Nature | Breakthrough by Leading Teams Solves Major Drug Discovery Challenge, Set to Rewrite the History of Drug Design

DeepMind
Artificial Intelligence Enterprises

Isomorphic Labs
AI Drug Developer
May 8, 2024, GoogleDeepMindJointly published with Isomorphic Labs in the journal *Nature* the latest artificial intelligence model AlphaFold 3 in the field of proteins! This model can accurately predict the structures of biomolecules such as proteins, DNA, RNA, and ligands, as well as their interaction patterns. This followsAnother Major Breakthrough After AlphaFold 2

In predicting drug interactions, AlphaFold 3 has achieved unprecedented accuracy, including the binding of proteins with ligands and antibodies with their target proteins. In the PoseBusters benchmark,AlphaFold 3 is 50% more accurate than the current best traditional methods, and it requires no structural information input, making it the first artificial intelligence system to surpass traditional physics-based prediction tools.This ability to predict antibody-protein binding is crucial for understanding various aspects of human immune responses and new antibodies.The design is crucially importantYes.
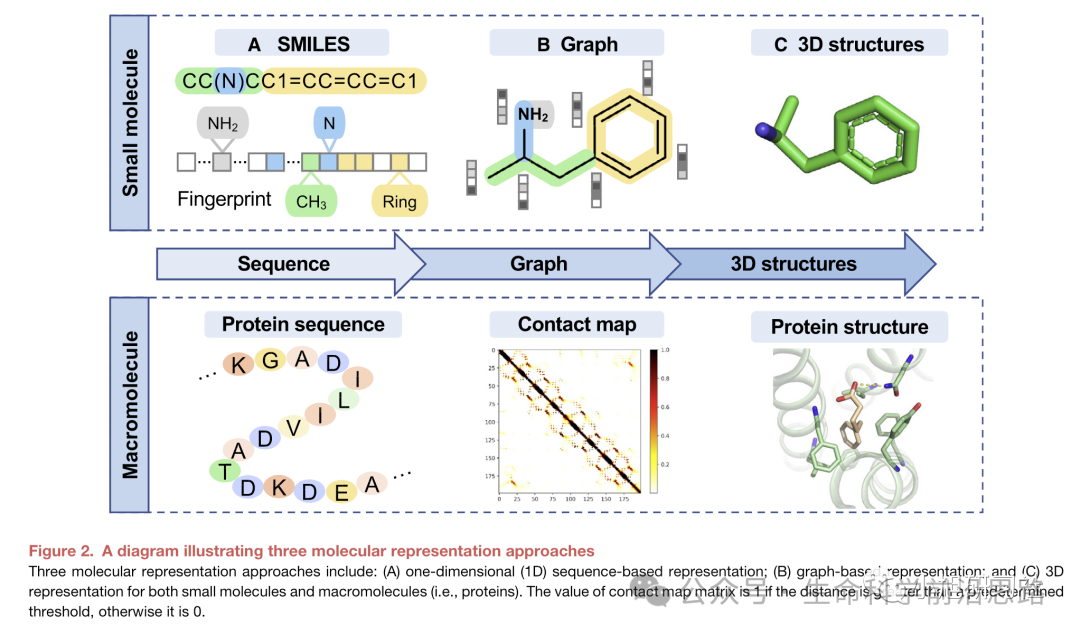
Proteins are the building blocks of life. From constructing our body tissues, regulating metabolism, to fighting diseases, proteins are everywhere. However, proteins in nature do not always meet our needs. Traditional protein engineering methods often rely on trial and error and experience, which are time-consuming, labor-intensive, and inefficient. The emergence of AI has opened a new door for us. Through machine learning and deep learning algorithms, AI can quickly analyze massive amounts of protein data, predict protein structures, and even design entirely new proteins from scratch. This not only greatly improves efficiency.
Universities in China that mainly engage in AI protein design
Peking University, International Machine Learning Research Center, Tsinghua University
Institute of Computing Technology, Chinese Academy of Sciences, Renmin University of China, Shanghai Jiao Tong University
Fudan University, ShanghaiTech University, Shanghai Institute of Materia Medica, Chinese Academy of Sciences
Center of Excellence for Molecular Cell Science, Chinese Academy of Sciences
Zhejiang University, Westlake University, Zhejiang University of Technology,
Shenzhen Institute of Advanced Technology, Tsinghua University Shenzhen International Graduate School
Southern University of Science and Technology, University of Science and Technology of China
Xiamen University, Shandong University, Tianjin Institute of Industrial Biotechnology, Chinese Academy of Sciences
As the most anticipated technology in 2024!
There are very few resources and learning pathways for AI protein design, making specialized training urgently needed! Zhengzhou Qingrui Information Technology Co., Ltd., in collaboration with Tsinghua University, Peking University, Westlake University, Zhejiang University, University of Science and Technology of China, Tianjin University, and the Institute of Materia Medica, Chinese Academy of Medical Sciences, has held over forty training sessions, with more than 5,000 participants! The training has received extremely high praise from attendees, some of whom have published in top international journals such as Nature, Cell, and Science!


Introduction of the Lecturer

The lecturer is engaged in artificial intelligence protein design research in a top-tier research group in China. Their current main research focus is on the development and application of machine learning algorithms for protein design, with extensive hands-on experience in protein engineering and bio-related algorithm development. They have published dozens of papers in internationally renowned journals such as Nature Communications and ACS Catalysis, as well as machine learning conferences like ICML.

