
Large pre-trained models have become foundational models leading breakthroughs in natural language processing and related fields.Developing foundational models for deciphering cellular "language" and advancing biomedical research is promising but also challenging.
June 6, 2024, Tsinghua UniversityZhang Xuegong,Ma Jianzhu and BioMap (BioMap) Song Le co-corresponding author inNature Methods Published online with the title "Large-scale foundation model on single-cell transcriptomics"Research Paper,The study developed a large pre-trained model called scFoundation, also named "xTrimoscFoundationα," which has 100 million parameters, covers approximately 20,000 genes, and was pre-trained on over 50 million human single-cell transcriptome profiles.
scFoundation is a large-scale model in terms of the size of trainable parameters, the dimensionality of genes, and the amount of training data. Its asymmetric transformer-based architecture and pre-trained task design can effectively capture the complex contextual relationships between genes across various cell types and states.Experiments show that it is a foundational model that can achieve state-of-the-art performance in a variety of single-cell analysis tasks, such as gene expression enhancement, tissue drug response prediction, single-cell drug response classification, single-cell perturbation prediction, cell type annotation, and gene module inference.
 Large-scale pre-trained models are revolutionizing research in natural language processing-related fields, becoming a new paradigm for general artificial intelligence research. These models, trained on vast corpora, have become foundational due to their essential role in breakthroughs across many downstream tasks and their ability to identify patterns and entity relationships in language. In the life sciences, organisms have their underlying "language."Cells are the basic structural and functional units of the human body, with "sentences" composed of countless "words" such as DNA, RNA, proteins, and gene expression values. An interesting question is: Can a foundational model for cells be developed based on a large number of cellular "sentences"?Single-cell RNA sequencing (scRNA-seq) data, also known as single-cell transcriptomics, provides high-throughput observations of cellular systems and offers extensive transcriptomic profiles for all types of cells to establish foundational models. In transcriptomic data, gene expression profiles describe the complex system of gene-gene co-expression and interactions within cells. With the efforts of the Human Cell Atlas (HCA) and many other studies, the scale of data is growing exponentially. Among millions of cells with approximately 20,000 protein-coding genes, the observed scale of gene expression values reaches trillions of "tokens," comparable to the volume of natural language text used for training large language models (LLMs), such as Generative Pre-trained Transformers.This provides a foundation for people to pre-train large-scale models to extract complex, multi-faceted intracellular patterns in a manner similar to how legal master's students learn human knowledge from vast amounts of natural language text.
Large-scale pre-trained models are revolutionizing research in natural language processing-related fields, becoming a new paradigm for general artificial intelligence research. These models, trained on vast corpora, have become foundational due to their essential role in breakthroughs across many downstream tasks and their ability to identify patterns and entity relationships in language. In the life sciences, organisms have their underlying "language."Cells are the basic structural and functional units of the human body, with "sentences" composed of countless "words" such as DNA, RNA, proteins, and gene expression values. An interesting question is: Can a foundational model for cells be developed based on a large number of cellular "sentences"?Single-cell RNA sequencing (scRNA-seq) data, also known as single-cell transcriptomics, provides high-throughput observations of cellular systems and offers extensive transcriptomic profiles for all types of cells to establish foundational models. In transcriptomic data, gene expression profiles describe the complex system of gene-gene co-expression and interactions within cells. With the efforts of the Human Cell Atlas (HCA) and many other studies, the scale of data is growing exponentially. Among millions of cells with approximately 20,000 protein-coding genes, the observed scale of gene expression values reaches trillions of "tokens," comparable to the volume of natural language text used for training large language models (LLMs), such as Generative Pre-trained Transformers.This provides a foundation for people to pre-train large-scale models to extract complex, multi-faceted intracellular patterns in a manner similar to how legal master's students learn human knowledge from vast amounts of natural language text.