Miracles can really happen with great effort! Large models are bringing more and more surprises to the life sciences.Recently,Enveda BiosciencesOfficially announced a product namedPRISMThe large model of life chemistry,The model in1.2 billionSmall molecule mass spectrometry training was conducted, with a total token count as high as 85 billion, which isThe Largest Small Molecule Mass Spectrometry Training Set to Date。The company believes that PRISM represents the "state-of-the-art" in predicting the chemical composition of biological samples.More importantly, this achievement also reveals to a certain extentScaling lawThe manifestation of (scaling laws) in this field, researchers say,The performance of PRISM continues to improve as the training set size expands, rather than plateauing.Enveda Biosciences, founded in 2019, leverages large-scale metabolomics and artificial intelligence to significantly accelerate the discovery process of natural molecules. The company's total financing has now reached$175 million。Enveda stated,Billions of Molecular Mass Spectra Are Just the Beginning, the scale and diversity of future company's experimental data will further expand, which will help decode chemical reactions in nature, thereby promoting new drug development. Know molecules like knowing a language
Know molecules like knowing a language
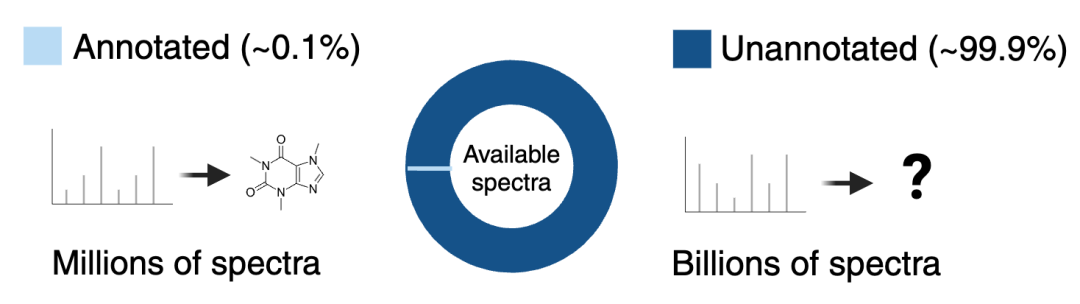
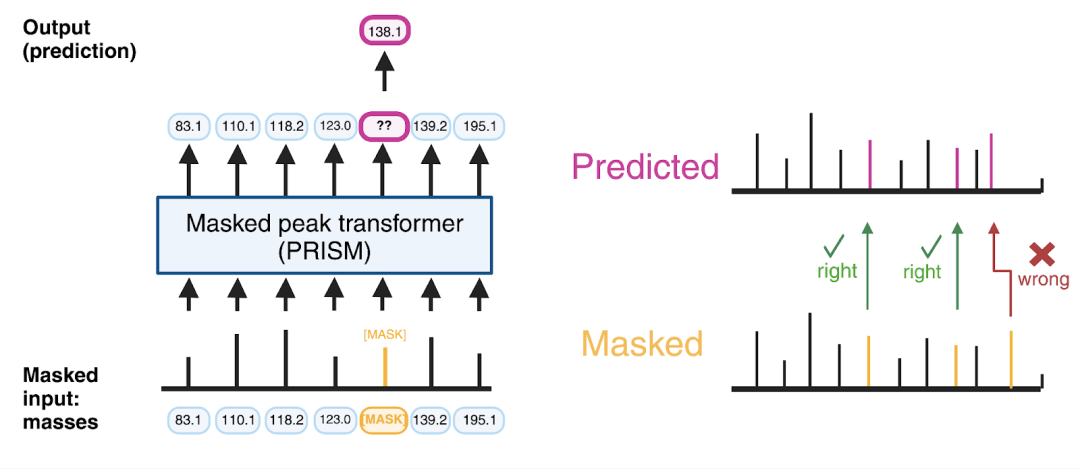
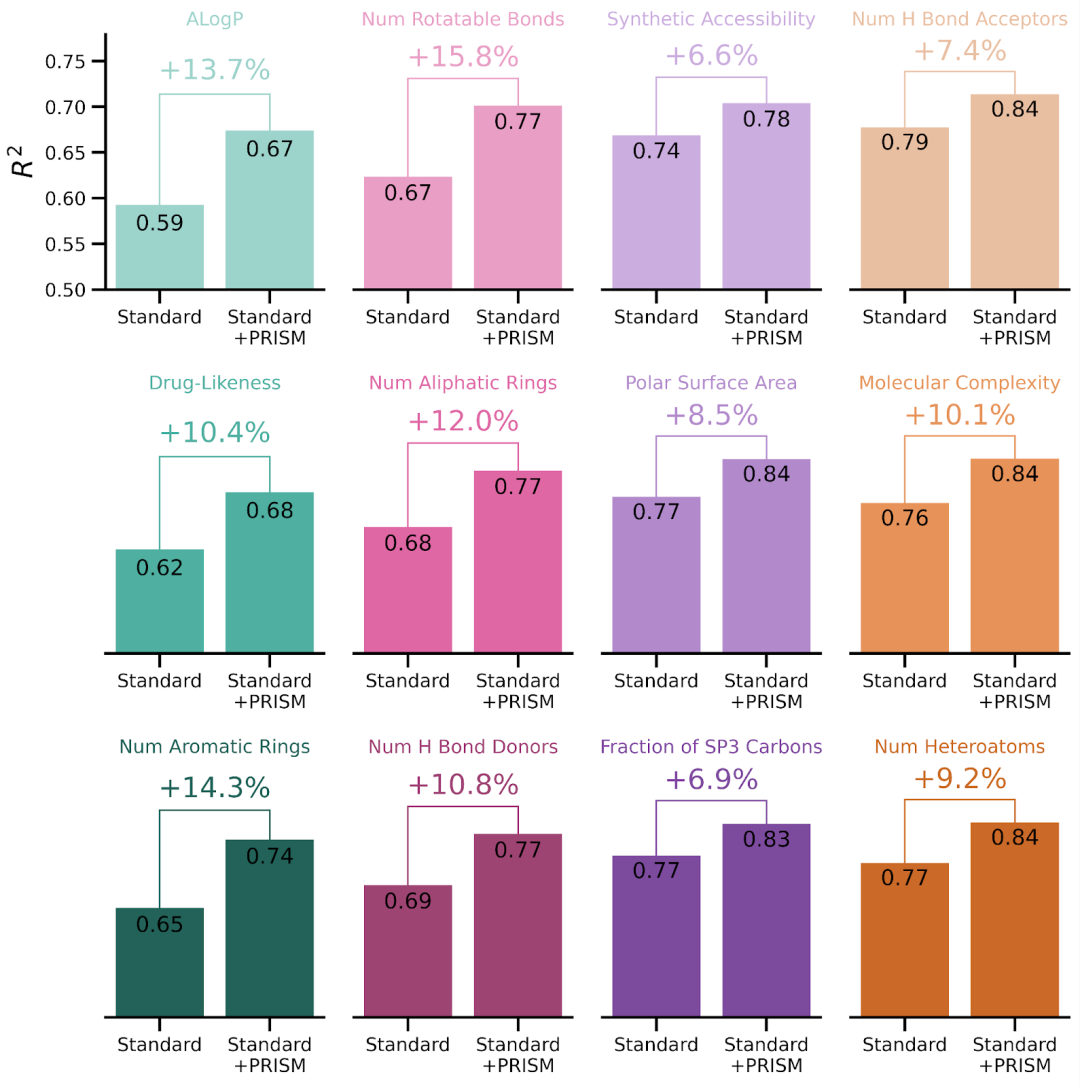
In natureAs many as 99.9% of small molecules remain unknown to people.This is because most natural molecules exist in complex mixtures, representing the largest untapped resource for new drugs on Earth.Mass spectra can accelerate molecular identification since they allow for the simultaneous acquisition of information on many novel molecules in a mixture, but the key challenge lies in the difficulty of interpreting mass spectral data.Most computational tools developed to interpret mass spectrometry data are trained on annotated reference spectra of known molecules (translator's note: i.e., supervised learning), and this dataset represents only a small fraction of all biochemical reactions in living systems.In recent years, the emergence of large-scale pre-trained foundational models represented by GPT has become one of the most influential advancements in artificial intelligence. Behind such a significant breakthrough lies a technology calledThe technology of self-supervised learning, which enables models to be trained on unlabeled datasets, greatly broadening the data sources.So, can this technology be applied to the field of molecular mass spectrometry? After all, compared to repositories like NIST or MoNA, which contain approximately a few million annotated mass spectrometry data, unannotated data repositories (such as MetaboLights) often reach hundreds of millions in size, providing a broader range of samples for training models.Following this line of thought, Enveda has developed a foundational model named PRISM,This model adopts a self-supervised learning strategy on a