Student Evaluation

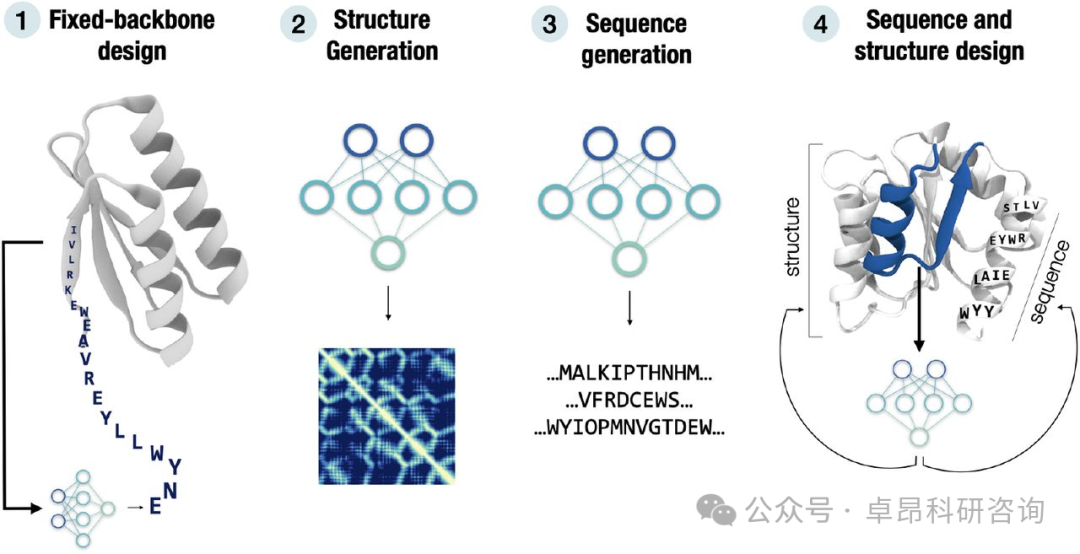
AI Protein Design Curriculum

*Operations involving the use of code/computational tools
1. Introduction to Deep Learning Related to Proteins
1. Basic Concepts
1.1. Introduction to Machine Learning: From Handwritten Digit Recognition to Large Language Models
1.2. Review of Protein Structure Prediction and Design
1.3. Introduction to Linux
1.4. Code Environment: VS Code and Jupyter Notebook*
1.5.Introduction to Key Python Concepts*
2. Commonly Used Methods for Analyzing/Visualizing Proteins and Related Molecules
2.1. Common Databases and Homologous Sequence Search and MSA Construction
2.2. Visualizing protein structures using PyMOL and Mol*
2.3. Using Biopython and Biotite to Analyze Biological Sequence and Structure Data*
2.4. Using fpocket and point-site to analyze protein structure pockets*
3. Differences Between Deep Learning Protein Design and Traditional Protein Design
3.1. The Essence of Deep Learning
3.2. Traditional Methods: All-Atom Energy Function Rosetta and Statistical Potentials
3.3. Deep Learning: Geometric Deep Learning
3.4. Complementarity of Deep Learning and Traditional Physical Methods
3.5. Superiority of Deep Learning in Protein Design
4. Protein Language Model
4.1. Language Models: From RNN to Transformers
4.2. Understanding the Protein Language
4.3. Generative Protein Language Models
4.4. Comparative Analysis of Structural Models and Language Models
5. Protein Function and Property Prediction Based on Deep Learning
5.1. Protein Function Classification Prediction*
5.2.Signal Peptide, Transmembrane Region, Subcellular Localization Prediction
5.3. Protein Homologous Structure Search
5.4. Enzyme Active Site Prediction
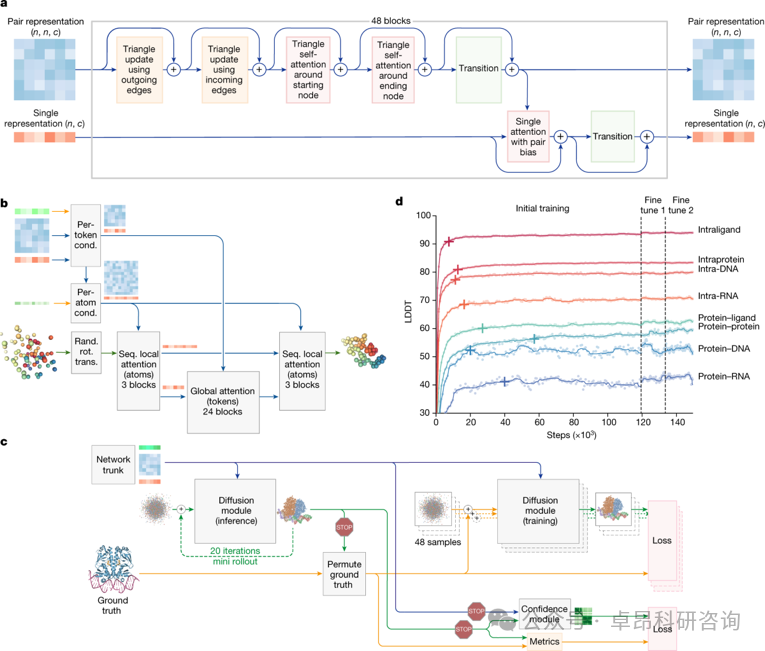
2. Deep Learning and Protein Structure Prediction
1.Traditional Protein (Complex) Structure Prediction
1.1. Homology modeling using Modeller and Swiss-Model
1.2. Ab initio modeling based on molecular dynamics
1.3. Molecular docking including non-protein parts, practical operation of AutoDock Vina*
2. Modern Deep Learning for Protein Structure Prediction
2.1.RaptorX: From Computer Vision to Protein Structure
2.2.AlphaFold2
2.3.AlphaFold3: Generative Structure Prediction
2.4.ESMFold: The Integration of Language Models and Structure Prediction
3. AlphaFold2 Principle Review
3.1. From Co-evolution to Structure
3.2. Attention Mechanism
3.3.EvoFormer
3.4.Structural Module
4.Introduction to AlphaFold3
4.1. Diffusion Model
4.2. Training Data
4.3. Achievements and Limitations of AlphaFold3
5. Practical Operation and Result Analysis of AlphaFold2/3
5.1. Practical Operation of AlphaFold2*
5.2.AlphaFold2 Analysis*
5.3.Using the AlphaFold Server*
5.4. Local Version of AlphaFold3*
5.5.AlphaFold3 Analysis*
6.ESMFold
6.1. From Language Models to Structure Prediction
6.2. When to use ESMFold and when to use AlphaFold
6.3.ESMFold Usage*
3. Fixed Backbone Protein Sequence Design
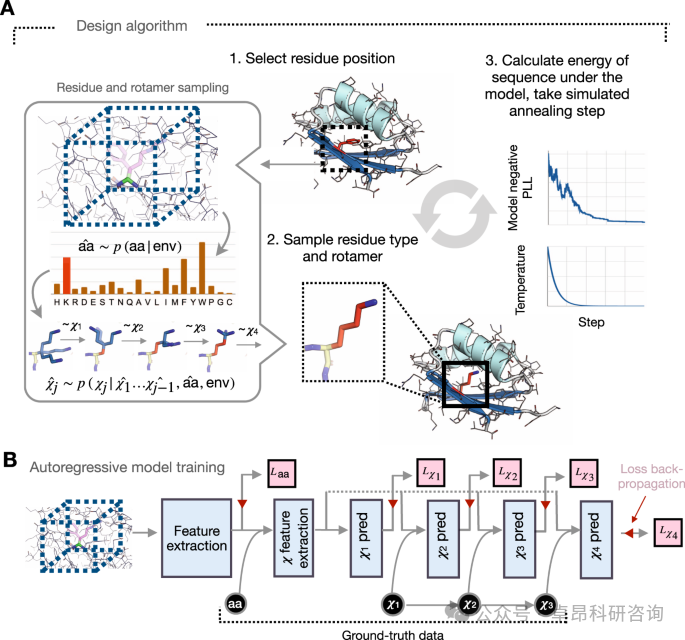
1. Traditional Protein Sequence Design
1.1. Based on All-Atom Force Field*
1.2. Based on Statistical Potential
2. Design of Protein Sequences with Structural Knowledge-Infused Language Models
2.1.ESM-IF Principle Introduction
2.2. Application of ESM-IF*
3. CNN-Based Sequence Design
3.1. Introduction to CNN Principles
3.2.DenseCPD Design Method
3.3. Design methods with side chain conformations
4. GNN-based sequence design
4.1. Analysis of ProteinMPNN's Success Experience
4.2. The Wide Application of ProteinMPNN
4.3.ProteinMPNN Practical Operation*
5. Other Sequence Design Models
5.1.Introduction and Practical Operation of ABACUS-R*
5.2.CarbonDesign From Structure Prediction to Sequence Design*
5.3.CARBonAra Environment-Aware Sequence Design*
6. Application of Fixed Backbone Sequence Design in Functional Protein Design
