Exclusive Interview with Biocompass: AI Virtual Cells Enter the 'World Model' Era!

Biocompass
Provider of Customized AI Solutions for Drug Development
Over the past three years, the AI Virtual Cell (AIVC) sector has become crowded with players, featuring massive sequencing datasets and models with billions of parameters, yet it remains stuck in the same dead end.
A Chinese team named Biocompass has hit upon the industry's most fundamental contradiction: the mismatch between large language model architectures and real-world cellular data.
Just recently, the team unveiled a novel solution—the official release of CellOS, the world's first LLM-JEPA single-cell world model.
Built on a 12-billion-parameter model trained on 390.5 million single-cell transcriptomic data points, this system breaks away from traditional masked language modeling for the first time. By leveraging a dual-perspective JEPA architecture to decipher dynamic cellular states, it has set new state-of-the-art (SOTA) benchmarks across multiple core evaluations, potentially revolutionizing the foundational R&D paradigm in the pharmaceutical and life sciences sectors.
A decade after the single-cell sequencing boom, with sequencing devices continuously generating cellular data, the Transformer architecture paved the way for the emergence of the first generation of AI-driven virtual cells (AIVC).
However, the Scaling Law, which is prevalent in the field of large models, seems to fail in the AI virtual cell sector.
Model capabilities have failed to keep pace. The vast majority of cell-based AI solutions on the market simply replicate the Transformer's cloze-test training logic: masking a segment of genetic sequence and requiring the model to predict the missing content.
This mechanism learns superficial patterns in data, essentially "memorizing sequencing tables" rather than understanding cells.
What truly determines disease progression, drug response, and cell differentiation are often the subtle signals resulting from the cumulative effects of dozens of genes. Their expression levels are not prominent, and models based solely on superficial fitting will never capture these critical changes.
A quantitative study published in Nature Methods in June 2026 delivered a decisive blow to a key industry pain point: models trained on 22.2 million cells exhibited complete performance stagnation when using only 1%–10% of the training data, with no further improvements achievable by increasing the dataset size.
The entire industry has hit a bottleneck: merely accumulating data and parameters cannot compensate for the models' lack of understanding of the underlying biological logic.
Yang Fan, COO of Biocompass, concluded that the traditional approach has reached its limit; AI in life sciences must adopt a new underlying architecture, and the industry needs to forge a different path.
Biocompass had previously aligned with the industry's mainstream technical approach, conducting explorations based on the Transformer architecture. However, the team has consistently sought a solution capable of fundamentally reducing the model's sensitivity to bias and noise in cellular data.
In 2025, the company made its first attempt to integrate Graph Neural Networks (GNNs) into the Transformer architecture, aiming to enhance the model's ability to capture cellular relationships. However, this approach remained a localized optimization and did not address the core issue.
Until early this year, Biocompass decided to shift to a more challenging R&D technical route—JEPA (Joint Embedding Predictive Architecture).
This R&D path is fraught with compounding obstacles, making it an industry-recognized "perilous journey."
On one hand, JEPA needs to align two completely different cellular observation dimensions in the latent space; on the other hand, causal loss must incorporate temporal constraints. This dual restriction is highly prone to causing training instability. More challenging still, cellular genes lack fixed textual sequences, rendering mature training constraint rules from language models entirely inapplicable. Consequently, the entire training framework must be designed from scratch.
"Traditional models are designed to replicate the input; our goal is to enable the model to learn to predict the hidden states in another dimension of the cells," the team explained.
In the Transformer era, it is common practice to train models using a cloze task approach, enabling them to predict masked genes.
Such an approach merely memorizes data, whereas changes in cellular states result from the combined effects of countless subtle genetic signals; simple memorization fails to capture dynamic patterns. The core value of JEPA lies in predicting cellular representations across perspectives within the latent space, thereby stripping away noise from sequencing data and locking onto stable, authentic biological features.
To implement this architecture, the team designed a unique dual-perspective observation system, which is also the core innovation that distinguishes CellOS from all competitors:
1. Expression View: Quantify the abundance of all gene expressions to reconstruct the static genetic composition of cells;
2. Perception View: Calculate the Surprisal Score to filter key signals with high biological value relative to the cell population.
Dual-perspective synergy: The model first ranks all information by gene expression levels, then filters out irrelevant noise through the perception view to precisely capture key transition nodes in cell differentiation, migration, and pathogenesis.
