World-Leading DPA4 Model by DP Technology and Partners Tops Matbench Discovery and SPICE-MACE-OFF

DP Technology
Simulation R&D Platform Developer

The competition in large atomic models is shifting from "who is bigger" to "who is stronger, faster, and cheaper."
Recently,DP Technology, as a core contributor, closely collaborates with partners such as the Beijing Academy of Artificial Intelligence, Peking University, and the Beijing Institute of Applied Physics and Computational Mathematics.,Relying on an open and collaborative scientific research cooperation ecosystem, jointly launchedNext-Generation Model Architecture DPA4 for the Large Atomic Model (LAM) Era。
In the international authoritative ranking of material discoveryOn Matbench Discovery,DPA4 Comprehensive Performance MetricsCPS Ranks First in the World, Becoming the Latest SOTA Model。
More notably, DPA4 did not reach the top by piling up parameters or computational power. Compared to the previously leading model eSEN, which required over 300 GPU days for training, DPA4 theoretically needs only about one day of training on a single RTX 5090 to achieve the same level of accuracy, while its number of parameters is less than one-tenth of eSEN’s.
In other words, the SOTA accuracy that previously required a "supercomputing budget" to achieve can now potentially be compressed to run on a consumer-grade GPU. DPA4 is redefining the "accuracy-efficiency" Pareto frontier for large atomic models.
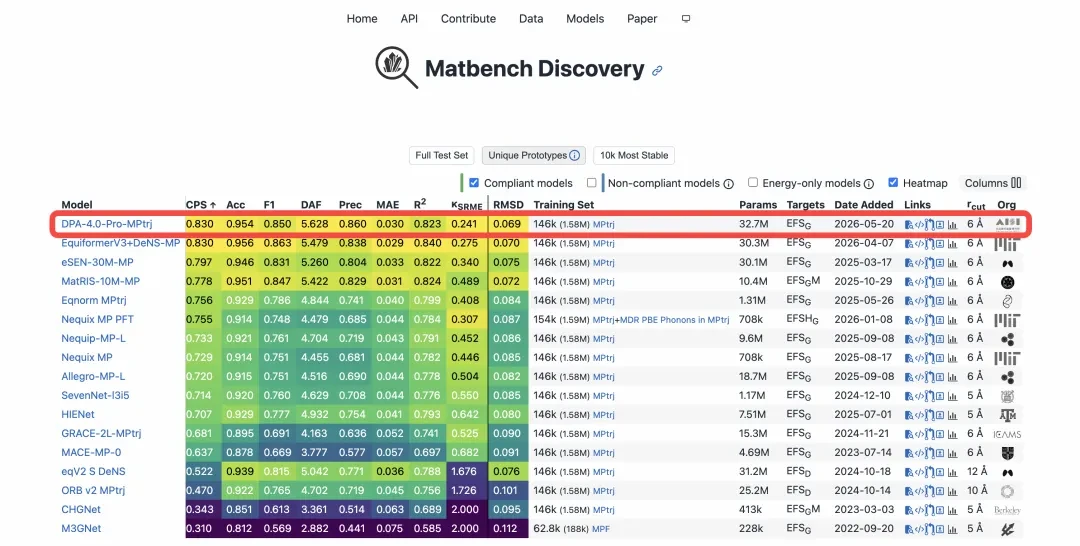
Official Screenshot of Matbench Discovery, Data as of May 22, 2026
DPA4 adopts the design of SO(2) equivariant linear operators in a local coordinate system combined with an attention mechanism, which significantly reduces the computational cost of equivariance while strictly satisfying translation, rotation, permutation symmetry, and energy conservation.And achieved the compile training of machine learning potential functions for the first time worldwide, increasing the training speed by 2-3 times.. In the international authoritative list in the field of material discoveryMatbench DiscoveryCompared with Small Molecules BenchmarkSPICE-MACE-OFFAbove,DPA4 has achieved new SOTA results, ranking first in the world.。
Notably, DPA4 has simultaneously reached a new Pareto frontier in both prediction accuracy and training cost:Theoretically, it only requires training for about one day using a single RTX 5090 graphics card., it can achieve the accuracy level that eSEN previously required over 300 GPU days to attain, with less than 1/10 of the parameters; and at the same accuracy level, itsTraining efficiency has improved approximately 10 times compared to the previous generation DPA3.。