6.1. Optimization of New Scaffold Protein Expression (Reproduction of Science Article)*
6.2. Antibody Affinity Optimization (Science Article Reproduction)*
6.3. Comprehensive Optimization of Enzyme Properties Combined with Evolutionary Information (Reproduction of JACS Article)*
4. Deep Learning for Protein Structure Design
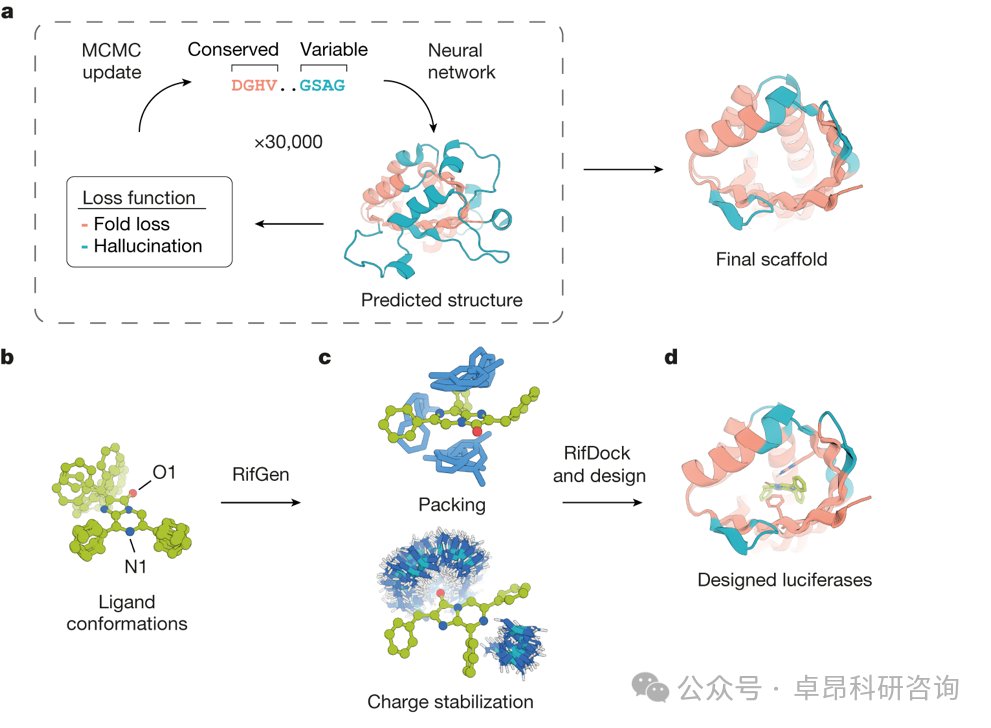
1. Review of Traditional Thinking
1.1. Domain Splicing
1.2.SCUBA: Side-Chain-Free Protein Force Field
2. Binder Design Based on Geometric Deep Learning of Protein Surfaces
2.1. Introduction to MASIF Principles
2.2.masif for identifying PPI hotspots on protein surfaces
2.3.Masif Design Binder
3. Protein Backbone Design Model Based on Diffusion Model
3.1.FrameDiff: IPA-Based Backbone Generation*
3.2.Chroma: Design of Equivariant Graph Neural Network Architecture
3.3.RFDiffusion: Based on RosettaFold
3.4.RFDiffusion-All-Atom: Based on RosettaFold-All-Atom
4. Sequence-Structure Co-design
4.1.trDesign
4.2.AlphaFold Hallucination
4.3.Rfjoint
4.4.Protein Generator
5. De novo design of binding proteins Nature Communication article process*
5.1. Selection of Functional Epitopes
5.2. Skeleton Generation with Restrictions
5.3. Iterative Optimization
6. De Novo Design of Luciferase Structure
6.1.Theozyme Theory Explanation
6.2. Skeleton Generation Strategy
6.3. Active Site Design and Activity Evolution
5. Function-Oriented Protein Sequence Design
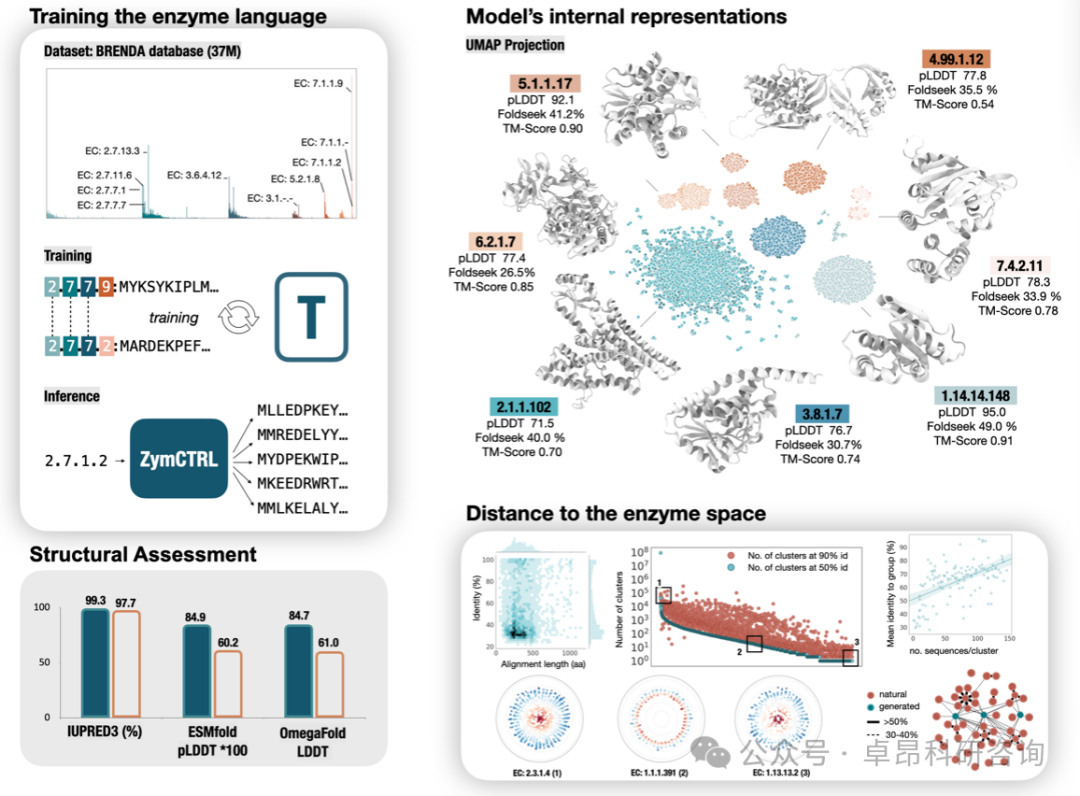
1. Deep Learning Modeling Methods for Language
1.1.Transformer
1.2.BERT: Bidirectional Encoder Representations from Transformers
1.3.GPT: Generative Pre-trained Transformers
2. Representative of Protein Language Models: ESM
2.1. Model Framework
2.2.ESM Series Work: ESM-1/2, MSA Transformer, ESM3
2.3.ESM Model Practical Operation*
3. Functional Protein Design Based on Protein Language Models
3.1. The Paradigm of Pre-training + Fine-tuning
3.2. Conditional Generative Models: Progen and ZymCTRL
3.3.Progen Case Analysis
3.4. Getting Started with Fine-Tuning ZymCTRL*
4. Non-Autoregressive Sequence Generation Model
4.1.ProteinGAN: Generating Sequences
4.2.DeepEvo: Generating Thermostable Enzymes
4.3.Prot-VAE
4.4.P450Diffusion: Designing Functional P450 Based on Diffusion Model*
5. Evaluation Metrics After Functional Protein Generation
5.1. Natural Sequence Similarity Assessment*
5.2. Diversity Assessment*
5.3. Structural Rationality Assessment*
6. Applications of Protein Mining and Engineering Based on Deep Learning
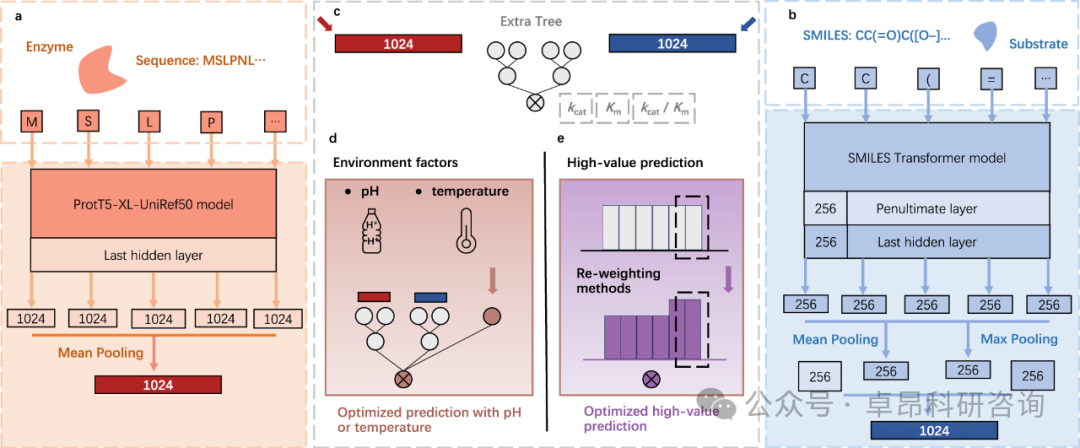
1. Enzyme Property Prediction
1.1 Introduction to DLKcat and GotEnzyme Databases
1.2.UniKP: Utilizing Pre-trained Models to Mine and Transform Kcat*
1.3.CLEAN: Contrastive Learning-Based EC Number Prediction for Mining Rare Dehalogenases*
2. Protein Thermal Stability Modification
2.1.Introduction to MutCompute
2.2. Using MutCompute to Engineer PETase (Nature)*
2.3.Introduction and Usage of ThermoMPNN*
2.4. Introduction and Usage of Pythia*
3. Machine Learning-Assisted Directed Evolution/Protein Engineering
3.1. Zero-shot mutation effect prediction principle
3.2. Zero-shot Remodeling Gene Editing Enzyme*
3.3.Low-N Strategy for Protein Engineering
3.4. Evo-tuning of Pre-trained Models*
3.5.Introduction to ECNet
3.6. Prediction of Mutation Effects in Protein Interactions
4. Train your own neural network based on your experimental data*
4.1. Neural Network Training Framework
4.2. Data Collection and Organization
4.3. Feature Extraction Methods
4.4. Selection of Pre-trained Models
4.5. Model Training and Testing
4.6. Prediction of New Mutations
5. Deep Learning-Assisted New Enzyme Mining*
5.1. Gene Editing Deaminase Mining (Cell Work Reproduction)
5.2. Mining of Thermostable Plastic Hydrolases (Nature Communications)
5.3.UseFoldSeekPerform structure-based mining
Through the course study, you will gain