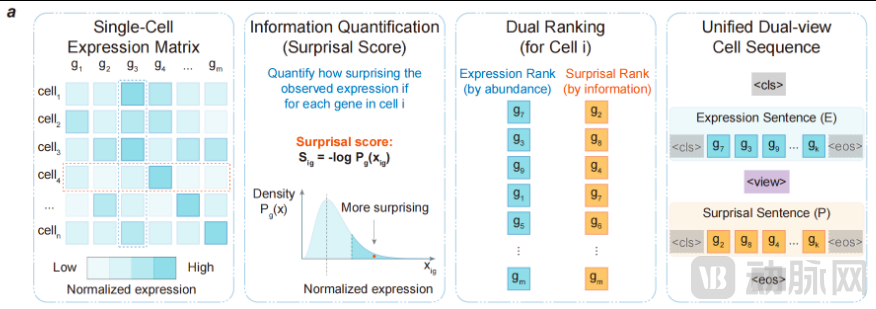
Synergistic Mechanism between Expression View and Perception View
To meet the immense computational demands of dual-view joint modeling, CellOS adopts a three-stage Dense-to-MoE training strategy, progressively scaling from a lightweight dense model to a 12-billion-parameter Mixture-of-Experts (MoE) large model. This approach preserves the biological knowledge acquired during earlier stages, thereby preventing performance degradation after expansion.
The scale of the entire training dataset has set a new global record for publicly available models, covering 47,845 sets of sequencing samples and 390 million single-cell transcriptomes, with 346 million cells accompanied by comprehensive and detailed annotations.
Yang Fan stated that this is currently the largest-scale single-cell foundation model among publicly available models globally.
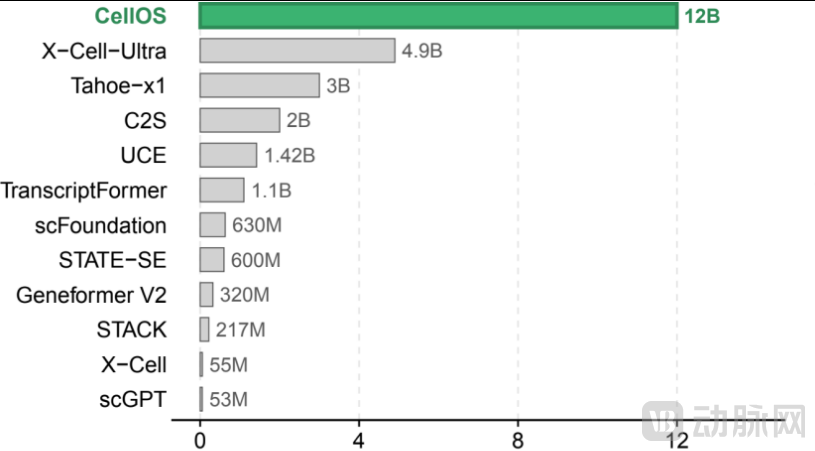 Comparison of Parameter Counts in Mainstream Global Single-Cell Models
Comparison of Parameter Counts in Mainstream Global Single-Cell Models
Whether the approach is viable must ultimately be determined by controlled experiments.
Biocompass demonstrated the absolute superiority of the dual-view JEPA architecture through multiple sets of horizontal benchmarking.
I. Cell Annotation and Batch Integration: Balancing Noise Reduction with Preservation of Biological Information
In the unified cell annotation benchmark, CellOS achieved a biological conservation score of 0.792, significantly outperforming mainstream models such as UCE, scGPT, and TranscriptFormer.
Even when faced with samples exhibiting subtle distinctions, such as T-cell subpopulations, immunosenescence, and induced pluripotent stem cell (iPSC) differentiation, the model can still accurately identify hierarchical cell states.
In batch integration scenarios, it balances sequencing technical biases with intrinsic biological signals: although its batch mixing metrics are slightly lower than those of STACK, it better preserves cell state-related biological information while reducing batch effects, thereby more closely aligning with the real-world analytical needs of academic research and pharmaceutical companies.