large unannotated spectral database, which can significantly improve the downstream prediction performance of molecular identity.According to the disclosure, the architecture of PRISM originated from Google's development.BERT(Bidirectional Encoder based on Transformer) model, modified and adjusted by Enveda to suit tandem mass spectrometry.As the Masked Language Model (MLM) in BERT "masks" one or more parts of a sentence and requires the model to predict the missing parts based on the context of the other parts, PRISM also adopts a similar approach. However, what PRISM masks are not words, but mass values.Specifically, for each example mass spectrum (composed of masses and intensities produced by molecular decomposition, represented as "peaks" in MS2), researchers randomly mask 20% of the peak masses. The model's task is to predict the masses of the missing peaks based on the context of the remaining peaks, thereby learning the patterns.To train PRISM, Enveda has collected the largest training set of small-molecule mass spectrometry to date, including 1.2 billion high-quality small-molecule spectra.About half of them come from three major public data repositories (GNPS, MetaboLights, Metabolomics Workbench), while the other half come from Enveda's internal metabolomics platform.It is reported that GleaMS and LSM1-MS2 models, which have similar ideas to PRISM, were also released not long ago, but their mass spectrometry training quantities are 40 million and 100 million respectively. In comparison,PRISM's dataset is an order of magnitude larger.Next, the researchers tested PRISM's ability to predict molecular chemical properties. The results showed that, using the same data, the predictive performance of machine learning models pre-trained with PRISM significantly improved, with a relative increase in R-squared between actual and predicted values.7%-16%。Not only that, the team also tested PRISM's task of finding the closest match in the spectral reference library to improve predictions of unknown spectral structures. Compared with machine learning models that did not use PRISM pre-training, the relative improvement rate was23%。Enveda stated that the company uses this model for screening and continuously repeats the process to find molecules with drug-like properties, which means faster drug discovery. Founded by the former Recursion product manager
Founded by the former Recursion product manager
In 2019, Viswa Colluru founded Enveda after leaving Recursion.As one of the earliest AI pharmaceutical companies to go public globally,Recursion Focuses on Transforming the Phenotypic Screening Process for New Drug Discovery by Leveraging Machine Learning and High-Throughput Cellular Imaging and Measurement, with Strengths in Biological Data Generation and Computation.。The former employer’s emphasis on AI and data undoubtedly left a deep impression on Viswa Colluru, so he set his sights on natural molecules. In his view, the chemicals in nature, accumulated through billions of years of evolution, have left humanity with a vast and rich treasure trove.