General-purpose Protein Design Model Based on Deep LearningIn recent years, this course has developed rapidly, focusing on the fundamentals and cutting-edge work of protein design. It provides in-depth teaching ranging from protein structure prediction and optimization to de novo protein design. Starting from scratch, this course explains the basics in detail and will also discuss the application of related technologies in conjunction with the latest literature. Helping students,Through this training, participants will understand the underlying logic and basic rules of protein design, master the practical operation of common protein design algorithms, and gain foundational capabilities for developing protein design algorithms as well as a forward-looking perspective.
AIDD Artificial Intelligence Drug Discovery and Design
Course Objectives
Science Technology
AIDD Artificial Intelligence Drug Discovery and Design:It is artificial intelligence and machine learning technologies that have modernized the pharmaceutical field. Currently, machine learning and deep learning algorithms have been applied to various drug discovery processes, including peptide synthesis, virtual screening, toxicity prediction, drug monitoring and release, pharmacophore modeling, quantitative structure-activity relationship, drug repositioning, multi-pharmacology, and physiological activity. These can effectively combine traditional chemistry-oriented drug discovery with AI-driven drug design. Moreover, systems biology and chemistry scientists worldwide are collaborating with computational scientists to develop modern ML algorithms and principles, significantly promoting drug discovery and development.
AIDD Instructor, with over a decade of experience in computer algorithm research and programming. Research areas include bioinformatics, deep learning, drug target identification, and adverse drug reactions. Participated in two projects funded by the National Natural Science Foundation of China and led three provincial-level scientific research projects. As the first author, published several SCI papers in well-known journals such as BMC Bioinformatics, Journal of Biomedical Informatics, and International Journal of Molecular Sciences.
AIDD Artificial Intelligence Drug Discovery and Design Course Content