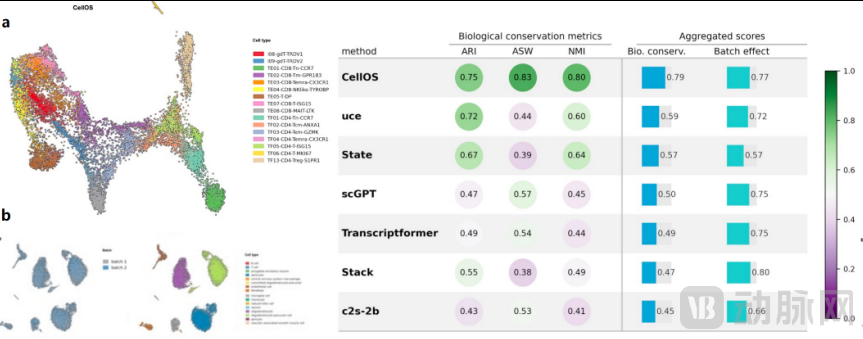 Evaluation of CellOS in Cell Annotation and Integration Tasks
Evaluation of CellOS in Cell Annotation and Integration Tasks
2. Drug/Gene Perturbation Prediction: Achieving a 66% Performance Gap, Leading the Industry by a Wide Margin
Perturbation response prediction is the most critical practical metric in AI-driven drug discovery, directly determining whether a model can proactively predict the effects of drugs on human cells.
On the core metric Pearson_edist, CellOS scored 0.619, making it the only solution among all evaluated models to surpass the 0.6 threshold; compared to the previous best open-source model, TranscriptFormer (0.373), this represents a performance improvement of up to 66%.
Scatter plot comparison: CellOS exhibits both high biological consistency and perturbation fidelity, falling within the industry's optimal range.
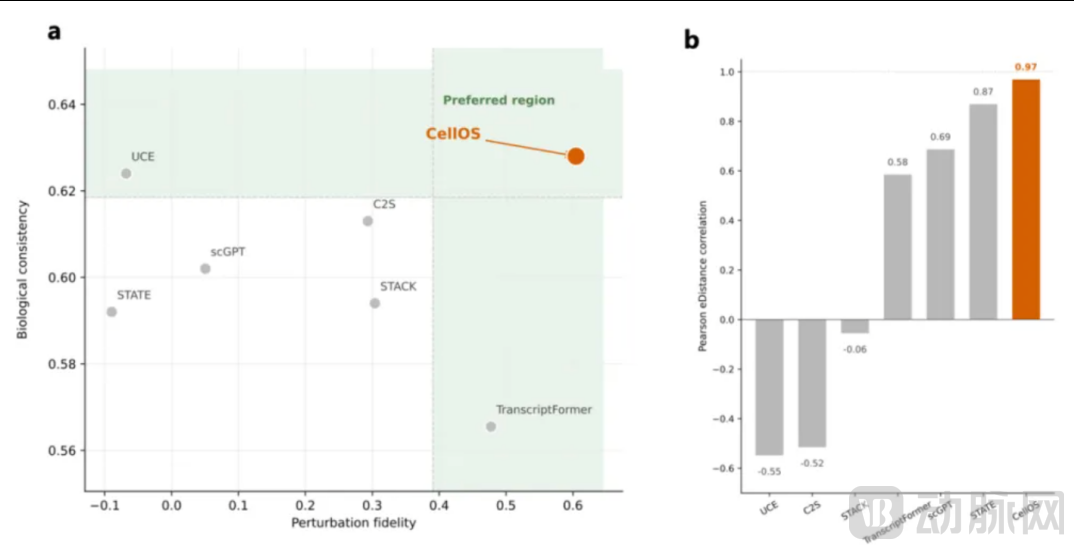
CellOS: Cross-Comparison with Mainstream Models in Predicting Drug/Gene Perturbation Responses
3. Ablation Study to Validate Architectural Correctness: Performance Exhibits Stable and Positive Growth with Increasing Parameter Size
The team conducted ablation studies across three model scales with 0.2B, 2B, and 12B parameters. All three clustering metrics—ARI, NMI, and ASW—showed consistent improvement with model scaling, without encountering any performance bottlenecks.
The steadily rising growth curve directly validates that the dual-perspective approach of JEPA + MoE possesses sustainable scaling capabilities, avoiding the traditional model's shortcoming where "more data leads to diminished performance."
