Who Was the Best Employer in China's Healthcare Big Data Sector in 2018? Salary Ranges from ¥5,000 to ¥40,000
“Golden March, Silver April”: March is the peak season for job-hopping each year. This phenomenon is no exception in the healthcare industry.
According to the Spring White-Collar Job-Hopping Index survey report released by Zhaopin, March marks the peak season for job changes in spring, with nearly 80% of white-collar workers actively seeking new opportunities; among them, those born in the 1990s have the highest job-hopping rate. To clarify the trends of big data talent in the healthcare industry in 2018, VCBeat (WeChat ID: vcbeat) collected recruitment data from Boss Zhipin and Dingxiang Talent between January and March (a detailed table is attached at the end).
From these data, we have drawn the following interesting conclusions:
I. Guide to Big Data Talent Recruitment in the Healthcare Industry
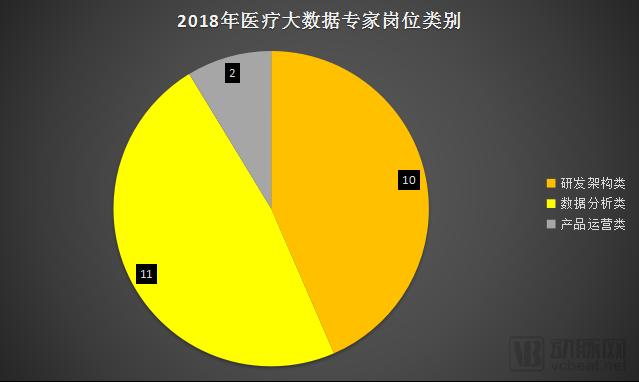
The survey reveals a strong demand among healthcare enterprises for R&D architecture professionals (such as big data development engineers and system architects) and data analysis specialists (such as data analysts and data mining engineers), followed by product operations talent. This indicates a significant shortage of high-level technical expertise in the field of medical big data.
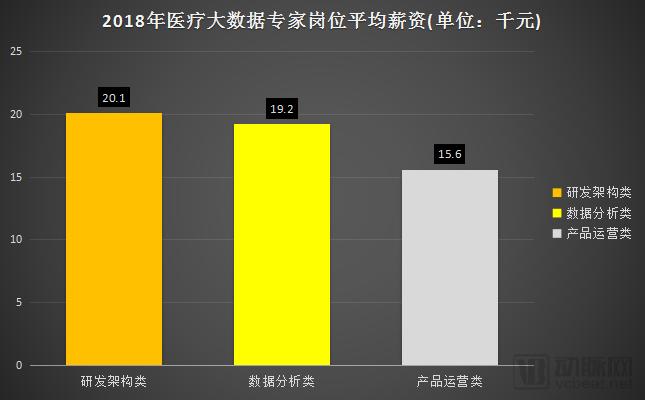
In terms of average monthly salary, R&D and architecture professionals command the highest pay, at approximately RMB 20,000. Data analytics professionals earn a comparable amount, around RMB 19,000 per month. Compensation for product operations professionals is significantly lower, at only RMB 16,000 per month.
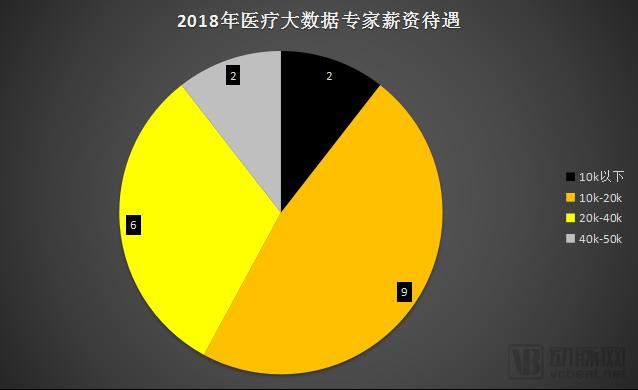
After stratifying salaries, we found that the monthly salary range of RMB 10,000 to RMB 20,000 is currently the primary compensation bracket for professionals in medical big data. This is followed by the range of RMB 20,000 to RMB 40,000 per month. According to Zhaopin’s average salary report for the winter of 2017, the average monthly salary across major cities in China was approximately RMB 8,000. Therefore, a monthly salary of RMB 20,000 can basically be considered as belonging to the middle-to-high income group.