Day One
1.Overview of AIDD and Introduction to Comprehensive Drug Database
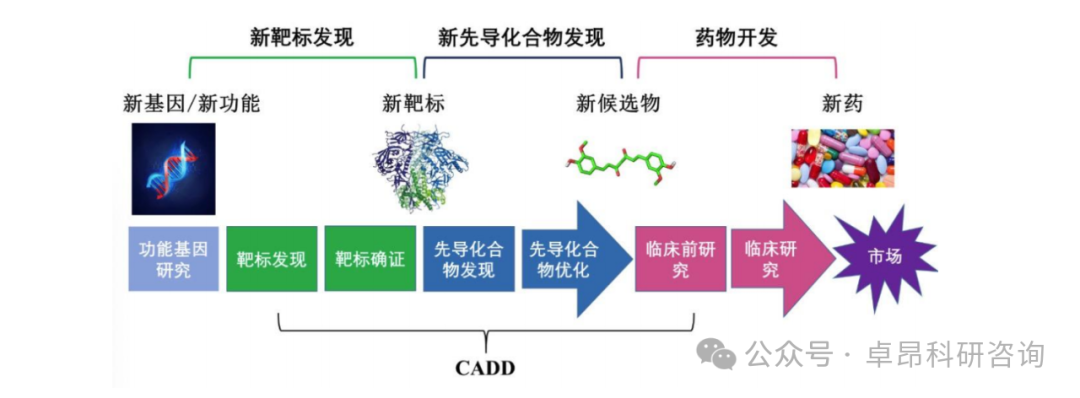
2. Overview of Artificial Intelligence-Aided Drug Design (AIDD)
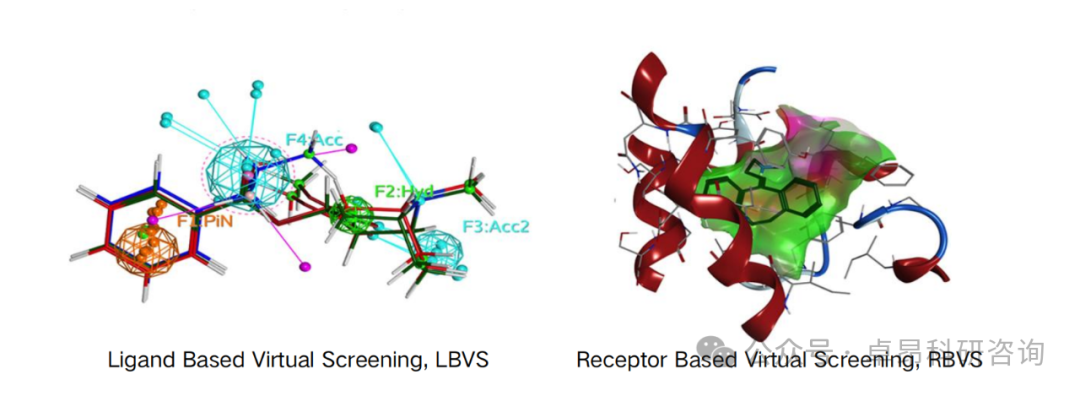
3. Installation Environment
(1)anaconda
(2)vscode
(3)pycharm
(4) Virtual Environment
4. Basic Usage of Third-Party Libraries
(1)numpy
(2)pandas
(3)matplotlib
(4)requests
5. Acquisition Methods of Comprehensive Databases for Multiple Drugs
(1) KEGG (requests crawler)
(2)Chebi(libChEBIpy)
(3)PubChem(pubchempy / requests)
(4)ChEMBL(chembl_webresource_client)
(5)BiGG(curl)
(6)PDB(pypdb)
The Next Day ML-based AIDD
1. Machine Learning
(1) Types of Machine Learning:
① Supervised Learning
②Unsupervised Learning
③ Reinforcement Learning
(2) Typical Machine Learning Methods
① Decision Tree
② Support Vector Machine
③Naive Bayes
④Neural Network
⑤ Convolutional Neural Network
(3) Evaluation and Validation of the Model
(4) Classification Evaluation: Accuracy, Precision, Recall, F1 Score, ROC Curve, AUC Calculation
(5) Regression Evaluation: Mean Absolute Error, Mean Squared Error, R2 Score, Explained Variance Score
(6) Cross-validation
2. Basic Usage of sklearn Toolkit
3. Basic Usage of RDKit Toolkit
4. Compound Encoding Methods and Compound Similarity Theoretical Knowledge
5. Project Practice 1: Molecular Screening Based on ADME and Ro5
6. Project Practice 2: Ligand Screening Based on Compound Similarity
7. Project Practice 3: Molecular Clustering Based on Compound Similarity
8. Project Practice 4: Biological Activity Prediction Based on Machine Learning
9. Project Practice 5: Machine Learning-Based Molecular Toxicity Prediction
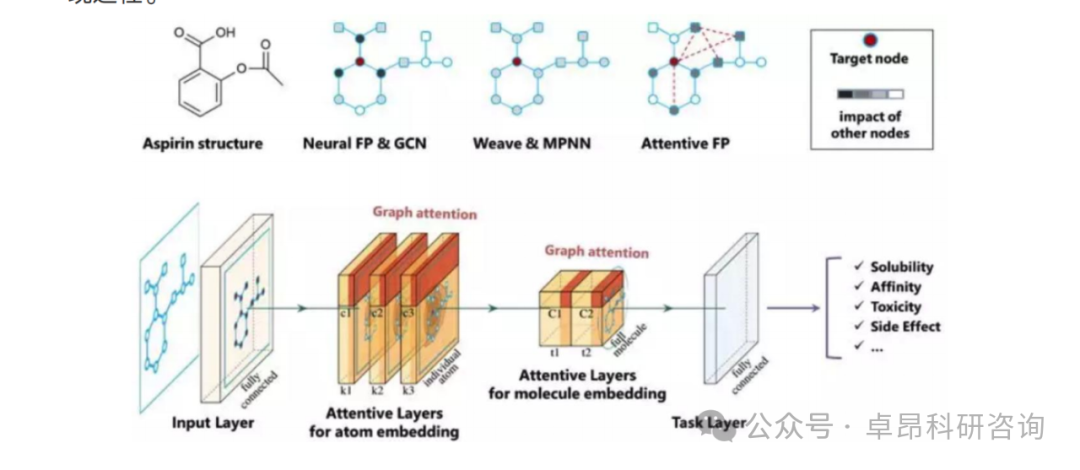
Day Three GNN-based AIDD
1. Graph Neural Network
(1) Framework Introduction: PyG, DGL, TorchDrug
(2) Graph Neural Network Message Passing Mechanism
(3) Design of Graph Neural Network Datasets
(4) Practical Tasks for Graph Neural Network Node Prediction, Graph Prediction, and Edge Prediction
2. In-depth Paper Analysis: DeepTox: Toxicity Prediction using Deep Learning
3. Project Practice 1: Molecular Toxicity Prediction Based on Graph Neural Networks
(1) Construction of PyG Graph Dataset from SMILES Molecular Data
(2) Molecular Toxicity Prediction Based on GNN
4. Project Practice 2: Prediction of Protein-Ligand Interactions Based on Graph Neural Networks
(1) Protein molecule visualization, constructing PyG graph dataset
(2) Network construction and interaction prediction based on GIN
Day Four NLP-based AIDD
1. Natural Language Processing
(1)Encoder-Decoder Model
(2) Recurrent Neural Network RNN
(3)Seq2seq
(4)Attention
(5)Transformer
2.Project Practice 1: Molecular Toxicity Prediction Based on Natural Language
(1)SMILES Molecular Dataset Word Vector Representation Method
(2) Molecular Toxicity Prediction Based on NLP Model
3.Project Practice 2: Prediction of Organic Chemical Reaction Yields Based on Transformer (Prediction of chemical reaction yields using deep learning)
4. In-depth Paper Reading and Code Explanation: "Mapping the space of chemical reactions using attention-based neural networks"
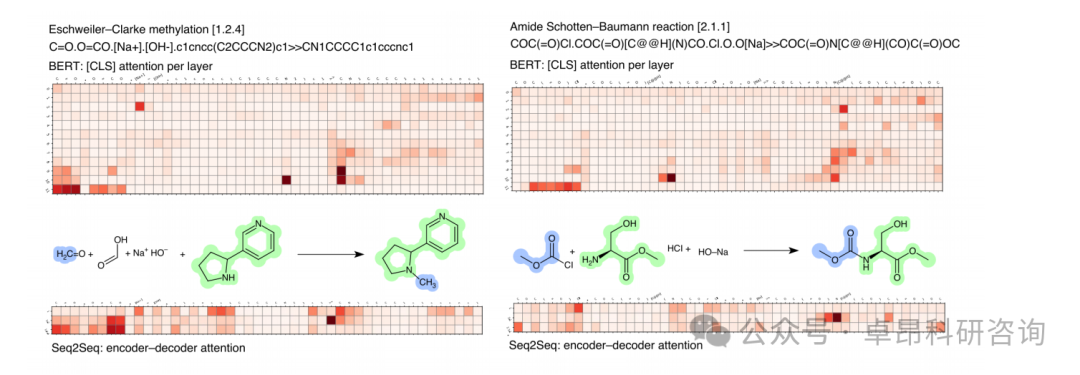
Day FiveMolecular Generation and Drug Design
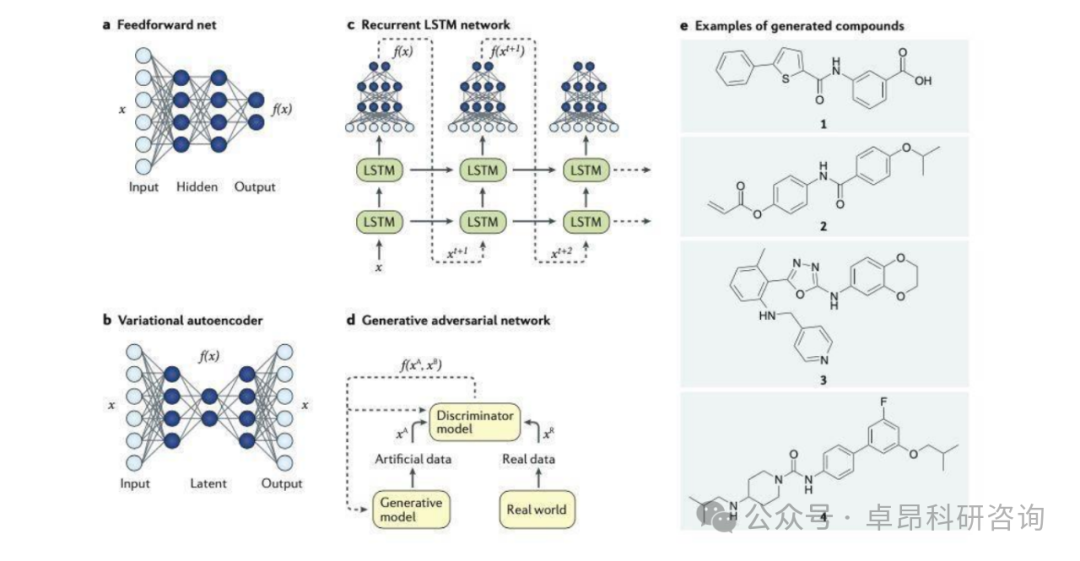
1. Molecular Generation Model
(1) Recurrent Neural Network RNN
(2) Variational Autoencoder VAE
(3) Generative Adversarial Network (GAN)
(4) Reinforcement Learning RL
2.Project Practice 1: A Graph to Graphs Framework for Retrosynthesis Prediction
3.Project Practice 2: Generative Language Modeling for Antibody Design Based on NLP
Course Objectives