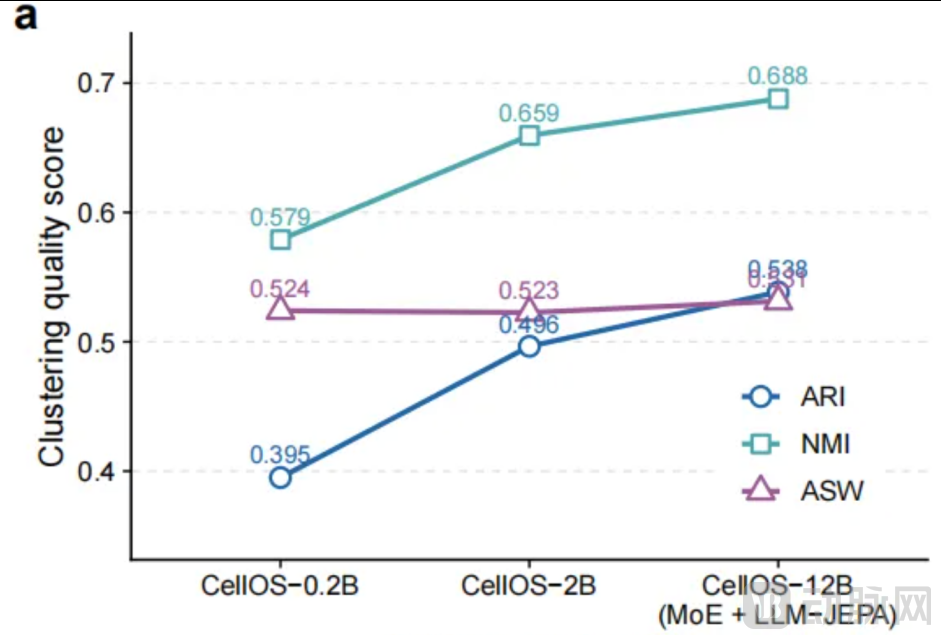 CellOS Parameter Ablation Experiment Curves
CellOS Parameter Ablation Experiment Curves
"This clear upward performance curve is the most tangible positive feedback we have received on our R&D journey." Yang Fan spoke with calm certainty about the years-long technical breakthroughs.
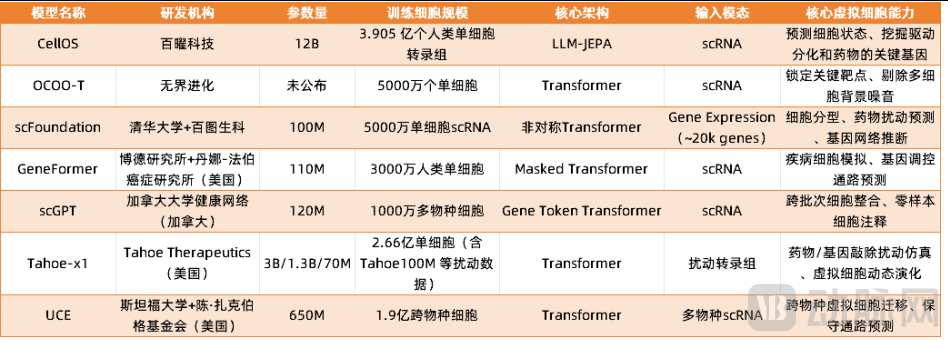 Comparison of Global AI Virtual Cell Foundation Models (Partial)
Comparison of Global AI Virtual Cell Foundation Models (Partial)
For several years, AI's transformation of life sciences has remained confined to the molecular level: AlphaFold predicts protein structures, generative AI designs novel drug molecules, and automated tools perform initial drug screening.
These tools have significantly shortened the R&D cycle for new drugs.
Disease progression, drug efficacy release, and human immune activation—all physiological changes are, in essence, the result of the continuous evolution of cellular states.
Researchers have gradually reached a consensus: what drives the leapfrog advancement of the AI-driven drug discovery industry is never the prediction of individual molecules, but rather the comprehensive simulation of cellular dynamics and the deduction of entire life systems.
AI virtual cells have thus become a core sector jointly bet on by the global life sciences, biopharmaceutical, and investment communities.
Global research institutes, innovative pharmaceutical companies, and AI technology firms are continuously strategizing around "virtual cells that are simulatable, predictable, and amenable to targeted design."
Prior to this, the industry remained constrained by the inherent limitations of language models, unable to truly interpret cellular data; with the emergence of CellOS, this novel LLM-JEPA technical approach appears to offer a viable solution validated by massive datasets.
The goal of fully predicting life systems in humans may no longer be a distant academic hypothesis, but rather an increasingly clear path to practical implementation.