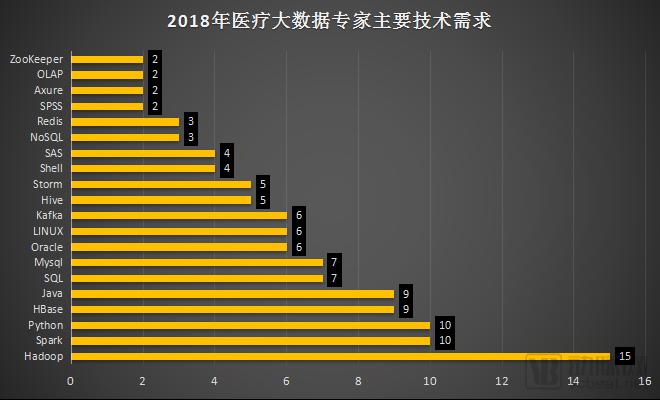
Among the companies that disclosed job information, 80% of big data positions in the healthcare sector require proficiency in five or more technical skills. As many as 15 companies explicitly listed Hadoop, the foundational distributed system architecture, as a requirement for their big data roles. Evidently, after years of development, Hadoop remains a key prerequisite—or “stepping stone”—for careers at healthcare big data firms.
Hadoop is an open-source framework for processing, storing, and analyzing massive amounts of distributed, unstructured data. It was originally created by Doug Cutting at Yahoo. Hadoop was inspired by MapReduce, a user-defined function developed by Google in the early 2000s for web indexing. It is designed to handle petabyte- and exabyte-scale data distributed across multiple parallel nodes.
At present, many companies have launched their own versions of Hadoop, while others have developed products around it. Within the Hadoop ecosystem, Cloudera is the largest and most prominent company.
Hadoop has broad applicability in the healthcare industry. For example, Cloudera collaborated with the Icahn School of Medicine at Mount Sinai to develop methods and systems for biological data analysis. Cloudera also partnered with the FDA to leverage Hadoop for detecting side effects of various drug combinations, including a collaboration with Emory University to help radiologists analyze medical images more accurately. Furthermore, Intel and NextBio have worked together to use Hadoop for processing genomic data.
In biomedical and health research, Hadoop is a reliable, efficient, and scalable distributed processing software framework. MapReduce is a programming model that can be used for parallel processing of big data; within the Hadoop framework, programs can be written and executed in various languages (such as Java, Ruby, Python, etc.) following the MapReduce programming model.
Today, Hadoop remains the most widely adopted and popular big data technology in the healthcare industry.
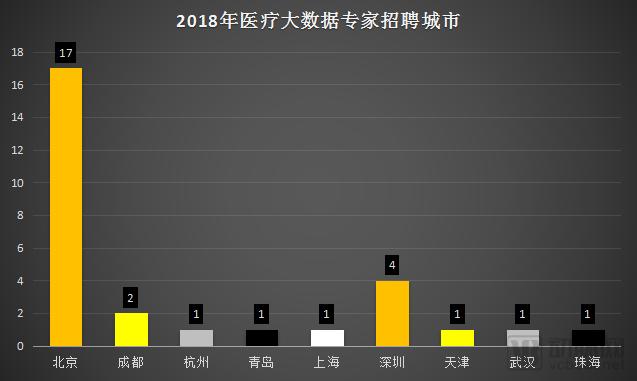
As the core hub for startups and capital in China, Beijing has undoubtedly become the center for big data talent, with as many as 17 positions located there. The city is home to leading domestic medical big data companies such as Goodwill Information Technology, LinkDoc Technology, Yidu Cloud, Huashukang, and Kangfuzi. Whether you like it or not, Beijing remains the top choice for career opportunities in medical big data.