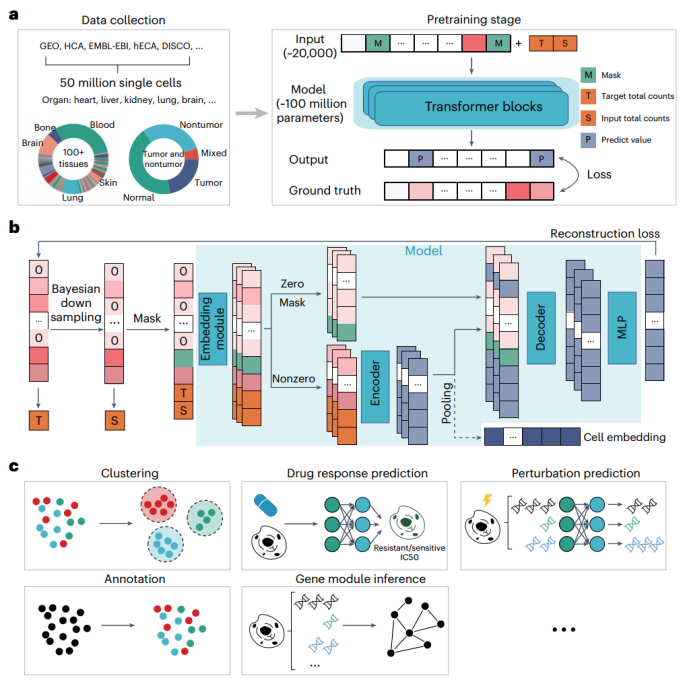 Overview of the pre-training framework (Figure source:Nature Methods )In LLM pre-training, the growth in model and data scale is crucial for building foundational models capable of effectively uncovering complex, multi-layered internal relationships. Recently, progress has been made in pre-trained models for single-cell data, but creating large-scale foundational models still faces unique challenges. First, gene expression pre-training data needs to encompass cellular landscapes of different states and types. Currently, most scRNA-seq data is loosely organized, lacking a comprehensive and complete database. Second, when modeling each cell as a sentence and each gene expression value as a word, the nearly 20,000 protein-coding genes make this "sentence" exceptionally long, a situation that traditional transformers struggle to handle. Existing studies often have to limit their models to a small list of selected genes. Third, scRNA-seq data from different technologies and laboratories shows significant variation in sequencing read depth.Unlike random noise caused by technical effects (e.g., pollution), read depth is not random, and its variation hinders the model from learning unified and meaningful cell and gene representations.The study designed a large foundational model, scFoundation, with 100 million parameters for approximately 20,000 genes. The research collected over 50 million gene expression profiles from scRNA-seq datasets for pre-training. An asymmetric architecture was developed for scRNA-seq data to accelerate the training process and enhance the model's scalability. Additionally, a Read Depth-Aware (RDA) modeling pre-training task was designed, enabling scFoundation to not only simulate gene co-expression patterns within cells but also connect cells with varying read depths.All results demonstrate the capability and value of scFoundation in transcriptomics data analysis, as well as its fundamental functions in facilitating biological and medical task learning. This work explores and pushes the boundaries of foundational models in the single-cell domain.https://doi.org/10.1038/s41592-024-02305-7
Overview of the pre-training framework (Figure source:Nature Methods )In LLM pre-training, the growth in model and data scale is crucial for building foundational models capable of effectively uncovering complex, multi-layered internal relationships. Recently, progress has been made in pre-trained models for single-cell data, but creating large-scale foundational models still faces unique challenges. First, gene expression pre-training data needs to encompass cellular landscapes of different states and types. Currently, most scRNA-seq data is loosely organized, lacking a comprehensive and complete database. Second, when modeling each cell as a sentence and each gene expression value as a word, the nearly 20,000 protein-coding genes make this "sentence" exceptionally long, a situation that traditional transformers struggle to handle. Existing studies often have to limit their models to a small list of selected genes. Third, scRNA-seq data from different technologies and laboratories shows significant variation in sequencing read depth.Unlike random noise caused by technical effects (e.g., pollution), read depth is not random, and its variation hinders the model from learning unified and meaningful cell and gene representations.The study designed a large foundational model, scFoundation, with 100 million parameters for approximately 20,000 genes. The research collected over 50 million gene expression profiles from scRNA-seq datasets for pre-training. An asymmetric architecture was developed for scRNA-seq data to accelerate the training process and enhance the model's scalability. Additionally, a Read Depth-Aware (RDA) modeling pre-training task was designed, enabling scFoundation to not only simulate gene co-expression patterns within cells but also connect cells with varying read depths.All results demonstrate the capability and value of scFoundation in transcriptomics data analysis, as well as its fundamental functions in facilitating biological and medical task learning. This work explores and pushes the boundaries of foundational models in the single-cell domain.https://doi.org/10.1038/s41592-024-02305-7
—END—
Content is【iNature】Original article from the WeChat Official Account,
Please indicate the source of the reprint.【iNature】
WeChat Group Addition
iNature has gathered 40,000 researchers and doctors in the life sciences. We have formed 80 integrated groups (16 PI groups and 64 PhD groups), and additionally created specialized professional groups related to specific fields (such as plants, immunity, cells, microbiology, gene editing, neuroscience, chemistry, physics, cardiovascular, oncology, etc.).Reminder: Please leave a note when joining the group (in the format of School + Major + Name; if you are a PI/Professor, please...IndicatesPI/Professor, otherwise directlyDefault is a Ph.D. candidate, thank you)。You can first add the WeChat ID of the editor (love_iNature), or long press the QR code to add the editor, then join the relevant group. Serious inquiries only.


Submission, Cooperation, and Reproduction Authorization Matters
Please contact WeChat ID:13701829856Or email:iNature2020@163.com
If you find this article interesting, please click here!
