Deep Genomics Files for IPO: Pioneering AI-Driven Genomic Medicine with $16.7M Raised to Date
Genomics is exploring how DNA variants influence specific diseases by employing deep machine learning to model the relationships between DNA and key molecules within cells, thereby enhancing the efficiency of genomic research.
In the era of applying deep learning to genomics research, Deep Genomics has opened the first window. Deep Genomics, representing “Deep Learning + Genomics,” is the product of the convergence between artificial intelligence and genomics.
The Inspiration Behind the Company Comes from Life
The origins of Deep Genomics can be traced back to 2002, whenBrendan FreyHis wife was pregnant, but during a check-up, the doctor informed them that the unborn child might have genetic defects. Although it was only a "possibility," the couple had no choice but to terminate the pregnancy.
Since then, Frey’s research focus has shifted to using deep learning to understand how genes function. The University of Toronto Professor of Electrical and Computer Engineering and a pioneer in the field of deep learning began to concentrate on genomics and medical research, aiming to integrate these areas with deep learning to develop methods that enable machines to learn and interpret the genetic code.

Brendan Frey and His Team
In 2015, Brendan Frey, Hannes Bretschneider, and others founded Deep Genomics. The company has a team of more than 20 members with advanced degrees, including experts in the fields of science, engineering, medicine, and business.
The team has published more than ten papers in Nature, Science, Cell, and Nature Biotechnology, received numerous scientific and innovation awards, and accumulated over 50 years of experience to establish an artificial intelligence system that precisely integrates genomics biology.
This team, composed of machine learning experts, genomics specialists, and medical professionals, is backed by robust technical capabilities. Since its inception, the company has been featured in prominent media outlets such as Scientific American and The Washington Post, which have likened it to “a startup bringing the power of deep learning to genomics.” Currently, the company has established collaborations with hospitals, biotechnology startups, and pharmaceutical companies, leveraging genetic data from patients with genetic disorders to test its systems.
When Genomics Meets Deep Learning
To advance genomics, it is essential to understand how gene expression is altered by genetic variants. Particularly for genes located outside protein-coding regions, DNA splicing is a critical step in their expression; its disruption can lead to certain diseases, such as cancer and neurological disorders.
A computer-based deep learning technology developed by Deep Genomics can calculate the impact of genetic variants on DNA splicing. The approach involves building a mathematical model, importing whole-genome and RNA sequences from healthy individuals to train the model to learn their DNA splicing patterns, and then validating and refining the model using molecular biology methods.
![91_EU$E~])ZC%0PP%OPIJ)S.png](https://cdn.vcbeat.top/upload/image/08/01/08/35/1515400509426772.png)
“Deep Learning” Reveals the Genetic Roots of Disease
This model can accurately classify disease-associated variants and provide insights into the impact of aberrant splicing on disease. Furthermore, it can be applied to study a variety of diseases, such as colorectal cancer, spinal muscular atrophy, and autism spectrum disorder, to determine the outcomes of common, rare, and even de novo variants.
From Technology to Product
The first deep learning method developed by Frey’s research team was designed to identify the genetic determinants of disease. The critical challenge he addressed is that there are hundreds of millions of DNA mutations (SNVs) in the human population, with approximately 3 million SNVs having a mutation frequency greater than 1%. Investigating the associations between each individual SNV and various diseases is an exceedingly daunting task.
Following the aforementioned approach of establishing mathematical models, Deep Genomics launched its first product, SPIDEX. By simply inputting sequencing data and cell type information, SPIDEX can analyze the impact of a specific variant (genomic mutation) on RNA splicing and calculate the association between that variant and disease.
SPIDEX Product Design Concept:
Use “deep learning” algorithms to derive a computational model that takes normal DNA sequences as input and infers a splicing computation model by associating DNA with DNA fragments at the splicing level in healthy human tissues.
Assuming there is a test variant with up to 300 nucleotides extending into an intron, the model can be used to calculate the extent of splicing for that variant.
![@0Q]SN@K%3UP6BKXI0~]%_I.png](https://cdn.vcbeat.top/upload/image/08/01/08/37/1515400649902366.png)
Establishment of Computational Models
Genetic variants arising from a broad spectrum of diseases and technologies can be detected and filtered using this computational model, thereby facilitating the exploration of the genetic basis of disease. The model predicts numerous aberrant splicing events caused by intronic and exonic variants, offering new opportunities to understand the genetic determinants of disease.
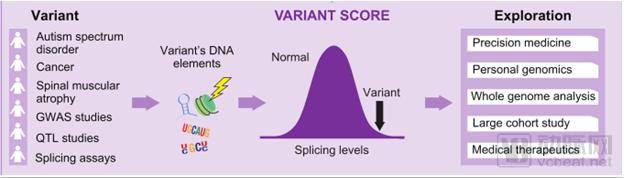
Using Models to Detect Disruptive Genetic Variants
SPIDEX can distinguish between benign and pathogenic mutations, helping researchers understand their relationships with other genetic processes. In 2016, Deep Genomics used SPIDEX to predict the effects of 328 million single nucleotide variants (SNVs), aiming to elucidate how mutations alter cellular functions and subsequently impact the human body. However, these predictions served only as an initial screening, and the correlation between pathogenic mutations and diseases had not yet been established.
If Deep Genomics’ deep learning analysis becomes sufficiently precise, the contributions of this technology will be evident: directly analyzing the association between low-frequency mutations and diseases, and accelerating genomics research and drug development.
However, Deep Genomics’ SPIDEX technology is currently limited to analyzing the relationship between RNA splicing variants caused by single nucleotide variants (SNVs) and diseases, leaving it ineffective for conditions arising from other causes. Nevertheless, the application of artificial intelligence in genomic analysis remains promising and may well become a golden key to unlocking the mysteries linking genes and diseases.
Deep Genomics’ technological achievements have been published in prestigious journals such as *Science*, *Bioinformatics*, and *Nature Biotechnology*:
Efficient in vivo correction of a splicing defect using an HDR-independent mechanism. Kemaladewi et al. Nature Medicine, July 2017.
Inference of the human polyadenylation code. Leung et al. RECOMB, April 2017.
Genome-wide characteristics of de novo mutations in autism. Yuen et al. NPJ Genome Medicine, August 2016.
Machine learning in genomic medicine: a review of computational problems and data sets. Leung et al. Proceedings of the IEEE, January 2016.
Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Alipanahi et al. Nature Biotechnology, August 2015.
The human splicing code reveals new insights into the genetic determinants of disease. Xiong et al. Science, January 2015.
Deep learning of the tissue-regulated splicing code. Leung et al. Bioinformatics, June 2014.
In September 2017, Deep Genomics announced its entry into the field of drug development. By leveraging deep learning and ultra-large neural networks to analyze genomic data, the company helps researchers identify one or more disease-causing genes, thereby facilitating the development of therapeutics targeting dysfunctional genes.
Deep Genomics believes that its technology can help pharmaceutical companies develop powerful new drugs by identifying subtle signals within vast amounts of genomic data.
Over the next two years, Deep Genomics will leverage its platform to develop novel antisense oligonucleotide therapies and conduct clinical evaluations. Currently, Deep Genomics is building a biologically accurate, AI-driven data platform to support research applications for geneticists, molecular biologists, and chemists.
Financing Status
In November 2015, Deep Genomics announced the completion of a $3.7 million seed financing round, led by Bay Area-based True Ventures, with participation from Bloomberg Beta and other investors.
In September 2017, Deep Genomics secured $13 million in Series A financing, led by Khosla Ventures and participated in by True Ventures.
As of now, Deep Genomics has raised a total of $16.7 million in funding.
Similar Companies
Atomwise, San Francisco, California