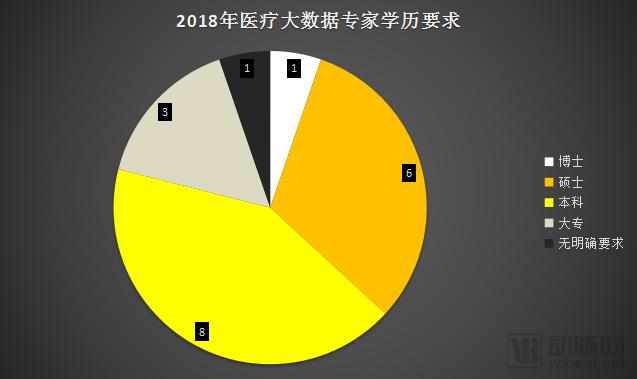
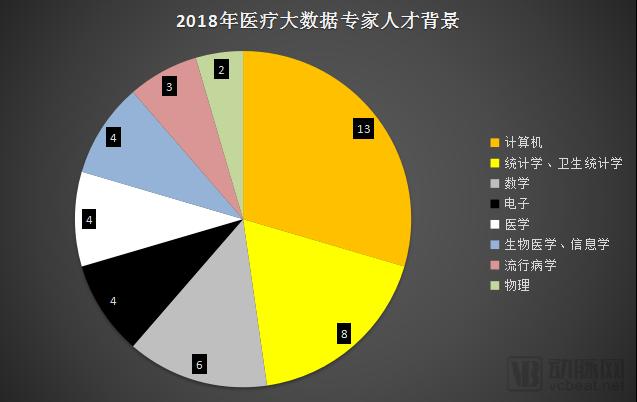
Overall, the educational requirements for big data roles in the healthcare sector are not particularly high, with a bachelor’s degree generally serving as the industry entry threshold. In contrast, professional specialization carries greater weight in talent evaluation. Candidates with computer science backgrounds are typically the primary targets for big data research and development positions, whereas those with majors in statistics or mathematics are often the preferred candidates for roles related to data analysis or processing.
In terms of demand, computer science majors are in the highest demand, while statistics and mathematics majors also see relatively high demand. Thus, logical thinking ability and data sensitivity directly determine the career ceiling for professionals in medical big data.
Among these 32 recruiting organizations, the West China Biomedical Big Data Center, Huashukang, Tuhuan Technology, WeDoctor Group, and LinkDoc Technology have the highest skill requirements, each demanding seven or more competencies. Notably, Tuhuan Technology’s job posting for a Big Data R&D Engineer lists as many as 23 specialized technical skills, earning it the moniker “Expert Terminator.”
Below are the job requirements for Big Data R&D Engineers at Tuhuan Technology:
1. Three or more years of hands-on coding experience in big data platform/product development;
2. Solid Java development experience, familiarity with Python or Scala, and proficiency in the components of the Hadoop architecture (ZooKeeper, HDFS, HBase, Hive, Pig, etc.) as well as the MapReduce process for data statistical mining;
3. Proficient in development, testing, and product feature deployment using NoSQL databases and related framework tools, including HBase, Hive, Pig, Kafka, etc.;
4. Familiar with the technical principles of NoSQL, and capable of conducting big data product practices by integrating relational database programming architectures (e.g., Redis, Memcached, MongoDB, Hadoop (HDFS/HBase), etc.);
5. Proficient in the design of RESTful API interactions for data platforms;
6. Familiar with the Linux environment and Linux shell commands; proficient in using Linux for program development and debugging;
7. Proficient in MySQL and PostgreSQL database table design;
8. Familiar with distributed computing frameworks such as YARN, Cassandra, Storm, and Spark; knowledgeable in technologies related to the development of distributed services and cluster-based services;
9. Possess strong analytical and problem-solving skills, with the ability to independently undertake system development tasks;
If the minimum monthly salary is set at RMB 20,000, Kangfuzi, Kangruide, Tongrentang Health, WeDoctor Group, Yidu Cloud, and Xinlianda emerge as the top employers in this survey. Among them, Tongrentang Health and Xinlianda offer the highest salary caps, with compensation packages for recruited positions ranging from RMB 30,000 to RMB 50,000 per month, making them the most “conscientious” employers in the medical big data sector this quarter.
II. Four Questions for Corporate HR: Why Are Big Data Talents in High Demand?
In 2016, the “Guiding Opinions of the General Office of the State Council on Promoting and Standardizing the Application and Development of Health and Medical Big Data” stated that efforts should be strengthened to build a team of composite talents proficient in both health informatics and medical care. With support from national policies, an increasing number of healthcare institutions and enterprises have joined the ranks of those developing medical big data. However, the insufficient supply of talent has remained a persistent pain point for the industry.
Big data is a systematic engineering endeavor that requires a range of professional skills to ensure the effectiveness of data analysis, including processing, integrating, and analyzing complex data, as well as helping clients fully understand the results of data analysis. To achieve this, professionals need to possess diverse skills and qualities, such as expertise in computer science/data development, analytical and modeling capabilities, innovative thinking, and communication skills. For enterprises, it is difficult to find individuals who possess all these skills; therefore, team collaboration has become the most common approach.