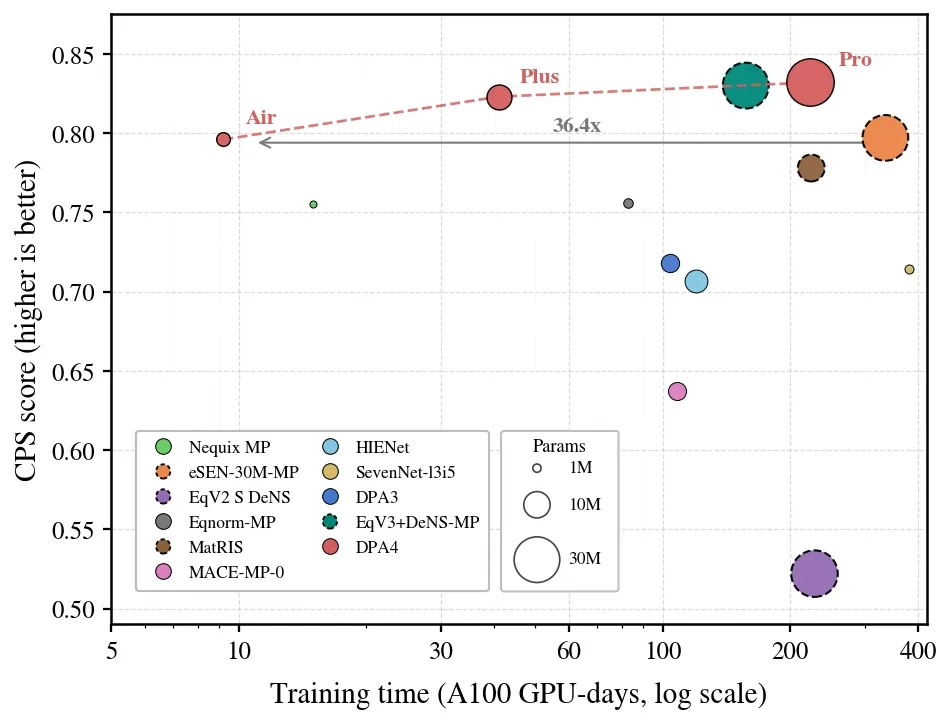
DPA4 Reconstruction of Large Atomic Model "Accuracy-Efficiency" Pareto Frontier (Including Other Direct Force Pre-trained Models)
Currently, DPA4 has been made available for early access to the Deep Modeling community. The paper and official version will be open-sourced subsequently. Researchers are welcome to stay tuned and join the WeChat group at the end of the article for communication. Below is a detailed introduction to DPA4.

DPA4 Model Structure:
In the local coordinate system
SO(2) Equivariant Design
For a long time, in order to maintain rotational symmetry in the global coordinate system, equivariant models have had to rely on Clebsch–Gordan tensor products to couple geometric features of different orders, with computational complexity increasing with the angular momentum order.Sharp increase (approximately, which is the fundamental reason why high-precision equivariant model calculations are expensive.
The core idea of DPA4 is:Instead of undertaking expensive tensor products in the global coordinate system, it is better to "reduce" the symmetry to simpler subgroups for processing.。Specifically, for each edge between atoms, DPA4 constructs a smooth local coordinate system, aligning the direction of the edge to a unified reference axis. In this local coordinate system, the rotational equivariance that originally needed to be handled over the entire SO(3) group is reduced to handling only the SO(2) subgroup corresponding to rotations around the axis—where SO(2) is an Abelian group with an extremely concise block structure for its equivariant linear mappings. Consequently, the costly SO(3) tensor product is equivalently replaced by an efficient SO(2) Equivariant Linear Operator, while strictly maintaining complete rotational equivariance, the computational cost of angular calculations is significantly reduced.
On this basis, DPA4 further introducesAttention MechanismCompletion of Neighbor Information Aggregation: The model can adaptively "focus" on the most critical interactions for the central atom based on local geometry and chemical environment, achieving strong expressive power within a compact parameter scale. The entire model strictly satisfies translation, rotation, permutation symmetry, and energy conservation, fully ensuring physical consistency.