Starting from this original intention, the Enveda he founded focuses on the chemical space of natural products and their derivatives, using large-scale metabolomics and artificial intelligence to significantly accelerate the discovery process of natural molecules.Enveda has made remarkable progress in this area, successively launching the first internal knowledge graph algorithm for drug prioritization and a model designed to predict the structures of natural cellular metabolites.AndThe launch of PRISM marks an important step for the company in building high-throughput screening processes., which will help to quickly test the drug properties of natural molecules and promote the development of potential drugs.While continuously optimizing and perfecting the technology platform, the company is alsoAdvance its multiple pipelinesThe company is developing drugs targeting multiple pathways such as ALK5, NLRP3, and TGR5, with indications including pain, itching, and inflammation. The company plans to submit the first three IND applications by the end of 2023.However, it seems that currently,Enveda's drug development does not seem to be going as smoothly as expected.According to the official website, the company may currently have only one pipeline that has potentially submitted an IND application, while the other two have shown no progress compared to before. In conclusion
In conclusion
Life sciences are becoming an important application area for large models, and one of the driving forces behind this trend is the belief of many elites in the scaling law.The scaling law, initially discovered by OpenAI, has now become the most well-known principle in the artificial intelligence industry and is regarded by Microsoft's CEO as the true driving force behind the AI revolution.In simple terms, Scaling law refers to the idea that as long as the data volume and computational power are large enough, model performance can be greatly improved, achieving unexpected results.This rule, full of violent aesthetics, has been proven by large language models, but whether it applies to the biological field, and how large biological models need to be to achieve this breakthrough, remains inconclusive.Enveda's exploration has provided us with a preliminary answer to the former question, and the researchers stated that the performance of PRISM continues to improve as the scale of the training set expands.Its unprecedented number of parameters offers a glimpse into the vast potential of Scaling law in the life sciences.Who would be thrilled by this news? I think no one else but Jensen Huang. As the scaling law plays an increasingly significant role in the biological field, the resulting massive biological data and computing power demands will provide Nvidia with considerable revenue growth.Conversely,If large biological models can truly achieve extraordinary results through immense effort, and if we can understand a cell as easily as understanding a word, we will usher in a new era of life science development.—The End—
Recommended Reading