Genomic Data Bottleneck: 42 Gene Testing Companies Step Up with Solutions
In VCBeat’s 2016 “Top 100 Future Healthcare Companies in China” list, the genetic testing sector emerged as a standout, with 18 companies making the cut—the highest number among all sectors covered. BGI Genomics topped the list with a market valuation of RMB 20 billion. As costs continue to decline and public awareness of genetics grows, genetic testing companies are driving innovation through advanced genomic technologies within the healthcare industry. Meanwhile, precision medicine has been incorporated into China’s 13th Five-Year Plan, and pilot restrictions on non-invasive prenatal testing (NIPT) have been lifted. These favorable policy developments have created a fertile environment for the growth of genetic testing enterprises.
On one hand, genetic testing is becoming increasingly widespread; on the other, data output is growing at an ever-larger scale. How to store, analyze, and interpret such massive volumes of data has become a critical bottleneck and barrier that the industry must overcome. The human whole-genome sequence comprises approximately 3 billion base pairs. To ensure accurate interpretation, it is standard practice to read each base pair more than 30 times, resulting in roughly 100 billion characters of data. By this calculation, even before considering analysis and interpretation, the sheer task of reading the data represents a monumental engineering challenge.
Leading domestic genetic testing companies require three months to complete whole-genome sequencing, with one month dedicated to sample collection and sequencing, and the remaining two months devoted to data analysis and interpretation. In 2017, global sequencing giant Illumina launched the NovaSeq series, setting a new low for sequencing costs. This means that a massive influx of data is on the horizon. How to identify more efficient data processing solutions and accelerate data interpretation will undoubtedly be the next key topic for the industry.
VCBeat (WeChat ID: vcbeat) has compiled a list of 42 companies specializing in the niche field of genetic data analysis and interpretation, aiming to provide an industry-focused perspective on the current state of the sector.
Primarily composed of startups, with no unicorns emerging yet
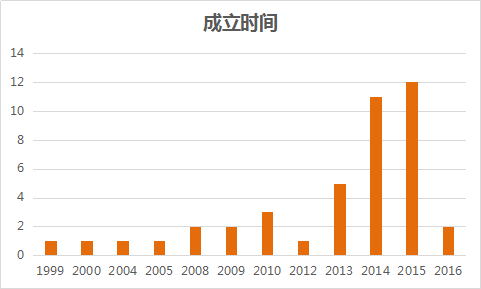
Among the 42 companies, more than half were established after 2010. Early-established enterprises, such as BGI, Berry Genomics, and Huayinkang, have highly diversified business portfolios; therefore, strictly speaking, no unicorns have yet emerged in this industry. Companies primarily engaged in data services, such as SafeGene, Huadian Cloud, and Judao Technology, as well as startups like Renhe Future that leverage interdisciplinary strengths in biotechnology and information technology as their core competitive advantage, were mostly founded around 2013. Starting in 2013, companies related to genetic data services began to flourish. This trend may also be attributed to the overall increase in the number of startups driven by the entrepreneurial boom in the entire genetic testing field during that period. In recent years, sequencing-focused companies such as Biomarker Technologies and Annoroad Gene Technology have begun expanding into the data sector, seemingly foreshadowing the major development trend in the data analysis segment.
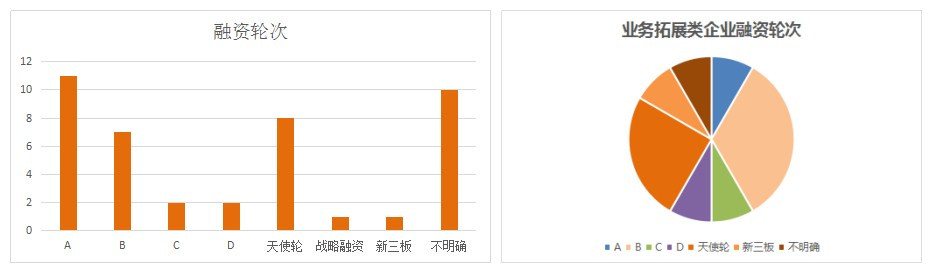
Currently, the financing rounds of these enterprises are mainly concentrated in the angel round and Series A, with relatively small scales. Among the 42 companies, 12 are engaged in business expansion, of which 7 have completed financing stages beyond Series A. Most of the players in Series B within the market entered through business expansion. These enterprises more represent a market trend rather than the maturity level of companies in the market.