In addition to the design at the algorithm level, DPA4 is also optimized for efficiency in engineering implementation:
Native torch.compile Support: The model has been compiler-friendly since its inception, and can be directly assisted by
torch.compileAchieve significant end-to-end acceleration without additional rewriting.Native ZBL Short-Range Potential: DPA4 natively integrates the ZBL repulsive potential, smoothly connecting short-range physical behaviors, making the model more robust and reliable under extreme configurations such as high pressure, irradiation, and defects.
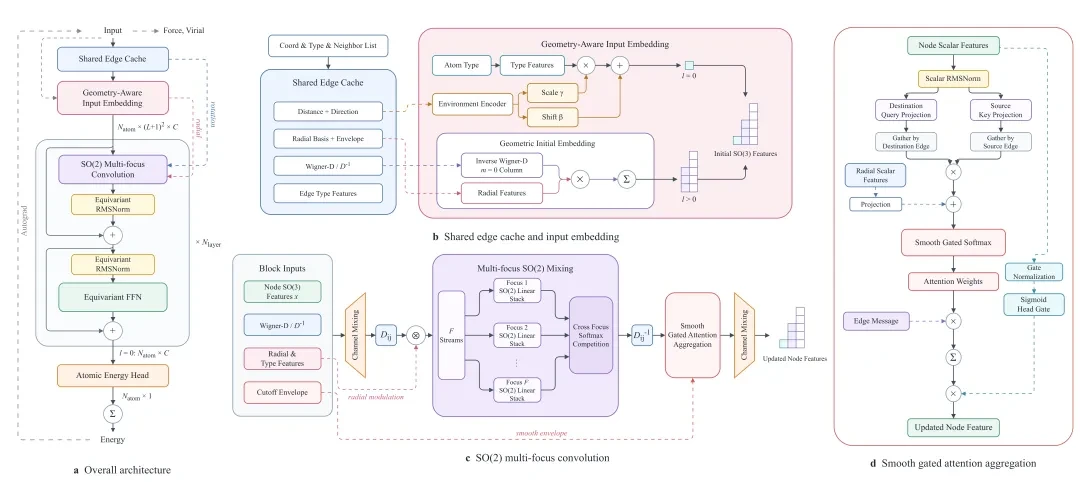
DPA4 Model Structure

Matbench Discovery
WITH SPICE-MACE-OFF
Both Reach the Summit
Material Discovery: Matbench Discovery Ranks First in the World。 Matbench Discovery, initiated by top institutions such as the University of California, Berkeley, and the University of Cambridge, is the most influential dynamic benchmark list in the field of global AI-driven inorganic material discovery. It is internationally recognized as the gold standard for evaluating the performance of intelligent models in materials science. Moving away from simple static data fitting, it adopts a forward-looking testing mechanism that requires models to predict the thermodynamic stability of hundreds of thousands of unknown crystals, authentically simulating the entire scientific research exploration process. Its evaluation system not only examines the prediction accuracy of energy and forces but also integrates multiple metrics such as F1 scores and discovery acceleration factors, ultimately converging into a comprehensive performance score, CPS. In the competition featuring the strongest models from Meta, Microsoft, and top universities worldwide, DPA4 achieved CPS Comprehensive Performance Ranks First in the World, becoming the latest SOTA model.