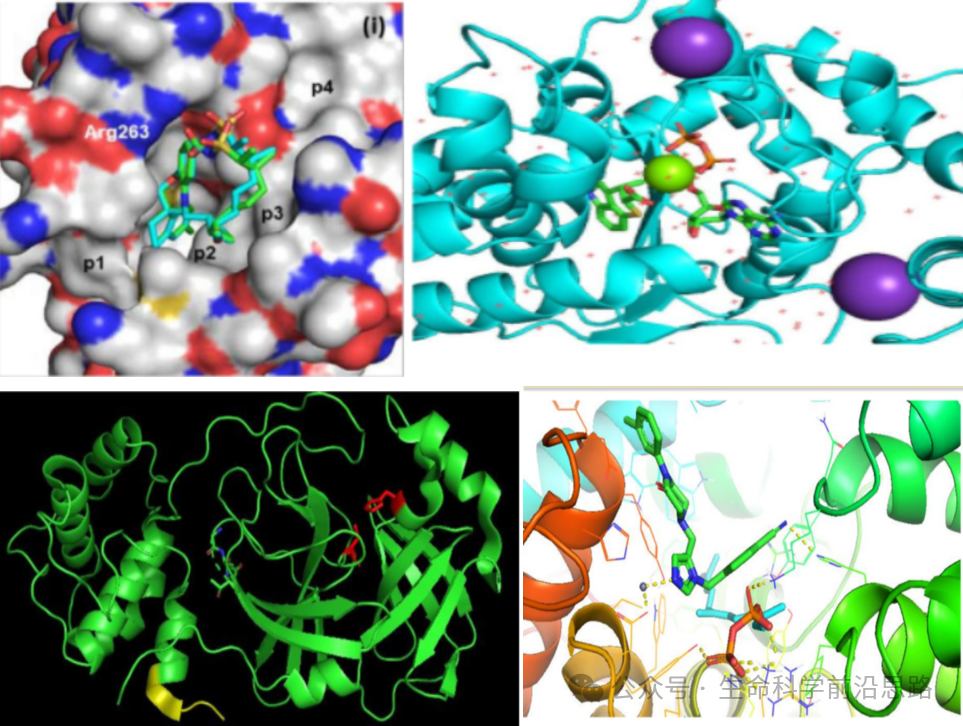
AIDD Artificial Intelligence Drug Discovery and Design Course: Allow students to understand the frontier background of drug discovery, learn various common algorithms in the field of artificial intelligence, become familiar with the installation and use of toolkits, master certain algorithm programming skills, and be able to apply computational methods to study drug-related problems. Through extensive case explanations and hands-on practice, students will develop the ability to construct AIDD models and perform data analysis.
Computer-Aided Drug Design Video Replay Course
Course Objectives
Science Technology
CADD Computer-Aided Drug Design:Based on the research achievements in life sciences such as biochemistry, enzymology, molecular biology, and genetics, and using computational chemistry as a foundation, this method involves simulating, calculating, and predicting the interactions between drugs and receptor biomacromolecules through computer modeling. By examining structural complementarity and property complementarity between drugs and targets, rational drug molecules are designed. It is a method for designing and optimizing lead compounds, widely applied in food, biology, chemistry, pharmaceuticals, plants, and diseases! The discovery and validation of targets represent the first step in modern new drug development and also one of the bottlenecks in the new drug creation process.
The lecturer for computer-aided drug design comes from the Institute of Materia Medica at Peking Union Medical College Hospital in China. The lecturer specializes in research areas such as deep learning, machine learning, virtual drug screening, computer-aided drug design, AI-driven drug discovery, molecular docking, and molecular dynamics, with over a decade of research experience.
CADD Computer-Aided Drug Design Course Schedule