Product and Services: “Cloud Services” Are the Trend
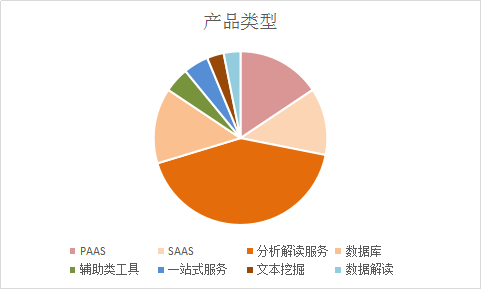
From the perspective of product distribution, traditional bioinformatics methods still dominate the mainstream, but cloud-based platforms such as PaaS and SaaS are on the rise. Undoubtedly, cloud-based data computing, transmission, and analysis will relieve users of significant hardware burdens, while also centralizing these processes in a single location to deliver a more convenient and efficient experience. This cloud-based approach is increasingly becoming the trend in data processing.
Traditional analysis is the most widely used.
Analysis software and systems are the most widely applied products in the analysis segment, representing a relatively traditional approach to bioinformatics analysis. Analysis software has a narrower scope of application and is easier to operate. In contrast, data analysis systems are more diversified, with their breadth of application varying according to their level of complexity. More comprehensive analysis systems place greater emphasis on IT architecture and analytical algorithm workflows, whereas the differences between simpler systems and standalone software are minimal. This product category has the highest concentration of enterprises, totaling 27 companies, with representative firms including Berry Genomics and Libing Technology, among others.
New and Established Players Enter the Arena: “Cloud Services” Are the Future Trend
Beyond traditional IT approaches, cloud-based computing and analytics platforms are also converging with genomic data. With lighter-weight storage solutions and more efficient computational performance, cloud platforms play a positive role in data processing.
Compared with IaaS (Infrastructure as a Service) platforms such as Alibaba Cloud, Baidu Cloud, and Huawei Cloud, PaaS platforms are more specialized and can provide more professional services tailored to the characteristics of specific domains. These platforms build cloud environments based on their respective service areas, enabling companies in niche sectors to adopt them quickly. For companies in specialized fields, the emergence of genomics-focused PaaS platforms eliminates the need to build their own infrastructure, saving significant time and costs.
PaaS platforms in the genomics field started earlier abroad, with representative companies including Seven Bridges, DNAnexus, and T
Ute Genomics, and others. In recent years, domestic bioinformatics cloud service providers have begun to enter the market. Some are early-stage companies expanding their business operations, such as BGI and Biomarker Technologies. Another category comprises startups centered on cloud services, such as Judao Technology and Huadian Cloud. The scale of genomic data generation is closely tied to sequencing costs; the establishment of these companies largely coincides with the timeline of declining sequencing costs.
In 2013, Chen Chen, a former core member of BGI’s bioinformatics team, resigned from his position as Director of the Bioinformatics Office at the Institute for Infectious Disease Control and Prevention, Chinese Center for Disease Control and Prevention (China CDC), to found Huadian Cloud, a company specializing in clinical bioinformatics services. Deployed on the Huawei Cloud platform, Huadian Cloud has accumulated more than 500 bioinformatics applications and provides bioinformatics data analysis and reporting solutions to address the lack of bioinformatics support in clinical laboratories.
Unlike Huadian Cloud, Judao Tech focuses on data security, efficiency, and ease of use to enhance data transmission and software operational efficiency. It provides cloud computing resource scheduling services for biotechnology companies that wish to leverage cloud computing but lack the expertise to do so. In 2014, a team of technologists formerly from Alibaba founded Judao Tech, a genomic big data computing service platform. The platform offers an integrated solution for the transmission, storage, analysis, computation, and application of genomic data, thereby transforming bioinformatics into cloud-based services. Additionally, it provides open interfaces to enable users to conveniently manage and manipulate data, ultimately generating reports tailored to their specific needs.
Furthermore, by leveraging data compression technologies to reduce transmission and storage time and costs, and employing distributed scheduling and execution engines to accelerate the speed and throughput of data analysis, Judao’s cloud services not only help users eliminate hardware maintenance and upgrade expenses but also lower the cost barrier for data analysis. Meanwhile, based on such a cloud platform, many complex multi-sample analysis tasks that are unaffordable or infeasible locally are no longer constrained by limited local data processing capabilities.
