DeRui Pharma Releases PharmaBench: The World's Largest Single-Property ADMET Open Dataset Powered by Large Language Model Multi-Agent Systems

MindRank
AI Drug Developer
Recently, the "MindRank" team releasedThe World's Largest Single-Nature ADMET Open-Source Dataset: PharmaBench.The R&D team combined large language model multi-agent technology to buildA large dataset encompassing 11 key ADMET properties with a total of 52,482 data entries,The study was recently published in Scientific Data, a journal under Nature.

Currently, "MindRank" independently developed byADMET Property Prediction PlatformADMET Ranker™Has completed iterative upgrades based on large language models, and in third-party independent validations, the performance in prediction tasks for multiple drug-likeness metrics has reached the current state-of-the-art.
The following is an overview of the research, data and methods, technical validation, and conclusions:
1
Research Overview
In the early stages of drug discovery, accurately predicting and optimizing the ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) properties of molecules is crucial for improving the success rate of later clinical stages and successfully developing new therapeutic drugs. However, existing ADMET benchmark datasets generally have small data volumes and differ significantly from the types of compounds commonly used in drug development pipelines.Utility is limited in practical industrial scenarios.Although there is a large amount of publicly available ADMET experimental information, the prediction performance of models built directly from uncleaned data is poor due to the inconsistency in experimental conditions, which makes data cleaning highly challenging.
Based on this, the research team developed aAI Large Language Model-Driven Multi-Agent Data Mining System,Data extraction, standardization, data type filtering, and rigorous validation were performed on public datasets, and information from 14,401 different experimental sources was analyzed using a multi-agent