Atomwise was founded in 2012, with its core technology platform known as AtomNet—a deep convolutional neural network. By autonomously analyzing the structural features of a vast number of drug targets and small-molecule drugs, AtomNet learns the patterns governing interactions between small molecules and their targets. It then predicts the biological activity of small-molecule compounds based on these learned patterns, thereby accelerating the drug discovery and development process.
Recursion Pharmaceuticals, Salt Lake City, Utah

Recursion Pharmaceuticals, founded in 2013, has an ambitious goal: to discover treatments for 100 diseases within a decade. The company’s core technology leverages computer vision to analyze cellular images, evaluating the effects of drug administration on diseased cells by assessing over 1,000 cellular features. By integrating advanced imaging and artificial intelligence technologies, this platform enables high-throughput cellular model experiments, facilitating the screening of thousands of candidate drugs across cellular models of hundreds of diseases.
Insilico Medicine, Baltimore, Maryland

Founded in 2014, Insilico Medicine is dedicated to extending human healthspan. To this end, the company has amassed extensive multi-omics data from healthy and diseased individuals across various age groups. By leveraging machine learning for comprehensive analysis of these datasets, it identifies biomarkers associated with aging and disease, repurposes existing marketed drugs, and discovers novel anti-aging therapeutics. Another core business line involves collaborating with research institutes and pharmaceutical companies, where Insilico Medicine applies its expertise in deep neural networks and machine learning to assist in drug discovery, biomarker identification, and the development of new tools for aging research.
![7HI][4%@7{Z]US5@`_(_2CN.png](https://cdn.vcbeat.top/upload/image/08/01/08/46/1515401166854429.png)
Genetic biology, as an independent field of research, is continuously generating data. We may soon be able to perform gene sequencing using a device smaller than a mobile phone without leaving home. However, genes themselves are only part of the story: a vast amount of data is used to describe cells and tissues.
Although it is difficult for us to control these data, machine learning can help us solve these problems. Deep learning has been successfully applied in areas where humans are naturally good at, such as image recognition, text and language understanding.
However, the human brain is not inherently designed to comprehend genomes. This gap necessitates the use of “superhuman intelligence” to address genetic issues. Consequently, the application of deep learning theory is taking off in the field of gene therapy, poised to make a disruptive impact on diagnosis, patient care, pharmaceutical development, and insurance. Indeed, medicine represents the next frontier for deep learning.