On one hand, cloud-service-centric startups are on the rise; on the other, midstream players and diversified enterprises within the industry chain are also actively embracing this cloud computing trend.
In April 2015, leveraging its extensive experience in next-generation sequencing (NGS) data analysis, BGI developed BGI Online, a cloud-based solution designed to address the traditional challenges of analyzing, storing, and sharing massive volumes of NGS data. With robust and reliable infrastructure and top-tier security, BGI Online provides data storage, automated analysis, data transfer, bioinformatics method development, and sharing services to institutions of various types and sizes. The platform employs state-of-the-art resource management systems to ensure precise allocation of resources during computational tasks, real-time task monitoring, and timely feedback on potential errors.
On such a platform, users can create their own analysis tools based on BGI’s open-source software. More importantly, these user-developed tools can be integrated with the public analysis tools, bioinformatics analysis tools, and other resources available on the BGI Online platform, thereby establishing a comprehensive analysis workflow that better aligns with users’ specific research needs.
In February 2016, the beta version of BGI Online was launched on Alibaba Cloud, marking the first large-scale bioinformatics analysis platform fully deployed on Alibaba Cloud. Leveraging Alibaba Cloud’s advantages in elastic storage and computing, BGI Online not only meets the data processing, storage, and transmission requirements across diverse application scenarios and models—including basic scientific research, crop breeding, and clinical applications—but also complies with industry security regulations such as the Health Insurance Portability and Accountability Act (HIPAA) through the adoption of a suite of advanced data technologies.
Meanwhile, storing and analyzing sensitive genetic data on domestically funded servers is more compliant with China’s “Measures for the Management of Human Genetic Resources.” The platform’s concise, user-friendly interface and robust security features enable doctors and researchers to delegate cumbersome tasks such as data management and hardware maintenance to BGI Online and Alibaba Cloud, allowing them to focus more intently on the scientific and clinical problems they aim to address.
This means that for research institutes, medical institutions, and small-to-medium-sized startups in the genomics industry, possessing genomic data is sufficient; there is no need to build and maintain expensive and complex computing and storage platforms. Through BGI Online, they can decode the mysteries hidden within genes. As the world’s largest genomics R&D institution, BGI has opened the door to this enigmatic field, making the genomics industry truly “within reach.”
Of course, BGI is not the only company expanding into cloud services. In July 2015, Biomarker Technologies also launched “Biomarker Cloud,” a biological big data analytics platform tailored for researchers, providing users with comprehensive bioinformatics analysis and solutions for integrating and leveraging public data.
In addition to midstream enterprises, some traditional bioinformatics companies, such as Liebing Technology and Sanger Information under Meiji Bio, are also actively migrating to the cloud.
In addition, auxiliary software such as acceleration chips and data compression tools also play a supportive role in the data processing phase. The function of these products is not to solve specific problems, but rather to enhance how effectively these problems are addressed—for instance, through more efficient computation or faster, higher-quality compression. Currently, there are few companies specializing in such auxiliary software, and given the inherent characteristics of these products, it is unlikely that dedicated enterprises will emerge in this niche.
Another category is SaaS (Software as a Service) platforms. If the aforementioned PaaS platforms provide a cloud-based environment for genomics, then SaaS offers applicable tools within this cloud environment. This is analogous to apps on a smartphone: service providers centrally deploy application software on their own servers, and customers can subscribe to the required application software services from the providers via the internet based on their actual needs. Customers pay fees according to the scope and duration of the subscribed services and access these services through the internet.
In 2015, JiYun HuiKang’s cloud analytics service was officially launched, focusing on personal whole-genome data analysis. Built as a Software-as-a-Service (SaaS) platform on Alibaba Cloud, it provides optimized services for whole-genome data that are faster and more cost-effective.
Also in 2015, Jellyfish Genomics, a company specializing in consumer-grade genetic testing, launched a health management SaaS platform on Alibaba Cloud’s infrastructure. Leveraging this precision health management SaaS system, Jellyfish Genomics developed a disease precision prevention system centered on genetic data. It creates personalized health records for each customer by collecting all health-related data, including medical history, lifestyle and dietary habits, genetic data, blood pressure, and blood glucose levels. This enables gene-guided disease prevention and enhances service quality for enterprise clients.
Qiyun Nuode has focused on backend computing services for gene sequencing companies, providing genetic testing enterprises with a one-stop solution encompassing data storage, cloud computing, analysis, result interpretation, and report generation. This enables companies in the testing segment to rapidly deliver high-quality product reports. Furthermore, Qiyun Nuode offers customized solutions and R&D outsourcing services, and can collaborate with genetic testing companies to develop required products.