So, what principles do companies adhere to when screening for talent, and what are the underlying causes of the imbalance between talent supply and demand? To address these questions, VCBeat interviewed human resources executives from several well-known enterprises:
Question 1: At the current stage, is it easy to recruit engineers (analysts) specializing in healthcare big data?
Recruitment is challenging! First, there is an imbalance between market supply and demand. The explosive growth of the big data and artificial intelligence (AI) industries has led to a situation where talent cultivation and output from universities cannot keep pace with the surging market demand for AI professionals. According to LinkedIn’s “2017 Global AI Talent Report,” the number of AI-related job postings on the LinkedIn platform worldwide increased from nearly 50,000 in 2014 to over 440,000 in 2016. As of the first quarter of 2017, there were 1.95 million AI professionals globally, with the United States ranking first at over 850,000 professionals, while China ranked seventh worldwide with more than 50,000 technical experts in the field of artificial intelligence.
Second, there is a shortage of interdisciplinary talent. As big data and artificial intelligence integrate with traditional industries, the demand for interdisciplinary professionals has increased. However, the highly specialized nature of the healthcare industry results in high talent development costs. Currently, recruitment in the medical big data sector faces a mismatch: candidates either “understand algorithms but not healthcare” or “understand healthcare but not algorithms.” There is a scarcity of comprehensive interdisciplinary talent proficient in both healthcare and big data.
Third, competition for talent is intense. Domestic big data and artificial intelligence talent primarily stems from the return of overseas elites and graduates from universities and research institutes, ultimately concentrating in local tech giants such as Huawei, Baidu, Tencent, and Alibaba. Ordinary startups are at a disadvantage in this fierce battle for talent. Additionally, cross-industry competition for talent is severe; for instance, medical big data companies are less competitive than financial big data firms in attracting talent. Geographically, big data and AI professionals are predominantly concentrated in Beijing, Shanghai, Shenzhen, and Guangzhou.
It is challenging to recruit. First, there are fundamental differences in how various companies define “good” data analysts and in their business requirements. Some companies, after long-term development and consolidation, have streamlined their product lines and clarified their needs. For these organizations, data analysts are expected to possess only a solid theoretical foundation and a robust technical skill set. Such talent is primarily concentrated in foreign-owned data and consulting firms, as well as in specific departments—such as Sales Force Effectiveness (SFE) and Marketing Research—of multinational corporations (MNCs), including IMS, McKinsey, and Nielsen.
However, this talent pool has been shaped by long-term exposure to corporate culture, with the majority accustomed to the “fixed mindset” prevalent in multinational corporations. In contrast, startups often have less clearly defined business directions and require data analysts to possess strong business acumen, rather than merely proficiency in various “models.” Given these factors, technically skilled professionals tend to prefer stable jobs and exhibit low turnover rates, while those with strong business understanding often lack adequate technical expertise, creating an awkward dilemma.
At this stage, medical big data remains a relatively new field. Since big data and healthcare are two distinct domains, there is a relative scarcity of professionals with interdisciplinary expertise, which poses a challenge for the entire industry. Medical data science is an interdisciplinary field that primarily encompasses computer science, mathematics and statistics, and medicine. Given that medicine itself is a complex and broad discipline, current higher education programs rarely produce graduates who possess comprehensive expertise in all these areas. Therefore, relying solely on direct recruitment of candidates with fully mature, multidisciplinary backgrounds is impractical.
For enterprises, a more effective approach involves designing efficient organizational structures, fostering collaborative models for professional talent, and establishing platforms that promote open learning. Meanwhile, employees with strong learning agility should be cultivated to develop cross-functional transferable skills; these multidisciplinary professionals will become the company’s core competitive advantage. Furthermore, talent acquisition exhibits a siphon effect: once a critical mass of talent and a strong employer brand are established, recruitment challenges are significantly reduced.
Question 2: What are the key differences between a good engineer (analyst) and an average one?
Excellent engineers (analysts) should be versatile, multidisciplinary professionals. Vertically, they should possess in-depth knowledge of the theories, methodologies, technologies, products, and applications of big data and artificial intelligence; horizontally, they should understand the cross-disciplinary integration of big data and artificial intelligence with fields such as economics, society, management, standards, and law.
The entry barrier for data analysts is relatively high, with exceptionally demanding requirements for overall personal competence. It not only calls for a high level of professional professionalism but also demands a rigorous attitude, clear logical thinking, curiosity, and an innovative mindset. Overall, it is a “balanced paradox.”