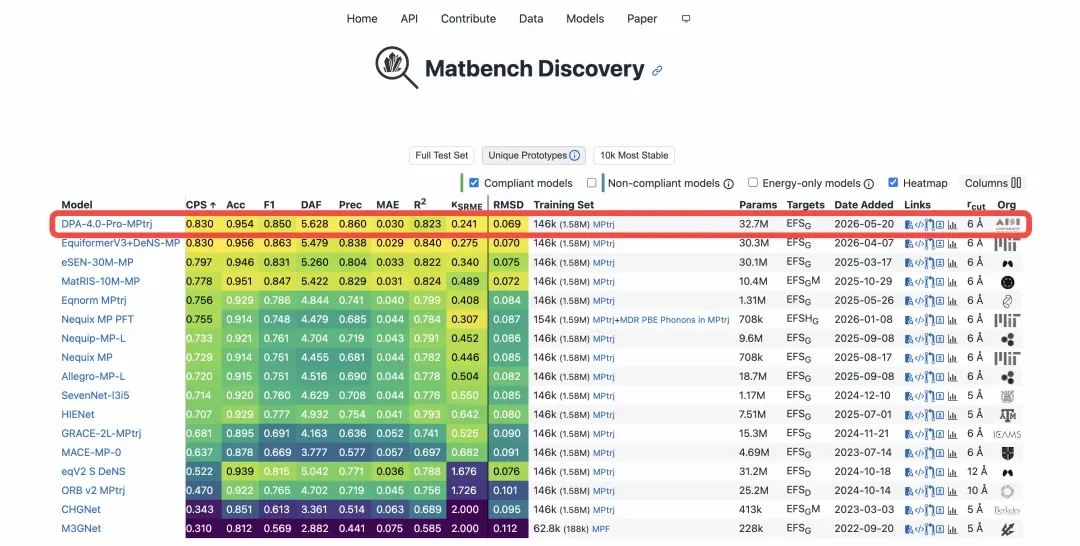
Official Screenshot of Matbench Discovery, Data as of May 22, 2026
Small Molecules: SPICE-MACE-OFF Also Leads the Way。 The advantages of DPA4 are not limited to inorganic crystals. On the authoritative benchmark SPICE-MACE-OFF in the molecular field, DPA4 achieved new SOTA results with fewer parameters.Outperformed the previously leading model eSEN, ranking first.From crystalline materials to organic small molecules, and from energy to force predictions, DPA4 demonstrates consistent superiority across systems and fields, further confirming its potential as a universal potential energy surface model.
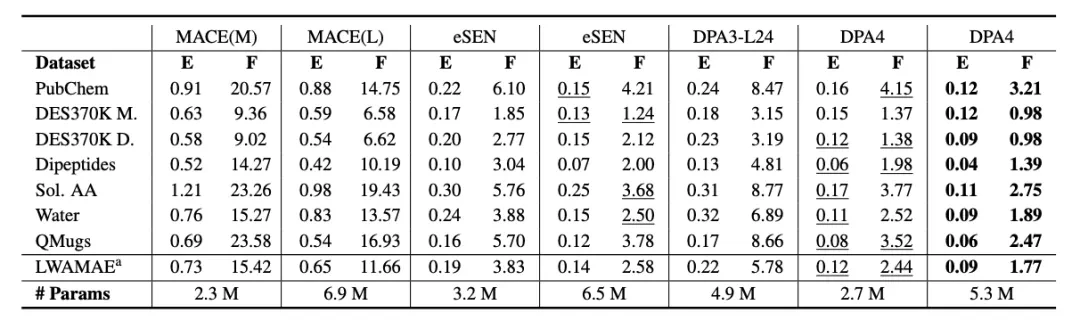
SPICE-MACE-OFF Performance

Efficiency Comparison:
Reconstructing "Precision-Efficiency"
Pareto Frontier
In the past, reaching the top of the rankings often meant larger parameter scales and higher training costs. DPA4, on the other hand, has simultaneously pushed the Pareto frontier in both accuracy and training cost:
Training Cost: In theory, only need Single consumer-grade RTX 5090 graphics card, trained for about one day, achieving the previous SOTA model on the listeSEN Cost More than 300 GPU days The level of precision that can be achieved;
Parameter Scale: Under the same CPS, the parameter volume of DPA4Less than one-tenth of eSEN;
Generational Improvement: At the same precision, the training efficiency of DPA4 has been further improved compared to the previous generation DPA3.About 10x。
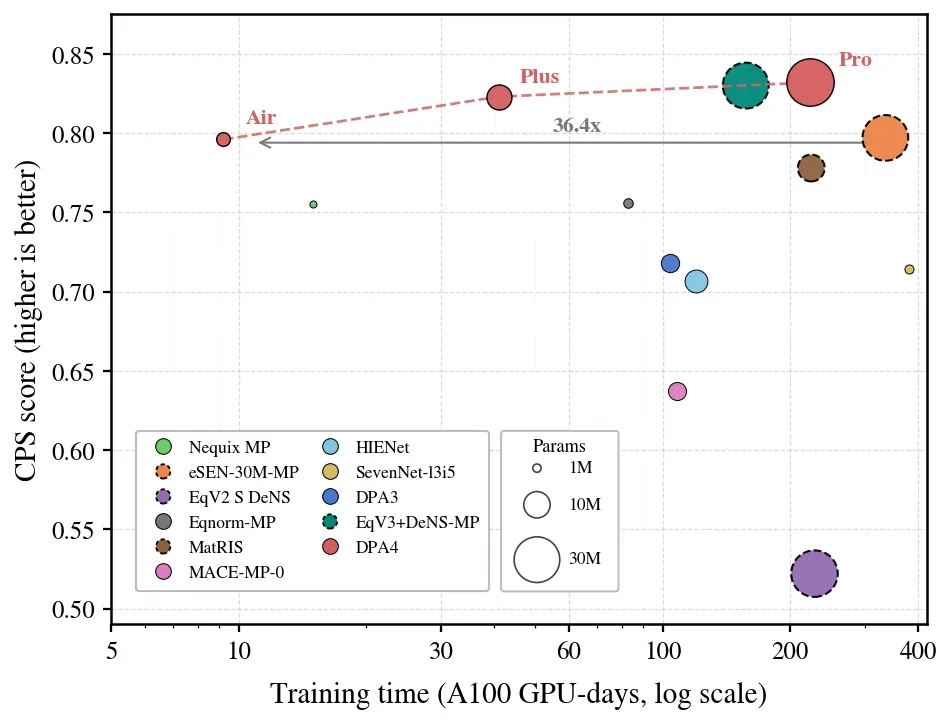
DPA4 Reconstruction of Large Atomic Models: The "Accuracy-Efficiency" Pareto Frontier
To achieve an order-of-magnitude improvement in efficiency, engineering optimization is essential. `torch.compile` provides a relatively cost-free boost in regular AI model training. However, in the training of machine learning potentials, force is the derivative of energy, making double backward necessary for potential function training, which `compile` does not support. As a result, for a long time, maximizing GPU utilization in machine learning potential training has relied solely on continuously increasing batch sizes. DPA4, developed by DP Technology, stands out globallyPioneering Native Support for torch.compile Compilation to Accelerate Training, and significantly reduce memory usage by autocasting to bf16 precision, providing a foundation for training larger models on a single card.。

Comparison of Training Time and Peak GPU Memory Usage for DPA4 with Compile and AMP Enabled