In 2016, leveraging Alibaba Cloud’s advantages in batch computing and Annoroad Gene Technology’s extensive accumulation of biological samples and genomic data since its inception, the two companies jointly launched “Annoroad Cloud,” a cloud platform for big data analysis in biology. The platform aims to enable rapid analysis and secure storage of high-throughput gene sequencing data, provide integrated services for biological big data storage and management as well as biological and clinical research data analysis, thereby advancing the development of precision medicine in China.
The PaaS platform facilitates lightweight transmission and storage of genomic data, streamlining the genomic data analysis workflow. Meanwhile, the SaaS platform lowers the barrier to entry for genomic data analysis, providing convenience to users who require bioinformatics analysis but lack in-depth technical expertise. Previously, data transmission relied primarily on network transfers and physical hard drives, which were suboptimal solutions in terms of both turnaround time and cost. The emergence of PaaS and SaaS cloud platforms, augmented by high-parallelism tools such as cloud computing, has centralized data storage, transmission, analysis, and computation in the cloud. This shift liberates users from the constraints of local processing, making the entire data handling process significantly more efficient and seamless.
Interestingly, the vast majority of enterprises have chosen to partner with Alibaba Cloud as the cloud infrastructure for building their own platforms, regardless of whether they are PaaS or SaaS providers. Notable examples include BGI, Judao, Jiyun Huikang, and Annocloud. Currently, there are 18 major cloud players in the market, comprising 10 PaaS platforms and 8 SaaS platforms.
The interpretation phase is a high-altitude zone.
Traditional bioinformatics accounts for half of the landscape, while cloud platforms are also expanding. In contrast, the interpretation phase remains relatively underdeveloped. This phase can be described as the bottleneck within bottlenecks, as most diseases are polygenic disorders controlled by multiple genes. Different gene mutations, mutation sites, and mutation types all influence the final disease phenotype.
Furthermore, the genome contains a vast amount of information, yet only approximately 2% is currently well understood, with the functions of many genes remaining unclear. Moreover, as the correlations between genes and diseases have not yet been fully established, there is considerable uncertainty in the interpretation process, necessitating greater reliance on manual judgment.Even with a dream team like Kunyuan Genomics, it is difficult to address challenges at the industry level. In both scientific research and clinical practice, data interpretation remains highly limited and challenging.
Sai Fu Gene, Karmagenes, and Jiyun Huikang have proposed productizing their services by offering one-stop solutions ranging from sequencing to interpretation. These companies aim to leverage their strengths in the interpretation phase to lower the barriers to gene data analysis. Qi Yun Nuo De and Annoroad’s Annuo Cloud project have adopted similar strategies; however, these two companies focus more on all post-sequencing services. By clearly separating sequencing from data analysis and interpretation, they seek to reduce entry barriers in the genetic testing industry while further unlocking the value embedded in genomic data.
Currently, very few companies are involved in this segment, which can be described as an untapped frontier. Even when including interpretation services, semi-automated interpretation tools, and text mining, the total number of players remains below ten. Among them, only two companies offer semi-automated interpretation tools.
Labor Liberation in the Interpretation Phase: Databases Are the Foundation
Continuing from the previous discussion, due to the complexity of diseases and the fact that human understanding of the relationship between genes and diseases remains at a relatively superficial level, the data interpretation process is constrained by manual labor. In reality, semi-automated data interpretation is not difficult to implement, as certain components of expert consensus guidelines can indeed be understood and automatically scored by machines. The underlying contradiction lies in whether there exists an industry-standard database that is truly useful. Currently, public disease databases vary in their data entry standards; most of the contained data are based on studies of European and American populations, making them not fully applicable to specific ethnic groups. Furthermore, these databases lack deep integration of genomic data with phenotypic data.
Currently, all companies involved in genetic testing are engaged in a single endeavor: data collection. By gathering and integrating public or private information, which is then manually reviewed and compiled into databases or knowledge bases, these companies largely aim to correct a series of potential biases in current data interpretation by establishing sufficiently large-scale databases of the general population. This is highly valuable foundational work; countries that have rapidly advanced in the field of genomics, such as the United Kingdom and the United States, initiated such infrastructure development long ago.