system.A comprehensive and reliable ADMET property benchmark dataset named PharmaBench was ultimately constructed, covering 52,482 data entries across 11 key ADMET properties., which is currently the largest and most diversified ADMET dataset available in the field of drug development with corresponding properties. Compared to other data mining methods, MindRank's self-developed multi-agent data mining system has significant advantages such as high accuracy, less manpower required, and a wide range of data coverage, enabling it to quickly complete large-scale data mining tasks across various types.
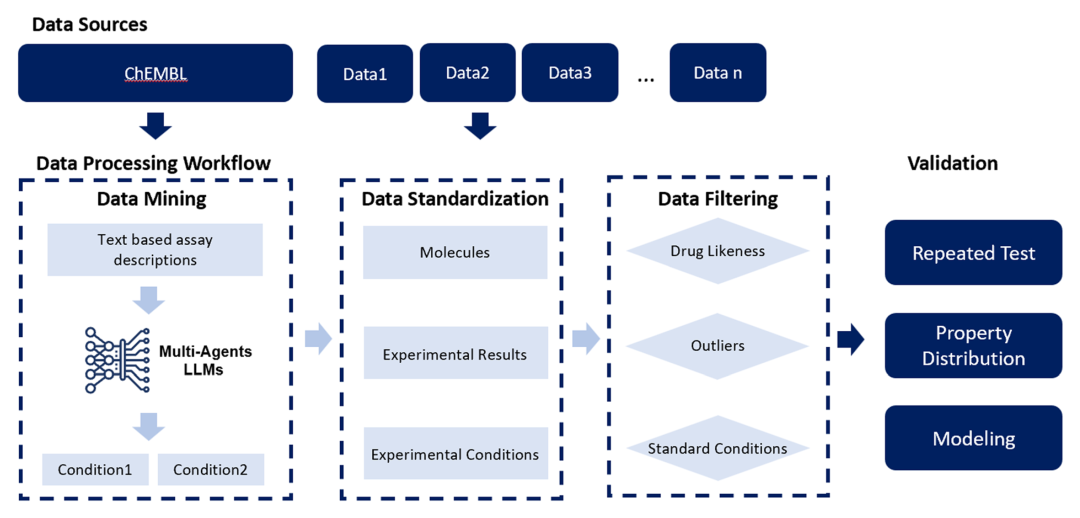
Figure 1: Data processing workflow for constructing PharmaBench
2
Data and Methods
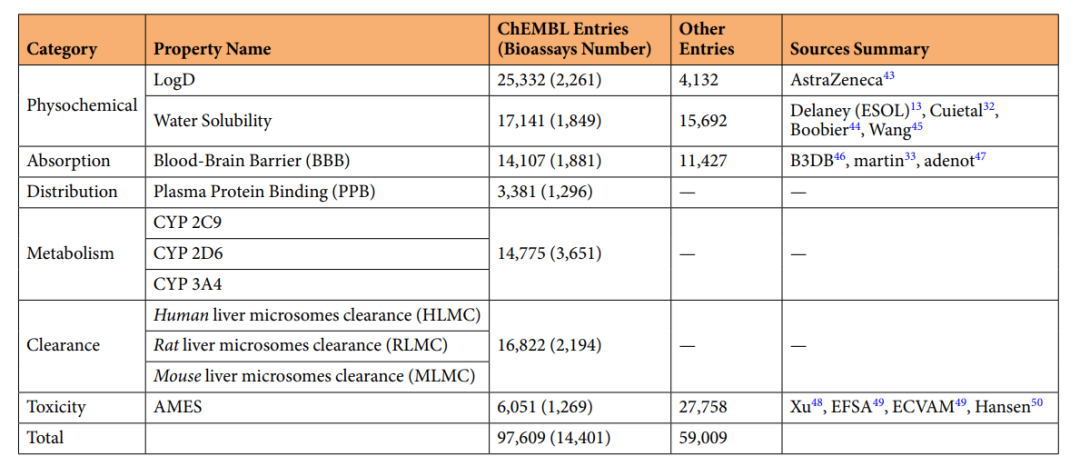
Table 1: Data Sources of PharmaBench
The research team used the ChEMBL database as the primary data source, extracting and integrating 97,609 raw data entries from 14,401 different experimental sources, and selected other relevant public datasets for expansion.A total of 156,618 data entries have been integrated.The team then established a multi-agent large language model data mining system, with the large language model as the core engine,Automatically identify key experimental conditions and generate examples from different types of experiments.Minimize the workload of manual extraction and structuring to the greatest extent.
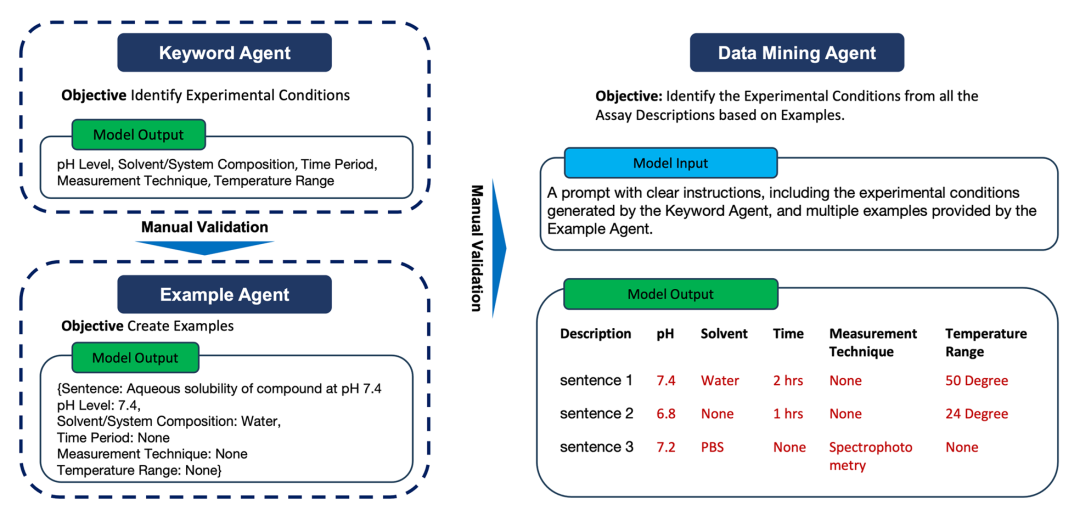
Figure 2: Multi-Agent Large Language Model Data Mining Workflow
Specifically, PharmaBench utilizes three self-developed large language model multi-agent systems to extract and standardize ADMET data:Keyword Extraction Agent (KEA), Example Formation Agent (EFA), and Data Mining Agent (DMA).KEA identifies and summarizes key experimental conditions from various ADMET experiments, EFA generates structured examples based on these conditions, and DMA completes all data mining tasks and standardizes the output according to the experimental conditions summarized by KEA and the examples generated by EFA.