This result means that, with the same computing power budget, researchers are able to complete training and iteration faster, and simulate microscopic processes at larger scales and over longer time spans. DPA4 has brought large-scale, high-throughput atomic simulations from the realm of "computational luxury" into the domain of "daily usability," offering significant application value in fields such as battery materials, catalyst design, and semiconductor exploration.

Summary
On the Matbench Discovery and SPICE-MACE-OFF benchmarks, DPA4 has achieved the world's top ranking in both, reaching a new Pareto frontier in terms of accuracy and training cost — with less than one-tenth of the parameters and the training cost of a single GPU card in one day, it rivals or even surpasses expensive large models.DPA4 Powerfully Demonstrates:High Precision and High Efficiency: Never a Single-Choice Question。
The continuous evolution of DPA4 is inseparable from DP Technology's long-term construction of an open "industry-academia-research" ecosystem. Centered around the Deep Modeling open-source community, DP Technology continuously collaborates with universities, research institutions, developers, and industry partners, connecting cutting-edge algorithm research, open-source toolchain development, real-world industry scenario validation, and community-driven innovation to advance AI for Science from methodological breakthroughs towards reusable, scalable, and deployable infrastructure. Through open-source models, open-source software, open communication, and open collaboration, DP Technology aims to lower the barriers of scientific computing and innovation together with global researchers, accelerating the arrival of the large atomic model era.
Currently, DPA4 has been opened for early access to the Deep Modeling community, and the paper along with the official version will be open-sourced subsequently. On the journey towards the era of large atomic models, open source and openness have always been our persistent theme. We welcome all researchers to keep following, join the discussion, and explore together.
Main Developers and Units:
Tiancheng Li (Peking University, Beijing Academy of Artificial Intelligence)
Xuejian Ming (Peking University)
Zhang Linfeng (DP Technology, Beijing Academy of Artificial Intelligence)
Zhang Duo (Peking University, Beijing Academy of Artificial Intelligence)
Wang Han (Beijing Institute of Applied Physics and Computational Mathematics)

We sincerely invite you to join the Large Atomic Model Project. Add the administrator's WeChat to join the WeChat early access group for communication and discussion.
About DP Technology