Day OneMorning
Background and Theoretical Knowledge as Well as Tool Preparation
1. Introduction and Use of the PDB Database
1.1 Introduction to the Database
1.2 Query and Selection of Target Protein Structures
1.3 Download of Target Protein Structure Sequence
1.4 Download and Preprocessing of Target Proteins
1.5 Batch Download Protein Crystal Structures
2. Introduction and Use of Pymol
2.1 Introduction to Basic Software Operations and Fundamental Knowledge
2.2 Protein-Ligand Interaction Diagram
2.3 Protein-Ligand Small Molecule Surface Diagram, Electrostatic Potential Representation
2.4 Protein-Ligand Structure Superposition and Alignment
2.5 Plotting Interaction Forces
3.Introduction and Use of Notepad
3.1 Introduction to Advantages and Main Features
3.2 Interface and Basic Operations Introduction
3.3 Plugin Installation and Usage
Afternoon
General Protein
-Ligand Molecular Docking Explanation
1. Introduction to Relevant Theories of Docking
1.1 The Concept and Basic Principles of Molecular Docking
1.2 Basic Methods of Molecular Docking
1.3 Commonly Used Software for Molecular Docking
1.4 General Process of Molecular Docking
2. Conventional Protein-Ligand Docking
2.1 Collection of Receptors and Ligand Molecules
2.2 Processing of Complex Pre-conformations
2.3 Preparation of Receptor and Ligand Molecules
2.4 Protein-Ligand Docking
2.5 Analysis of Docking Results
Taking the main protease of the新冠病毒 protein and related inhibitors as an example
The Next Day
Virtual Screening
1. Introduction and Download of Small Molecule Database
2. Introduction to Related Programs
2.1 Introduction and Usage of OpenBabel
2.2 Introduction and Use of ChemDraw
3. Preprocessing for Virtual Screening
4. The Process and Practical Demonstration of Virtual Screening
Case: Screening for Main Protease Inhibitors of SARS-CoV-2
5. Result Analysis and Plotting
6. Drug ADME Prediction
6.1 Introduction to ADME Concepts
6.2 Introduction to Relevant Websites and Software for Prediction
6.3 Analysis of Prediction Results
Day Three
Methods for Expanding Docking Usage
1. Protein-Protein Docking
1.1 Application Scenarios of Protein-Protein Docking
1.2 Introduction to Related Programs
1.3 Collection and Preprocessing of Target Protein
1.4 Calculation Using Examples
1.5 Preset of Key Residues
1.6 Acquisition of Results and File Types
1.7 Analysis of the Results
Currently popular targets
PD-1/PD-L1, etc.
2. Docking involving metalloenzyme proteins
2.1 Background Introduction of Metalloenzyme Protein-Ligand
2.2 Collection and Preprocessing of Proteins and Ligand Molecules
2.3 Treatment of Metal Ions
2.4 Docking of Metal Cofactor Protein-Ligand
2.5 Result Analysis
Taking human farnesyltransferase and its inhibitors as examples
3. Protein-Polysaccharide Molecular Docking
4.1 Protein-Glycosaminoglycan Interactions
4.2 Key Points of Docking Processing
4.3 The Process of Protein-Polysaccharide Molecular Docking
4.4 Protein-Polysaccharide Molecular Docking
4.5 Analysis of Related Results
Taking α-glucosidase and polysaccharide molecular docking as examples
5. Nucleic Acid-Small Molecule Docking
5.1 Application Status of Nucleic Acid-Small Molecules
5.2 Introduction to Related Procedures
5.3 Types of Nucleic Acid-Small Molecule Binding
5.4 Nucleic Acid-Small Molecule Docking
5.5 Analysis of Related Results
Human Telomere
g - Quadruple chain and ligand molecular docking as an example.
Introduction to Operation Process and Practical Demonstration
Day Four
Methods for Expanding Docking Usage
1.Flexible Docking
1.1 Introduction to the Use Cases of Flexible Docking
1.2 Advantages of Flexible Docking
1.3 Protein-Ligand Flexible Docking
Focus: Method for setting flexible residues
1.4 Analysis of Related Results
Cyclin-dependent kinase
2 (CDK2) with ligand 1CK as an example
2. Covalent Docking
2.1 Introduction to Two Covalent Docking Methods
2.1.1 Flexible Side Chain Method
2.1.2 Two-Point Attractor Method
2.2 Collection and Preprocessing of Proteins and Ligands
2.3 Covalent Docking of Covalent Drug Molecules with Target Proteins
2.4 Comparison of Results
Taking the currently popular covalent drugs for COVID-19 as an example.
3. Protein-Hydration Docking
3.1 The Significance and Methods of Hydration in Protein-Ligand Interactions
3.2 Collection and Preprocessing of Proteins and Ligands
3.3 Preparation of Relevant Parameters for Docking
Focus: The Addition and Treatment of Water Molecules
3.4 Protein-Water-Ligand Docking
3.5 Result Analysis
Acetylcholine-binding protein
(AChBP) with nicotine complex as an example
Day Five
Molecular Dynamics Simulation (Linux and GROMACS Installation and Usage)
1. Introduction and Simple Usage of the Linux System
1.1 Common Linux Command Lines
1.2 Common Program Installation on Linux
1.3 Experience: How to Perform Virtual Screening on Linux
2. Introduction to Molecular Dynamics Theory
2.1 Principles of Molecular Dynamics Simulation
2.2 Methods and Related Programs of Molecular Dynamics Simulation
2.3 Introduction to Related Force Fields
3. Introduction and Usage of Gromacs
Focus: Introduction to Main Commands and Parameters
4. Introduction and Use of Origin
Day Six
Execution of Solvated Molecular Dynamics Simulations
1. General Process for Handling Solvated Proteins
2. Preparation of Protein Crystals
3. Structural Energy Minimization
4. Pre-equilibration of the system
5. Unrestricted Molecular Dynamics Simulations
6. Presentation and Interpretation of Molecular Dynamics Results
Taking lysozyme in water as an example
Day Seven
Execution of Protein-Ligand Molecular Dynamics Simulations
1. Protein-Ligand Processing Workflow in Molecular Dynamics Simulations
2. Preparation of Protein Crystals
3. Preparation of Initial Conformations for Protein-Ligand Docking
4. Preparation of Ligand Molecular Force Field Topology Files
4.1 Brief Introduction to Gauss
4.2 Brief Introduction to Ambertool
4.3 Generating Force Field Parameter Files for Small Molecules
5. Pre-equilibration with separate restraints on temperature and pressure in the complex system
6. Unrestricted Molecular Dynamics Simulation
7. Presentation and Interpretation of Molecular Dynamics Results
8. Trajectory Post-processing and Analysis
Taking the main protease of the新冠病毒 protein and related inhibitors as examples
Course Objectives