PharmBench analyzed 14,401 different experimental records through this multi-agent system and identified key experimental information based on different ADMET experiment types. This allowed for further standardization and filtering processes, including the normalization of structural formats, experimental conditions, and experimental values, as well as the removal of abnormal molecules and irregular experimental entries.
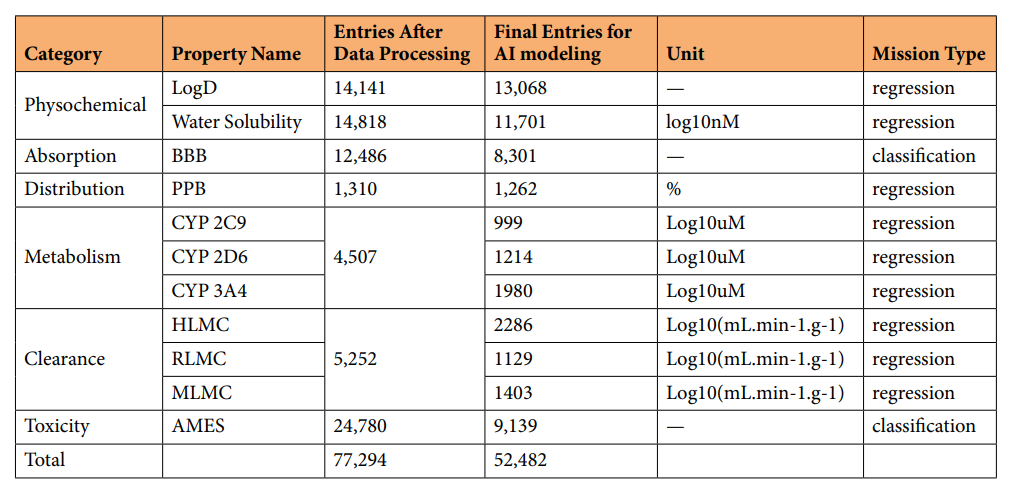
Table 2: Summary of the PharmaBench Dataset
Through the above data processing workflow and combined with artificial intelligence modeling, the research team ultimately integrated an ADMET benchmark dataset covering 52,482 entries, includingLogD, Solubility, BBB (Blood-Brain Barrier), PPB (Plasma Protein Binding), CYP (Cytochrome P450), LMC (Liver Microsomal Clearance), AMES, and other 11 key ADMET properties.
3
Technical Validation