There are both differences and commonalities between excellent engineers or analysts and the general population, with commonalities outweighing the differences. In terms of professional competence and the potential required for related work, professionals tend to be more focused and concentrated. Of course, some professionals may fall slightly short in other areas, such as teamwork or cultural integration, which necessitates greater support and training from HR departments for these specialized talents. Corporate culture also needs to take these factors into consideration.
Question 3: What factors have led to the imbalance between supply and demand for big data talent?
The primary cause of the imbalance between talent supply and demand is naturally intense market competition. As an emerging interdisciplinary field, the overall pool of seasoned professionals remains relatively small, requiring time to gradually achieve equilibrium through industry-driven development, practical experience, and training. Even outstanding specialists in individual disciplines such as computer science, statistics, and medicine are in high demand across numerous industries, resulting in a significant shortage of talent relative to demand.
In the long run, it is necessary not only for the industry to cultivate its own talent but also to encourage the development of more interdisciplinary programs within educational disciplines. Recently, the Ministry of Education has made certain disciplinary plans in the area of intelligent medical data.
Companies are gradually shifting from their previous approach of hiring for the sake of following big data trends—often bringing on staff without clear roles—to a model driven by actual business needs. Many mediocre data analysts from the past can no longer keep up. The entire data analytics profession is transitioning from “analysts” to “scientists,” with increasingly higher entry barriers. As the threshold rises, compensation packages inevitably increase.
The industry ecosystem remains immature, with a disconnect between academia, research, and industry, resulting in a gap between university training and market demands. Currently, most universities in China have yet to establish talent development systems for big data and artificial intelligence; related disciplines require further refinement, and there is an urgent need to strengthen talent reserves and build robust professional pipelines.
Question 4: What is the key to retaining this type of talent?
Setting aside compensation, for companies—particularly those in their early stages of development—to retain top data analytics talent, it is essential to enhance data literacy within certain business departments. Stakeholders should grasp fundamental theories of statistical analysis; while professional expertise is not required, they must at least be capable of engaging in smooth, business-level communication with data analysts. This approach effectively guides analysts toward the correct business direction, stimulates their interest in business operations, and supports the development and extension of the entire product line. Crucially, avoid situations where data analysts feel directionless, fail to produce tangible outcomes, and consequently experience frustration.
For specialized talent, we must consider not only compensation but also provide a superior work environment and comprehensive benefits. We should offer a competitive platform for career development, enabling these professionals to engage in the most meaningful and challenging endeavors alongside top-tier talent. Furthermore, it is crucial to foster a corporate culture that attracts talent, establish professional and mature training mechanisms, and cultivate a team atmosphere that motivates specialized professionals.
The key lies in the enterprise's development prospects and humanized management.
3. Big Data Analytics in Healthcare: Which Data Should Be Analyzed?
Medical Big Data: Data Is the Core. What Data Do Big Data Professionals Actually Analyze? To Address This Question, We Extracted Some Insights from Job Postings:
1. Responsible for the analysis and mining of healthcare data to support research in clinical practice, hospital management, health economics, and policy; responsible for building data marts and extracting features, and constructing models using statistical analysis and machine learning algorithms. (West China Biomedical Big Data Center: Data Scientist/Biostatistician)
2. Undertake the analysis of bioinformatics big data; responsible for biostatistical analysis of whole-genome, whole-exome, transcriptome, and epigenome data to uncover underlying biological insights. (The Fifth Affiliated Hospital of Sun Yat-sen University: Data Analyst/Statistician)
3. Develop statistical analysis plans based on project requirements and independently perform statistical analyses for various types of clinical studies. (Senyi Intelligence: Clinical Data Analyst)
4. Responsible for conducting research, analysis, mining, and model building for data applications and service requirements in the social security industry, and producing analytical reports; study the data application needs of human resources and social security departments across various regions, and plan, promote, and manage the construction and subsequent operation of the company’s big data application and service platform for social security. (Huashukang: Data Analyst)
5. Uncover the value of diverse medical big data, including clinical surgery records, electronic health records (EHRs), and emergency department data, and continuously deliver insights on emerging key trends through charts, presentation decks, and written reports; participate in specialized analytical projects such as studies on physician, nurse, and patient behaviors, and prediction of operative phase durations, and prepare statistical analysis reports. (Kangruide: Big Data Analyst)
As can be seen from the above information, medical big data industry analysis data at the current stage mainly falls into four categories: public health data, genomic data, clinical diagnosis and treatment data, and social security data.
