricultural University, Beijing Forestry University, Guangxi Medical University, Hunan University of Arts and Science, Binzhou Medical University, Binzhou Medical University Yantai Affiliated Hospital, South China Normal University, Chinese Research Academy of Environmental Sciences, Yunnan Normal University, Kunming University of Science and Technology, Hubei University of Medicine, Lingang Laboratory, Soochow University, Fuzhou University, Nanfang Hospital, Second Affiliated Hospital of Nanchang University, Shenzhen Traditional Chinese Medicine Hospital, Hunan University of Arts and Science, Henan Institute of Science and Technology, Fujian Provincial Hospital, Xiangya Hospital of Central South University, Shenzhen Traditional Chinese Medicine Hospital, Tongde Hospital of Zhejiang Province, Baotou Teachers College of Inner Mongolia University of Science and Technology, Urumqi Center for Disease Control and Prevention, Research Institute of Forestry of the Chinese Academy of Forestry, Lanzhou Institute of Animal Husbandry and Veterinary Medicine of the Chinese Academy of Agricultural Sciences, Ludong University, Hebei University of Engineering, Zhujiang Hospital of Southern Medical University, Beijing Obstetrics and Gynecology Hospital Affiliated to Capital Medical University, Second Affiliated Hospital of Chongqing Medical University, Shanghai Medical College of Fudan University, Affiliated Hospital of Shaanxi University of Traditional Chinese Medicine, Blood Diseases Hospital of the Chinese Academy of Medical Sciences (Institute of Hematology of the Chinese Academy of Medical Sciences), Peking University Shenzhen, Hong Kong University of Science and Technology Medical Center, Tianjin Cancer Hospital, Army Medical Specialty Center, First Affiliated Hospital of Air Force Medical University, Jiangnan University, Shenzhen Institutes of Advanced Technology of the Chinese Academy of Sciences, as well as many companies, research institutes, and universities! Thank you for your recognition of our training program! Many others could not attend due to scheduling conflicts. This time, we sincerely invite you to participate!