After the dataset was constructed, the team validated and evaluated the data quality through repeated testing, attribute distribution, machine learning, and deep learning model training.The results show a significant improvement in data quality after the processing workflow, ensuring the consistency and reliability of the PharmaBench benchmark dataset.
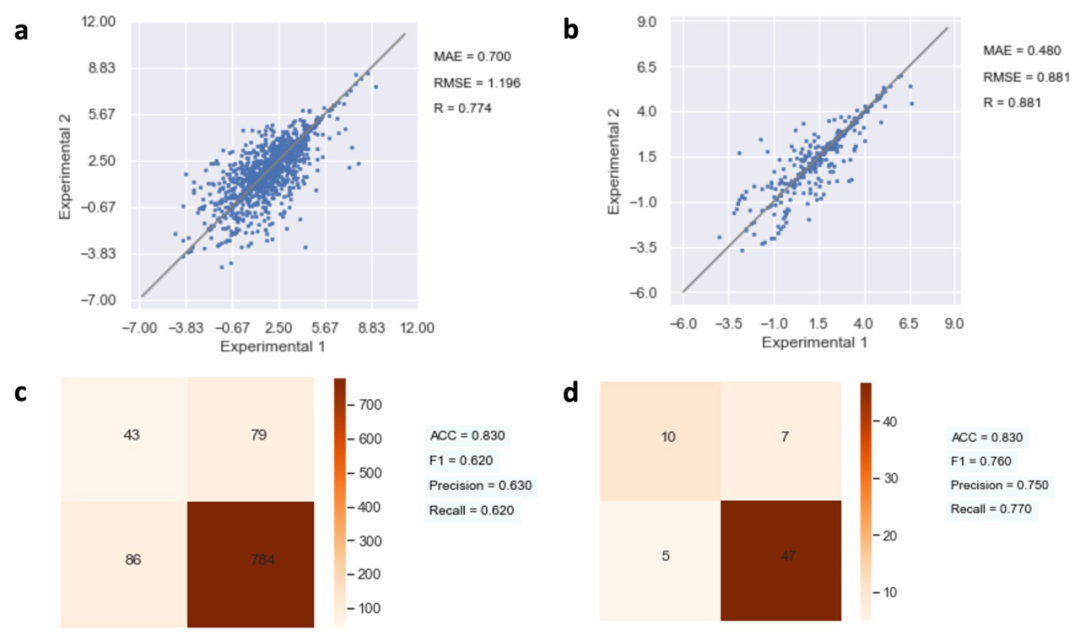
Figure 3: Data quality before and after processing compared through repeated testing and confusion matrix
(a) LogD Experiment Repeated Test Chart Before Data Processing
(b) LogD Experimental Repeatability Test Chart After Data Processing
(c) Repeated test diagram of the BBB experiment before data processing
(d) BBB experimental repeatability test diagram after data processing
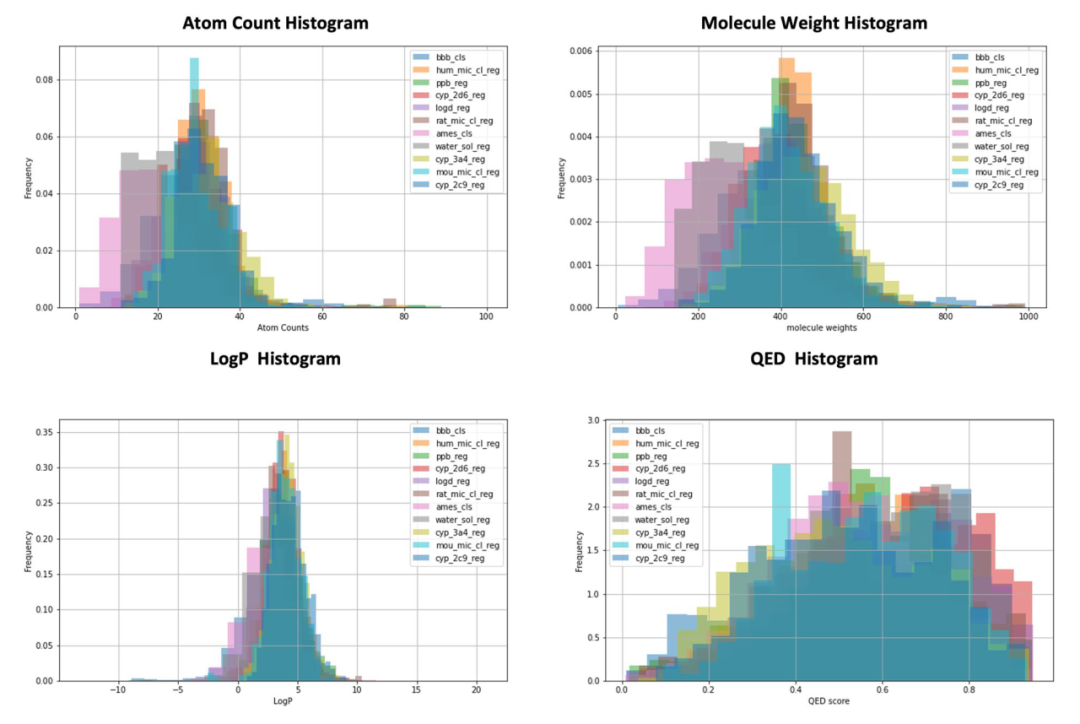
Figure 4: Frequency Histogram of the PharmaBench Dataset
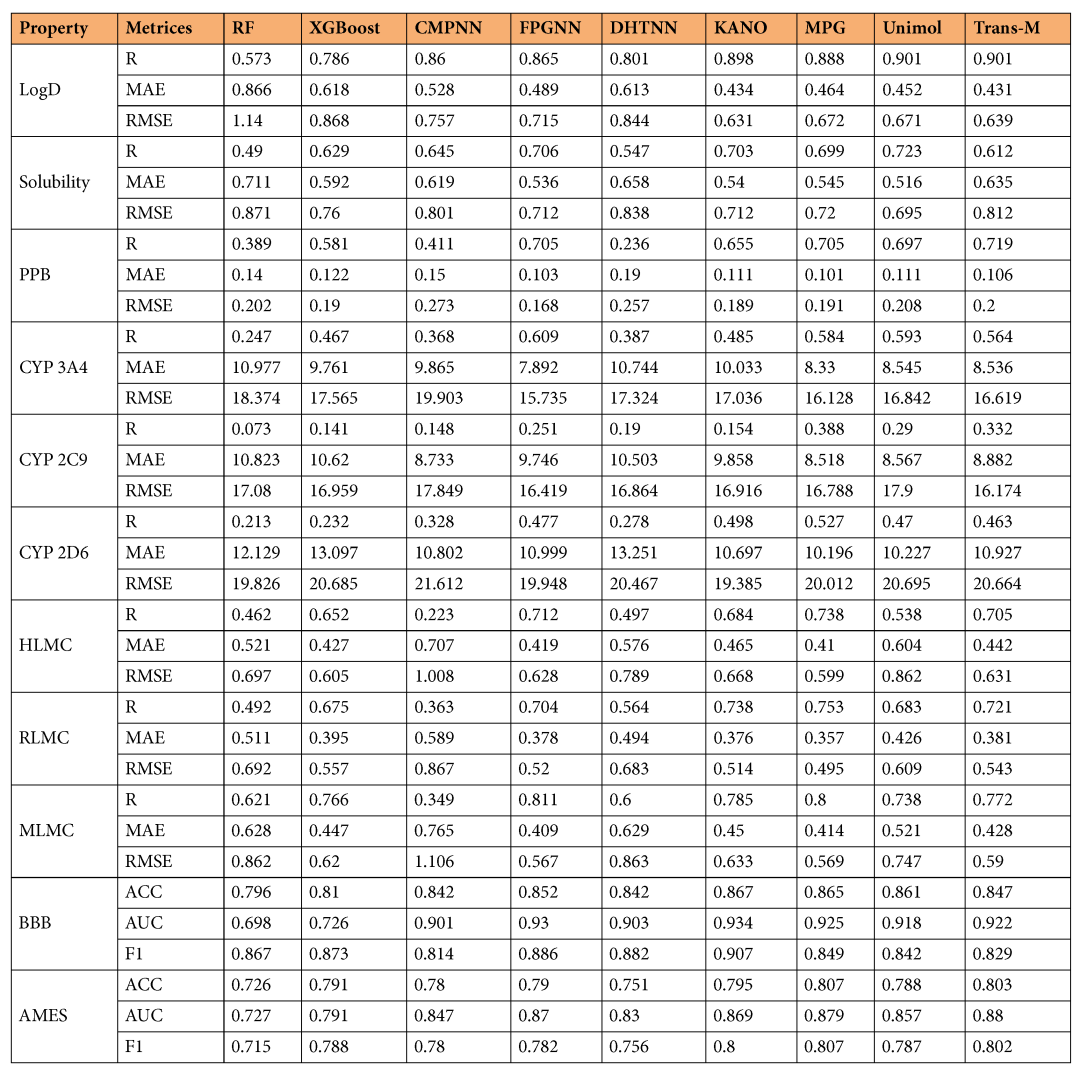
Table 3: Performance of Multiple Machine Learning and Deep Learning Models on PharmaBench (Based on Random Split)
4
Conclusion
This study leverages the data extraction and integration capabilities of large language model multi-agents.Built a more representative and application-valuable ADMET dataset benchmark PharmaBench。
Paper Link:
https://doi.org/10.1038/s41597-024-03793-0
Previous Studies:
ICML2023 | GNN Explanation Model MatchExplainer Based on Non-parametric Subgraph Matching
About MindRank
MindRank is a clinical-stage AI-driven innovative drug discovery company. The company's vision is to continuously deliver differentiated and high clinical value drug candidates by promoting the integration of various cutting-edge technologies in artificial intelligence and new drug research and development, thereby helping more lives regain health.
The AI pharmaceutical solution of MindRank Ltd. was recognized by the authoritative European and American institution Deep Pharma Intelligence as one of the "11 most significant AI drug R&D breakthrough achievements globally from 2018 to 2020." In 2023, it was included in Forbes' "Forbes Asia 100 to Watch" list, with only 11 startups from mainland China making the list.
For more information, please visit the website: www.mindrank.ai
Cooperation: bd@mindrank.ai
Other: info@mindrank.ai