IV. Reasons Behind Big Data Analytics
Given that public health data, genomic data, clinical diagnosis and treatment data, and social security data constitute the four mainstream categories, what are the underlying reasons for this dominance?
An article in The Lancet points out that the biggest obstacle to promoting evidence-based public health policies in China is the gap in understanding between researchers and policymakers.
Integrating individual datasets into big data provides the most robust evidence for evidence-based medicine, reveals nuances undetectable in small samples, and supplies public health policymakers with up-to-date evidence to guide the formulation of health policies and clinical practice.
For example, a researcher conducted a meta-analysis of the dose–response relationship between coffee consumption habits and prostate cancer. The results showed that individuals who consumed two additional cups of coffee per day had a 2.5% reduced risk of developing prostate cancer.
In addition, the interpretation of results derived from public health data mining can enhance the efficiency of epidemiological research, help public health managers gain a deeper understanding of disease etiology and outcomes, and thereby improve their ability to detect early warning signals and to track and respond to infectious disease outbreaks.
With the advancement of genetic technology, relying solely on biotechnology is no longer sufficient to fully address challenges. Biotechnology (BT) and information technology (IT) should be integrated.
The human genome comprises 23 pairs of chromosomes and contains over 3 billion base pairs, yet currently only 3% can be clinically interpreted. Raw sequence files provided by sequencing service companies cannot yield any valid information until they undergo systematic analysis and processing.
The three essential elements for effective data analysis include a high-performance computing platform, specialized analytical software, and a high-quality large-sample database. The computing platform is used to perform foundational analytical tasks on the raw sequence files generated by sequencing instruments, such as quality filtering and sequence alignment. Meanwhile, the analytical software and large-sample database are utilized for genetic interpretation and counseling. According to a survey by Ebiotrade, 69% of respondents believe that data analysis and interpretation constitute the most significant bottleneck affecting the development of the sequencing industry chain.
Currently, there are more than 100 bioinformatics companies worldwide providing gene data analysis services. Mature high-throughput sequencing technologies have generated massive amounts of data, and the bioinformatics analysis market covers data compression and storage, work platforms, data analysis software, and more.
More than 80% of studies conducted by clinicians are retrospective. To obtain patient medical record information, the following approaches are generally used: ① Data from hospital HIS and LIS systems; ② Medical record data from the medical records department; ④ Self-maintained paper medical records, Excel files, etc.; ⑤ Data from other department members.
In the past, medical records departments predominantly relied on paper-based medical records. These were later replaced by scanned text documents; however, querying them on computers remained time-consuming and labor-intensive. Physicians not only had to review each record individually but also manually extract and compile specific information from each one. Occasionally, data retrieved from the Information Technology Department suffered from irregular formatting or inconsistencies, necessitating re-verification and resulting in secondary queries. This cumbersome workflow caused physicians to expend considerable time organizing medical records.
Big data analytics enables enterprises to structure large volumes of de-identified medical records, transforming electronic health record (EHR) information into research-grade data. This not only supports clinical research but also helps physicians build precise diagnostic and therapeutic models to provide treatment recommendations.
In April 2015, the General Office of the Ministry of Human Resources and Social Security issued the “Notice on Comprehensively Promoting Intelligent Monitoring of Medical Services under Basic Medical Insurance.”
The Notice states: Standardize the development of monitoring systems. The Ministry will organize the formulation of basic monitoring indicators, monitoring rules, and national (industry) standards, and will develop and upgrade intelligent monitoring systems to serve as the foundational infrastructure for medical service monitoring activities across all regions. Regions that have not yet established intelligent monitoring systems should, in principle, build their systems based on the unified software developed by the Ministry. Regions that have already implemented systems based on the Ministry’s intelligent monitoring system or previously developed their own systems should further refine and improve them in alignment with the Ministry’s basic monitoring indicators, monitoring rules, and the upgraded version of the Ministry’s intelligent monitoring system.
The introduction of this policy marks the official arrival of the era of medical insurance cost containment in China.
Healthcare Insurance Cost Control: A Key Component in Curbing the Growth of China’s Medical Insurance ExpendituresIn China, healthcare insurance cost control companies such as Shulian Yikang leverage big data anti-fraud models to conduct in-depth mining of administrative data, data extracted from Hospital Information Systems (HIS), and reimbursement records. These solutions enable the identification of hidden fraudulent activities, medical waste, and excessive treatment. Furthermore, they facilitate Diagnosis-Related Group (DRG) classification, supporting performance evaluation and cost analysis.
Appendix