In August 2015, Berry Genomics officially launched the “Shenzhou Genomic Data Cloud” project. Co-developed by Berry Genomics and Alibaba Cloud, this initiative aims to build a data cloud centered on large-scale genomic data from the Chinese population, enabling precise interpretation of individual genomic data. In September 2016, Berry Genomics announced significant interim achievements of the “Shenzhou Genomic Data Cloud” project, completing the construction of the world’s first genomic database for the Chinese population. This milestone filled the gap in international genomic databases, which previously lacked genomic data specific to the Chinese population.
In September 2016, the BGI Shenzhen National GeneBank was officially inaugurated. It is the only national gene bank in China approved for establishment. With its databases, sample repositories, living organism repositories, and planned data processing capabilities all surpassing those of the three major international genetic data centers, its comprehensive capabilities rank first globally, making it China’s first national-level genetic data center.
In addition, several midstream testing companies are preparing for the establishment of gene banks. In July 2015, Hybribio joined hands with Shenzhen People’s Hospital to initiate and launch the “Ten-Thousand-Person Cancer Genome Sequencing Project.” It is reported that more than 30 top-tier hospitals or departments across China have joined the project, and nearly 5,000 genetic tests have been completed for cancer patients or high-risk individuals.
In July 2016, “Huaxia No. 1,” the first reference genome for Asians, led by Jinan University and completed with the participation of Future Group, was published online in Nature Communications. Led by Jinan University, this study was a collaborative effort involving multiple research institutions, including the University of Southern California, the University of Washington, The Ohio State University, the National Center for Biotechnology Information (NCBI) at the U.S. National Institutes of Health, the Wuhan Institute of Biotechnology, Future Group, Columbia University, Baylor College of Medicine, and Cold Spring Harbor Laboratory. The release of “Huaxia No. 1” demonstrates that Chinese research teams have entered the global forefront in third-generation sequencing and addresses the lack of a high-resolution reference genome for disease studies in the Chinese population.
As gene sequencing becomes one of the core components of the national strategy for health and medical big data, “Huaxia No. 1” will serve as a critical foundational initiative to advance the application of clinical and research big data, significantly driving the development of genetic disease research and diagnosis in China.
In fact, nearly all midstream sequencing companies are currently engaged in the collection of genomics data. However, it will take time for any given company to build a gene database of sufficient scale. Furthermore, once data volume reaches a certain magnitude, whether enterprises choose to share their data will directly impact the widespread adoption of these databases—a challenge that may require strategic planning at the government level.
Conclusion: Databases Are the Foundation, and Cloud-Based Analysis Is Becoming the Trend
From a macro perspective, most companies are still start-ups at Series A or earlier stages, indicating that the market is still in its incubation phase. The entry of more mature enterprises such as Qiming Bio, Biomarker Technologies, and Annoroad into the market appears to signal industry trends, particularly in cloud platforms.
In terms of product distribution, there are many enterprises relying on traditional analytical methods based on analysis software and systems. However, in the face of today’s surging data volumes, these approaches struggle to achieve breakthroughs in an absolute sense. In contrast, cloud-based technologies such as PaaS and SaaS significantly alleviate the burden of data processing—both the tangible hardware load and the perceived latency-related constraints—by migrating data analytics workflows to the cloud.
However, most of these products focus on the data analysis stage. Since the majority of human diseases result from the combined effects of multiple genes, involving variable expression across multiple genes, the interpretation of such data must account for multiple genes and various factors. Therefore, this stage requires robust and accessible database support. Building on this foundation, leveraging technological means to seek automated channels that can replace manual labor—thereby saving time and costs—may well be a viable solution.
In the “13th Five-Year Plan for the Development of the Bioindustry” officially issued by the National Development and Reform Commission (NDRC), several high-profile concepts—including genetic testing, cell therapy, immunotherapy, gene editing, and prenatal screening—were explicitly highlighted. The Plan sets a development target of achieving genetic testing coverage (including pre-conception, prenatal, and newborn screening) for more than 50% of the live-born population. Leveraging the momentum from prenatal testing, genetic testing is expected to gain broader recognition and acceptance among the general public. Coupled with ongoing breakthroughs in cost control, universal access may become achievable in the future. Whether for non-invasive prenatal testing, cancer detection, or whole-genome sequencing, data analysis and interpretation are integral throughout the entire process. The widespread adoption of sequencing will inevitably drive advancements in data processing. Facing the impending deluge of data, a major “data battle” is poised to unfold.