Computer-aided drug design mainly includes:PDB database, target protein, protein-ligand, protein-ligand small molecule, protein-ligand structure, molecular docking, protein-ligand docking, virtual screening, protein-protein docking, protein-polysaccharide molecular docking, protein-hydration docking, molecular dynamics, etc.
SPORTS


Course Schedule

AI Protein Design Class Time

2024.11.01-----2024.11.03 (19:00-22:00 PM)
2024.11.08-----2024.11.10 (19:00-22:00 PM)
2024.11.15-----2024.11.1 (19:00-22:00 PM)
2024.11.22-----2024.11.24 (19:00-22:00 PM)
A total of 12 nights of classes via Tencent Meeting live stream, online practical operations, and all recordings provided.

AIDD Artificial Intelligence Drug Discovery and DesignLecture Time
2024.11.02-----2024.11.03(09:00-11:30--13:30-17:00)
2024.11.09-----2024.11.10(09:00-11:30--13:30-17:00)
2024.11.16(09:00-11:30--13:30-17:00)
A total of 5 days of classes via Tencent Meeting live stream, online hands-on practice, with all sessions recorded.
Computer-Aided Drug Design Video Replay Course Schedule

A total of 7 days of video lessonsProvide all recorded broadcasts + code materials + PPT software + group Q&A
Training Costs and Benefits
Course Registration Fee:
AI Protein Design Live Course:
Public Price: ¥6880 per person per class (including registration fee, training fee, materials fee, and provision of full post-class playback materials)
Self-funded price: ¥6,480 per person per class (including registration fee, training fee, materials fee, and provision of full post-class playback materials)
AIDD Drug Discovery and Design Live Course
Public Price: ¥5880 per person per class (including registration fee, training fee, and material fee)
Self-funded price: ¥5580 per person per class (Including registration fee, training fee, material fee,)
Computer-Aided Drug Design Replay Course:
Public Fee: ¥4980 per person per class (including registration fee, training fee, materials fee, full-process playback materials, code, PPT, and group Q&A support)
Self-funded price: ¥4580 per person per class (Including registration fee, training fee, materials fee, providing full playback materials, code, PPT, and group Q&A.)
Heavyweight Discounts:
Buy Two, Get One Free (Sign up for two classes and get one learning spot free; the gifted class can be chosen freely)
Discount 1:
Two classes together: 10,880 RMB (Original price: 18,640 RMB)
Three Classes Together: 14,880 RMB (Original Price: 23,620 RMB)
Special Offer 1: 24,880 RMB (Free access to any courses hosted by our organization for a whole year)
Special Offer Two: 28,880 RMB (Free access to any courses offered by our institution for two full years)
Discount 2: Early registration and payment can enjoy a 300 yuan discount (limited to fifteen participants).
Sign up for courses and get previous course replays for free (the number of courses you sign up for equals the number of replays you receive).
(Clickable link for details):
Replay One:This course is a video course! Machine Learning Biomedical Training!
Replay Two:This course is a video course! Single-cell spatial transcriptomics training!
Replay Three:This course is a video course! Comparative Genomics Training!
Replay Four:This course is a video course! Machine Learning Proteomics Training
Playback Five:This course is a video course! Machine Learning Microbiomics Training
Replay Six:This course is a video course! Protein Crystal Structure Analysis Training
Replay Seven:This course is a video course! CRISPR-Cas9 Gene Editing Training
Replay Eight:This course is a video course! Machine Learning Metabolomics Training!
Playback Nine:This course is a video course! In-depth learning genomics training!


1. Course Features -- Comprehensive coverage of course technology applications, principles and processes, and practical examples throughout.
2. Learning Mode -- Combining theoretical knowledge with hands-on operation to help beginners quickly master the skills.
3. Course Service Q&A -- The main instructor will provide professional answers to questions you encounter in your actual work.
Teaching Method: Online live streaming via Tencent Meeting, theory+Hands-on teaching mode, with the teacher guiding step by step.Starting from scratch, electronicPPTAnd TutorialsOne week before the course starts, all training software will be sent to the students in advance. If there are any questions, they can be resolved through voice communication, screen sharing, and WeChat group discussions. Students and teachers can interact, and students can also communicate with each other. After the training is completed, the teacher will continue to answer questions for a long time, and the training group will not be disbanded. Past trainees have consistently given very high evaluations of the training quality and teaching methods!

Tencent Meeting Live Streaming Q&A | Step-by-Step Guidance


Quoting a sentence from one of the participants at this conference:
Statement:This content is provided, authorized, or reproduced by a third party; all copyrights and liabilities related to this content are the responsibility of the third party and have nothing to do with this public account. Any judgment made based on this content will be at your own risk.